 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Token Prediction via Self-Distillation
Feb 05, 2026Existing techniques for accelerating language model inference, such as speculative decoding, require training auxiliary speculator models and building and deploying complex inference pipelines. We consider a new approach for converting a pretrained autoregressive language model from a slow single next token prediction model into a fast standalone multi-token prediction model using a simple online distillation objective. The final model retains the exact same implementation as the pretrained initial checkpoint and is deployable without the addition of any auxiliary verifier or other specialized inference code. On GSM8K, our method produces models that can decode more than $3\times$ faster on average at $<5\%$ drop in accuracy relative to single token decoding performance.
Democratizing AI: Open-source Scalable LLM Training on GPU-based Supercomputers
Feb 12, 2025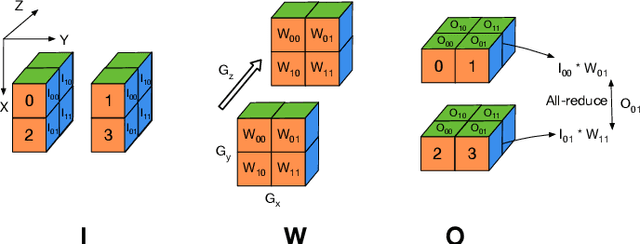
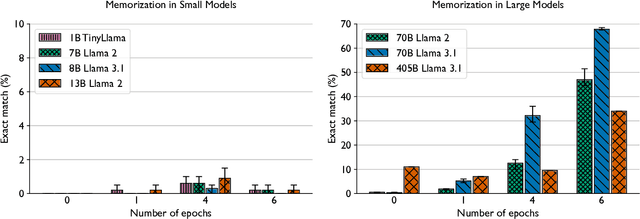
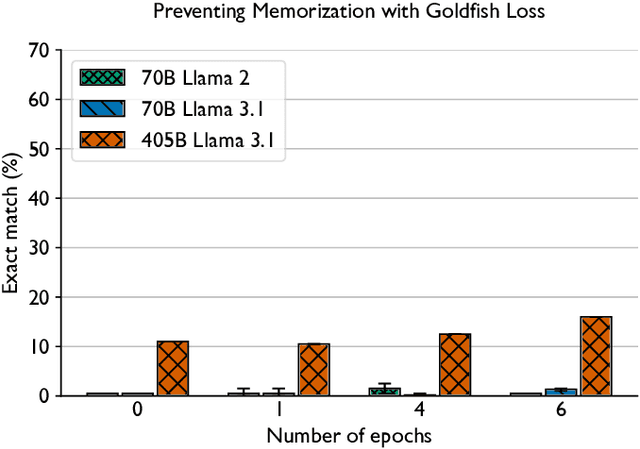
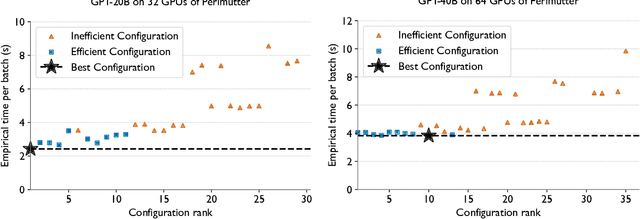
Training and fine-tuning large language models (LLMs) with hundreds of billions to trillions of parameters requires tens of thousands of GPUs, and a highly scalable software stack. In this work, we present a novel four-dimensional hybrid parallel algorithm implemented in a highly scalable, portable, open-source framework called AxoNN. We describe several performance optimizations in AxoNN to improve matrix multiply kernel performance, overlap non-blocking collectives with computation, and performance modeling to choose performance optimal configurations. These have resulted in unprecedented scaling and peak flop/s (bf16) for training of GPT-style transformer models on Perlmutter (620.1 Petaflop/s), Frontier (1.381 Exaflop/s) and Alps (1.423 Exaflop/s). While the abilities of LLMs improve with the number of trainable parameters, so do privacy and copyright risks caused by memorization of training data, which can cause disclosure of sensitive or private information at inference time. We highlight this side effect of scale through experiments that explore "catastrophic memorization", where models are sufficiently large to memorize training data in a single pass, and present an approach to prevent it. As part of this study, we demonstrate fine-tuning of a 405-billion parameter LLM using AxoNN on Frontier.
Be like a Goldfish, Don't Memorize! Mitigating Memorization in Generative LLMs
Jun 14, 2024



Large language models can memorize and repeat their training data, causing privacy and copyright risks. To mitigate memorization, we introduce a subtle modification to the next-token training objective that we call the goldfish loss. During training, a randomly sampled subset of tokens are excluded from the loss computation. These dropped tokens are not memorized by the model, which prevents verbatim reproduction of a complete chain of tokens from the training set. We run extensive experiments training billion-scale Llama-2 models, both pre-trained and trained from scratch, and demonstrate significant reductions in extractable memorization with little to no impact on downstream benchmarks.
Spotting LLMs With Binoculars: Zero-Shot Detection of Machine-Generated Text
Jan 22, 2024



Detecting text generated by modern large language models is thought to be hard, as both LLMs and humans can exhibit a wide range of complex behaviors. However, we find that a score based on contrasting two closely related language models is highly accurate at separating human-generated and machine-generated text. Based on this mechanism, we propose a novel LLM detector that only requires simple calculations using a pair of pre-trained LLMs. The method, called Binoculars, achieves state-of-the-art accuracy without any training data. It is capable of spotting machine text from a range of modern LLMs without any model-specific modifications. We comprehensively evaluate Binoculars on a number of text sources and in varied situations. Over a wide range of document types, Binoculars detects over 90% of generated samples from ChatGPT (and other LLMs) at a false positive rate of 0.01%, despite not being trained on any ChatGPT data.