 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKEPO: Knowledge-Enhanced Preference Optimization for Reinforcement Learning with Reasoning
Jan 30, 2026Reinforcement learning (RL) has emerged as a promising paradigm for inducing explicit reasoning behaviors in large language and vision-language models. However, reasoning-oriented RL post-training remains fundamentally challenging due to sparse trajectory-level rewards, leading to ambiguous credit assignment and severe exploration failures that can trap the policy in a ``learning cliff.'' Recent on-policy distillation methods introduce dense teacher supervision to stabilize optimization, but apply it uniformly across all generated trajectories. We argue that such uniform distillation is ill-suited for reasoning-intensive tasks, as low-quality on-policy trajectories often originate from early logical errors, and distillation under flawed contexts injects noisy and misaligned gradients. To address these challenges, we propose Knowledge-Enhanced Preference Optimization (KEPO), a unified post-training framework that integrates: (i) a quality-gated on-policy distillation objective that selectively applies dense teacher guidance only to high-quality trajectories, and (ii) a knowledge-enhanced exploration strategy that leverages hints learned from a teacher model to rejectively sample reward-positive on-policy trajectories for RL, thereby mitigating exploration collapse. Evaluated on a challenging medical visual question answering benchmark under single-source generalization, KEPO demonstrates improved training stability, more coherent reasoning behaviors, and superior out-of-distribution performance over reinforcement learning and on-policy distillation baselines.
HY-Motion 1.0: Scaling Flow Matching Models for Text-To-Motion Generation
Dec 29, 2025We present HY-Motion 1.0, a series of state-of-the-art, large-scale, motion generation models capable of generating 3D human motions from textual descriptions. HY-Motion 1.0 represents the first successful attempt to scale up Diffusion Transformer (DiT)-based flow matching models to the billion-parameter scale within the motion generation domain, delivering instruction-following capabilities that significantly outperform current open-source benchmarks. Uniquely, we introduce a comprehensive, full-stage training paradigm -- including large-scale pretraining on over 3,000 hours of motion data, high-quality fine-tuning on 400 hours of curated data, and reinforcement learning from both human feedback and reward models -- to ensure precise alignment with the text instruction and high motion quality. This framework is supported by our meticulous data processing pipeline, which performs rigorous motion cleaning and captioning. Consequently, our model achieves the most extensive coverage, spanning over 200 motion categories across 6 major classes. We release HY-Motion 1.0 to the open-source community to foster future research and accelerate the transition of 3D human motion generation models towards commercial maturity.
RL Is a Hammer and LLMs Are Nails: A Simple Reinforcement Learning Recipe for Strong Prompt Injection
Oct 06, 2025Prompt injection poses a serious threat to the reliability and safety of LLM agents. Recent defenses against prompt injection, such as Instruction Hierarchy and SecAlign, have shown notable robustness against static attacks. However, to more thoroughly evaluate the robustness of these defenses, it is arguably necessary to employ strong attacks such as automated red-teaming. To this end, we introduce RL-Hammer, a simple recipe for training attacker models that automatically learn to perform strong prompt injections and jailbreaks via reinforcement learning. RL-Hammer requires no warm-up data and can be trained entirely from scratch. To achieve high ASRs against industrial-level models with defenses, we propose a set of practical techniques that enable highly effective, universal attacks. Using this pipeline, RL-Hammer reaches a 98% ASR against GPT-4o and a $72\%$ ASR against GPT-5 with the Instruction Hierarchy defense. We further discuss the challenge of achieving high diversity in attacks, highlighting how attacker models tend to reward-hack diversity objectives. Finally, we show that RL-Hammer can evade multiple prompt injection detectors. We hope our work advances automatic red-teaming and motivates the development of stronger, more principled defenses. Code is available at https://github.com/facebookresearch/rl-injector.
Quantifying Cross-Modality Memorization in Vision-Language Models
Jun 05, 2025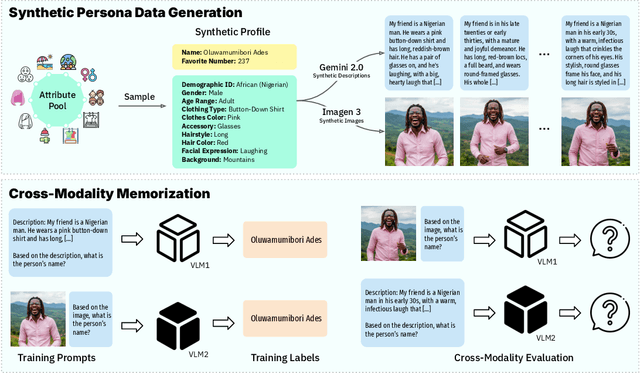
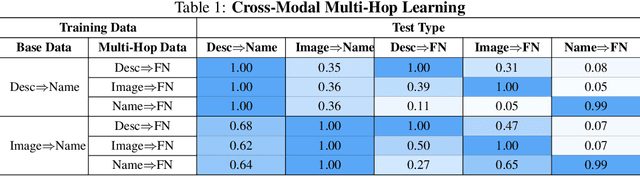
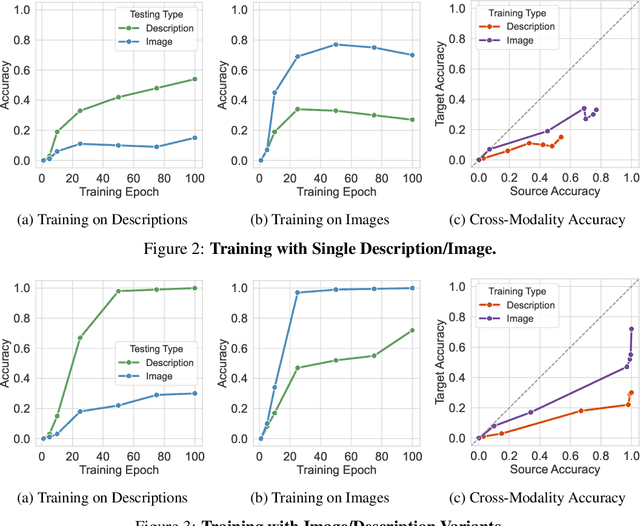
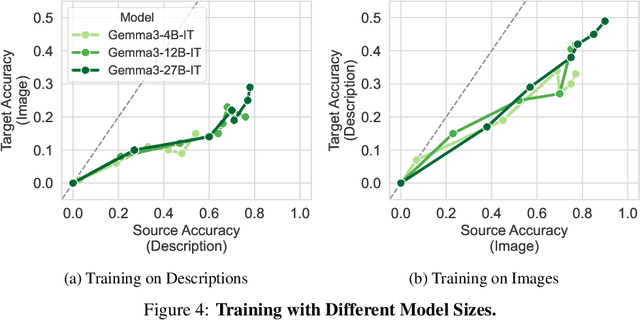
Understanding what and how neural networks memorize during training is crucial, both from the perspective of unintentional memorization of potentially sensitive information and from the standpoint of effective knowledge acquisition for real-world, knowledge-intensive tasks. While previous studies primarily investigate memorization within a single modality, such as text memorization in large language models or image memorization in diffusion models, unified multimodal models are becoming increasingly prevalent in practical applications. In this work, we focus on the unique characteristics of cross-modality memorization and conduct a systematic study centered on vision-language models. To facilitate controlled experiments, we first introduce a synthetic persona dataset comprising diverse synthetic person images and textual descriptions. We quantify factual knowledge memorization and cross-modal transferability by training models on a single modality and evaluating their performance in the other. Our results reveal that facts learned in one modality transfer to the other, but a significant gap exists between recalling information in the source and target modalities. Furthermore, we observe that this gap exists across various scenarios, including more capable models, machine unlearning, and the multi-hop case. At the end, we propose a baseline method to mitigate this challenge. We hope our study can inspire future research on developing more robust multimodal learning techniques to enhance cross-modal transferability.
A Fictional Q&A Dataset for Studying Memorization and Knowledge Acquisition
Jun 05, 2025When language models are trained on textual data, they acquire both knowledge about the structure of language as well as knowledge of facts about the world. At inference time, their knowledge of facts can be leveraged to solve interesting problems and perform useful knowledge work for users. It is well known that language models can verbatim memorize long sequences from their training data. However, it is much less well understood how language models memorize facts seen during training. In this work, we propose a new dataset to specifically empower researchers to study the dual processes of fact memorization and verbatim sequence memorization. The dataset consists of synthetically-generated, webtext-like documents about fictional events, as well as question-answer pairs about the events. We conduct training experiments showing how synthetic data about fictional events can be effective in teasing apart different forms of memorization. We also document the challenges in effectively building realistic, fictional synthetic data.
Analysis of Attention in Video Diffusion Transformers
Apr 14, 2025We conduct an in-depth analysis of attention in video diffusion transformers (VDiTs) and report a number of novel findings. We identify three key properties of attention in VDiTs: Structure, Sparsity, and Sinks. Structure: We observe that attention patterns across different VDiTs exhibit similar structure across different prompts, and that we can make use of the similarity of attention patterns to unlock video editing via self-attention map transfer. Sparse: We study attention sparsity in VDiTs, finding that proposed sparsity methods do not work for all VDiTs, because some layers that are seemingly sparse cannot be sparsified. Sinks: We make the first study of attention sinks in VDiTs, comparing and contrasting them to attention sinks in language models. We propose a number of future directions that can make use of our insights to improve the efficiency-quality Pareto frontier for VDiTs.
Stable-SCore: A Stable Registration-based Framework for 3D Shape Correspondence
Mar 27, 2025



Establishing character shape correspondence is a critical and fundamental task in computer vision and graphics, with diverse applications including re-topology, attribute transfer, and shape interpolation. Current dominant functional map methods, while effective in controlled scenarios, struggle in real situations with more complex challenges such as non-isometric shape discrepancies. In response, we revisit registration-for-correspondence methods and tap their potential for more stable shape correspondence estimation. To overcome their common issues including unstable deformations and the necessity for careful pre-alignment or high-quality initial 3D correspondences, we introduce Stable-SCore: A Stable Registration-based Framework for 3D Shape Correspondence. We first re-purpose a foundation model for 2D character correspondence that ensures reliable and stable 2D mappings. Crucially, we propose a novel Semantic Flow Guided Registration approach that leverages 2D correspondence to guide mesh deformations. Our framework significantly surpasses existing methods in challenging scenarios, and brings possibilities for a wide array of real applications, as demonstrated in our results.
Democratizing AI: Open-source Scalable LLM Training on GPU-based Supercomputers
Feb 12, 2025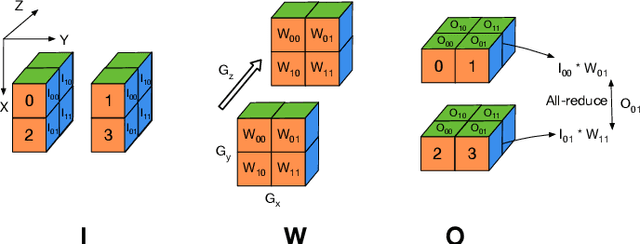
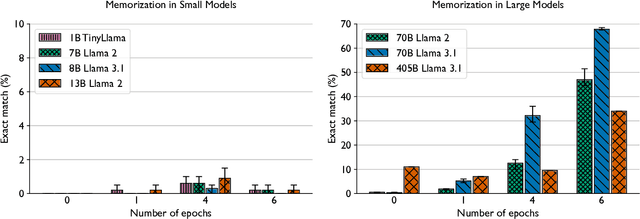
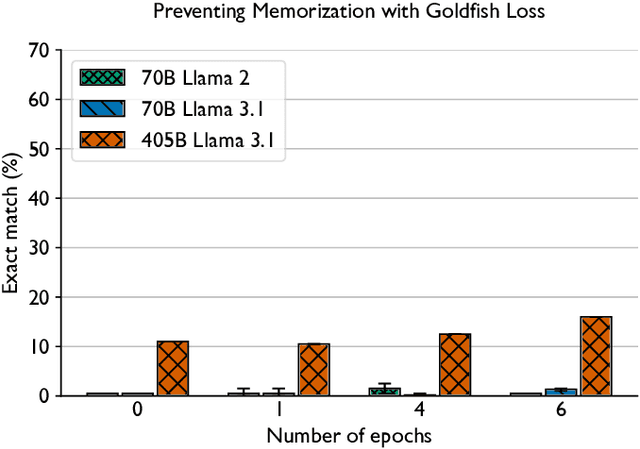
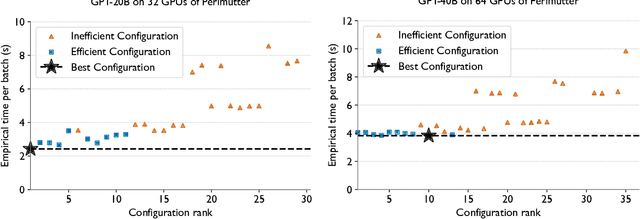
Training and fine-tuning large language models (LLMs) with hundreds of billions to trillions of parameters requires tens of thousands of GPUs, and a highly scalable software stack. In this work, we present a novel four-dimensional hybrid parallel algorithm implemented in a highly scalable, portable, open-source framework called AxoNN. We describe several performance optimizations in AxoNN to improve matrix multiply kernel performance, overlap non-blocking collectives with computation, and performance modeling to choose performance optimal configurations. These have resulted in unprecedented scaling and peak flop/s (bf16) for training of GPT-style transformer models on Perlmutter (620.1 Petaflop/s), Frontier (1.381 Exaflop/s) and Alps (1.423 Exaflop/s). While the abilities of LLMs improve with the number of trainable parameters, so do privacy and copyright risks caused by memorization of training data, which can cause disclosure of sensitive or private information at inference time. We highlight this side effect of scale through experiments that explore "catastrophic memorization", where models are sufficiently large to memorize training data in a single pass, and present an approach to prevent it. As part of this study, we demonstrate fine-tuning of a 405-billion parameter LLM using AxoNN on Frontier.
EditScout: Locating Forged Regions from Diffusion-based Edited Images with Multimodal LLM
Dec 05, 2024



Image editing technologies are tools used to transform, adjust, remove, or otherwise alter images. Recent research has significantly improved the capabilities of image editing tools, enabling the creation of photorealistic and semantically informed forged regions that are nearly indistinguishable from authentic imagery, presenting new challenges in digital forensics and media credibility. While current image forensic techniques are adept at localizing forged regions produced by traditional image manipulation methods, current capabilities struggle to localize regions created by diffusion-based techniques. To bridge this gap, we present a novel framework that integrates a multimodal Large Language Model (LLM) for enhanced reasoning capabilities to localize tampered regions in images produced by diffusion model-based editing methods. By leveraging the contextual and semantic strengths of LLMs, our framework achieves promising results on MagicBrush, AutoSplice, and PerfBrush (novel diffusion-based dataset) datasets, outperforming previous approaches in mIoU and F1-score metrics. Notably, our method excels on the PerfBrush dataset, a self-constructed test set featuring previously unseen types of edits. Here, where traditional methods typically falter, achieving markedly low scores, our approach demonstrates promising performance.
Efficient Vision-Language Models by Summarizing Visual Tokens into Compact Registers
Oct 17, 2024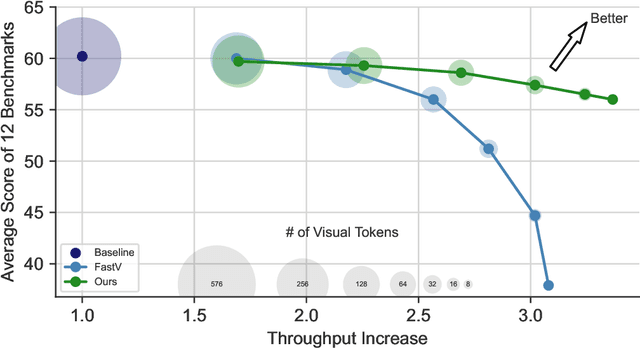
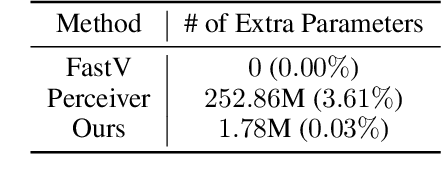
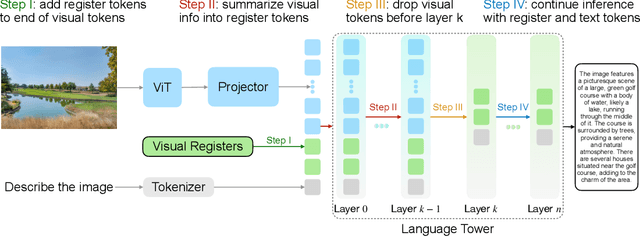
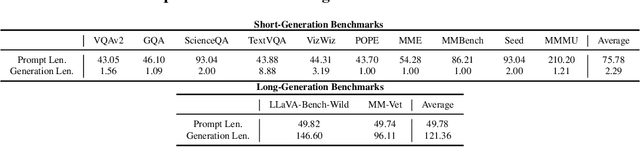
Recent advancements in vision-language models (VLMs) have expanded their potential for real-world applications, enabling these models to perform complex reasoning on images. In the widely used fully autoregressive transformer-based models like LLaVA, projected visual tokens are prepended to textual tokens. Oftentimes, visual tokens are significantly more than prompt tokens, resulting in increased computational overhead during both training and inference. In this paper, we propose Visual Compact Token Registers (Victor), a method that reduces the number of visual tokens by summarizing them into a smaller set of register tokens. Victor adds a few learnable register tokens after the visual tokens and summarizes the visual information into these registers using the first few layers in the language tower of VLMs. After these few layers, all visual tokens are discarded, significantly improving computational efficiency for both training and inference. Notably, our method is easy to implement and requires a small number of new trainable parameters with minimal impact on model performance. In our experiment, with merely 8 visual registers--about 1% of the original tokens--Victor shows less than a 4% accuracy drop while reducing the total training time by 43% and boosting the inference throughput by 3.3X.