 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do Vision Transformers Learn? A Visual Exploration
Dec 13, 2022



Vision transformers (ViTs) are quickly becoming the de-facto architecture for computer vision, yet we understand very little about why they work and what they learn. While existing studies visually analyze the mechanisms of convolutional neural networks, an analogous exploration of ViTs remains challenging. In this paper, we first address the obstacles to performing visualizations on ViTs. Assisted by these solutions, we observe that neurons in ViTs trained with language model supervision (e.g., CLIP) are activated by semantic concepts rather than visual features. We also explore the underlying differences between ViTs and CNNs, and we find that transformers detect image background features, just like their convolutional counterparts, but their predictions depend far less on high-frequency information. On the other hand, both architecture types behave similarly in the way features progress from abstract patterns in early layers to concrete objects in late layers. In addition, we show that ViTs maintain spatial information in all layers except the final layer. In contrast to previous works, we show that the last layer most likely discards the spatial information and behaves as a learned global pooling operation. Finally, we conduct large-scale visualizations on a wide range of ViT variants, including DeiT, CoaT, ConViT, PiT, Swin, and Twin, to validate the effectiveness of our method.
A Deep Dive into Dataset Imbalance and Bias in Face Identification
Mar 15, 2022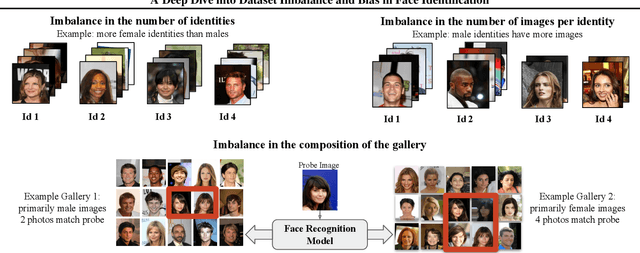



As the deployment of automated face recognition (FR) systems proliferates, bias in these systems is not just an academic question, but a matter of public concern. Media portrayals often center imbalance as the main source of bias, i.e., that FR models perform worse on images of non-white people or women because these demographic groups are underrepresented in training data. Recent academic research paints a more nuanced picture of this relationship. However, previous studies of data imbalance in FR have focused exclusively on the face verification setting, while the face identification setting has been largely ignored, despite being deployed in sensitive applications such as law enforcement. This is an unfortunate omission, as 'imbalance' is a more complex matter in identification; imbalance may arise in not only the training data, but also the testing data, and furthermore may affect the proportion of identities belonging to each demographic group or the number of images belonging to each identity. In this work, we address this gap in the research by thoroughly exploring the effects of each kind of imbalance possible in face identification, and discuss other factors which may impact bias in this setting.
Plug-In Inversion: Model-Agnostic Inversion for Vision with Data Augmentations
Jan 31, 2022



Existing techniques for model inversion typically rely on hard-to-tune regularizers, such as total variation or feature regularization, which must be individually calibrated for each network in order to produce adequate images. In this work, we introduce Plug-In Inversion, which relies on a simple set of augmentations and does not require excessive hyper-parameter tuning. Under our proposed augmentation-based scheme, the same set of augmentation hyper-parameters can be used for inverting a wide range of image classification models, regardless of input dimensions or the architecture. We illustrate the practicality of our approach by inverting Vision Transformers (ViTs) and Multi-Layer Perceptrons (MLPs) trained on the ImageNet dataset, tasks which to the best of our knowledge have not been successfully accomplished by any previous works.
Decepticons: Corrupted Transformers Breach Privacy in Federated Learning for Language Models
Jan 29, 2022



A central tenet of Federated learning (FL), which trains models without centralizing user data, is privacy. However, previous work has shown that the gradient updates used in FL can leak user information. While the most industrial uses of FL are for text applications (e.g. keystroke prediction), nearly all attacks on FL privacy have focused on simple image classifiers. We propose a novel attack that reveals private user text by deploying malicious parameter vectors, and which succeeds even with mini-batches, multiple users, and long sequences. Unlike previous attacks on FL, the attack exploits characteristics of both the Transformer architecture and the token embedding, separately extracting tokens and positional embeddings to retrieve high-fidelity text. This work suggests that FL on text, which has historically been resistant to privacy attacks, is far more vulnerable than previously thought.
Ensemble Distillation for Structured Prediction: Calibrated, Accurate, Fast---Choose Three
Oct 13, 2020



Modern neural networks do not always produce well-calibrated predictions, even when trained with a proper scoring function such as cross-entropy. In classification settings, simple methods such as isotonic regression or temperature scaling may be used in conjunction with a held-out dataset to calibrate model outputs. However, extending these methods to structured prediction is not always straightforward or effective; furthermore, a held-out calibration set may not always be available. In this paper, we study ensemble distillation as a general framework for producing well-calibrated structured prediction models while avoiding the prohibitive inference-time cost of ensembles. We validate this framework on two tasks: named-entity recognition and machine translation. We find that, across both tasks, ensemble distillation produces models which retain much of, and occasionally improve upon, the performance and calibration benefits of ensembles, while only requiring a single model during test-time.
Unraveling Meta-Learning: Understanding Feature Representations for Few-Shot Tasks
Mar 21, 2020



Meta-learning algorithms produce feature extractors which achieve state-of-the-art performance on few-shot classification. While the literature is rich with meta-learning methods, little is known about why the resulting feature extractors perform so well. We develop a better understanding of the underlying mechanics of meta-learning and the difference between models trained using meta-learning and models which are trained classically. In doing so, we develop several hypotheses for why meta-learned models perform better. In addition to visualizations, we design several regularizers inspired by our hypotheses which improve performance on few-shot classification.
WITCHcraft: Efficient PGD attacks with random step size
Nov 18, 2019



State-of-the-art adversarial attacks on neural networks use expensive iterative methods and numerous random restarts from different initial points. Iterative FGSM-based methods without restarts trade off performance for computational efficiency because they do not adequately explore the image space and are highly sensitive to the choice of step size. We propose a variant of Projected Gradient Descent (PGD) that uses a random step size to improve performance without resorting to expensive random restarts. Our method, Wide Iterative Stochastic crafting (WITCHcraft), achieves results superior to the classical PGD attack on the CIFAR-10 and MNIST data sets but without additional computational cost. This simple modification of PGD makes crafting attacks more economical, which is important in situations like adversarial training where attacks need to be crafted in real time.