 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Dense to Dynamic: Token-Difficulty Driven MoEfication of Pre-Trained LLMs
Feb 17, 2025Training large language models (LLMs) for different inference constraints is computationally expensive, limiting control over efficiency-accuracy trade-offs. Moreover, once trained, these models typically process tokens uniformly, regardless of their complexity, leading to static and inflexible behavior. In this paper, we introduce a post-training optimization framework, DynaMoE, that adapts a pre-trained dense LLM to a token-difficulty-driven Mixture-of-Experts model with minimal fine-tuning cost. This adaptation makes the model dynamic, with sensitivity control to customize the balance between efficiency and accuracy. DynaMoE features a token-difficulty-aware router that predicts the difficulty of tokens and directs them to the appropriate sub-networks or experts, enabling larger experts to handle more complex tokens and smaller experts to process simpler ones. Our experiments demonstrate that DynaMoE can generate a range of adaptive model variants of the existing trained LLM with a single fine-tuning step, utilizing only $10B$ tokens, a minimal cost compared to the base model's training. Each variant offers distinct trade-offs between accuracy and performance. Compared to the baseline post-training optimization framework, Flextron, our method achieves similar aggregated accuracy across downstream tasks, despite using only $\frac{1}{9}\text{th}$ of their fine-tuning cost.
M2R2: Mixture of Multi-Rate Residuals for Efficient Transformer Inference
Feb 04, 2025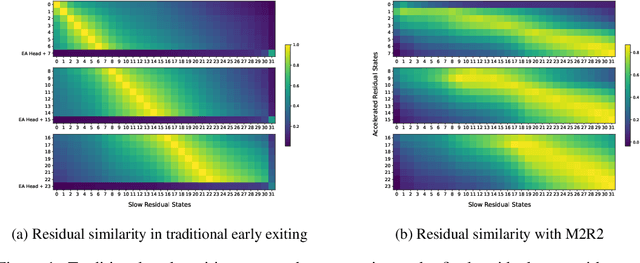
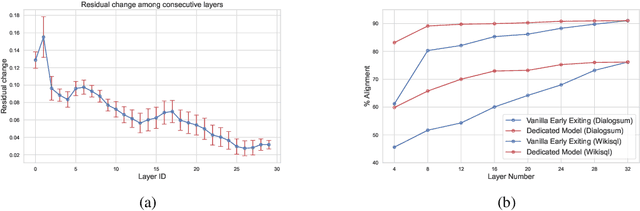
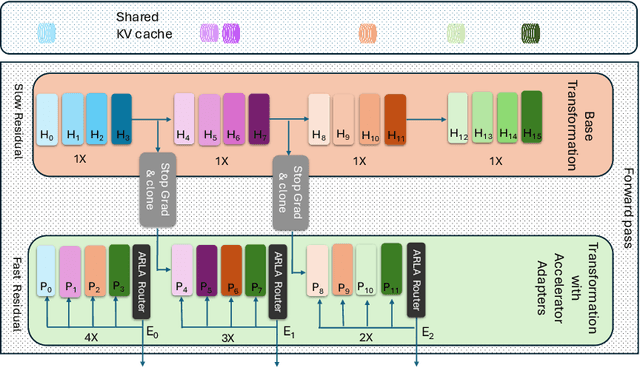
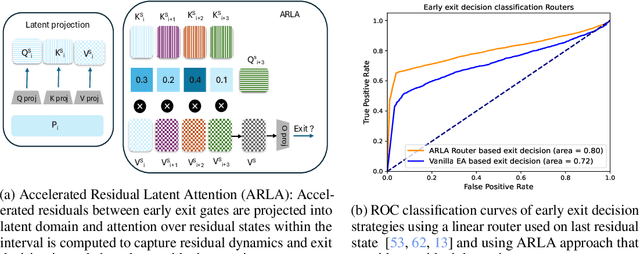
Residual transformations enhance the representational depth and expressive power of large language models (LLMs). However, applying static residual transformations across all tokens in auto-regressive generation leads to a suboptimal trade-off between inference efficiency and generation fidelity. Existing methods, including Early Exiting, Skip Decoding, and Mixture-of-Depth address this by modulating the residual transformation based on token-level complexity. Nevertheless, these approaches predominantly consider the distance traversed by tokens through the model layers, neglecting the underlying velocity of residual evolution. We introduce Mixture of Multi-rate Residuals (M2R2), a framework that dynamically modulates residual velocity to improve early alignment, enhancing inference efficiency. Evaluations on reasoning oriented tasks such as Koala, Self-Instruct, WizardLM, and MT-Bench show M2R2 surpasses state-of-the-art distance-based strategies, balancing generation quality and speedup. In self-speculative decoding setup, M2R2 achieves up to 2.8x speedups on MT-Bench, outperforming methods like 2-model speculative decoding, Medusa, LookAhead Decoding, and DEED. In Mixture-of-Experts (MoE) architectures, integrating early residual alignment with ahead-of-time expert loading into high-bandwidth memory (HBM) accelerates decoding, reduces expert-switching bottlenecks, and achieves a 2.9x speedup, making it highly effective in resource-constrained environments.
Efficient Vision-Language Models by Summarizing Visual Tokens into Compact Registers
Oct 17, 2024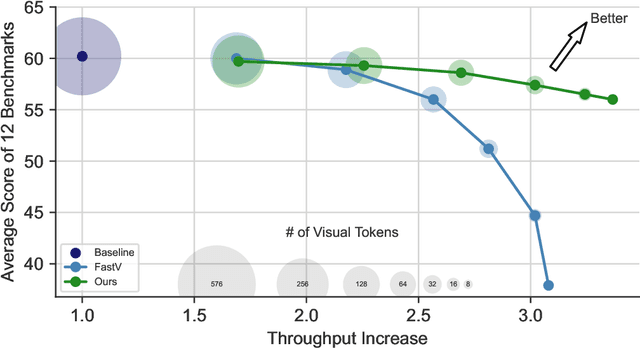
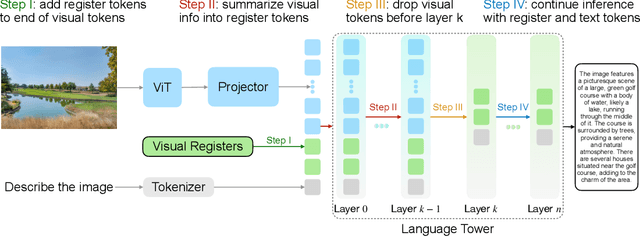
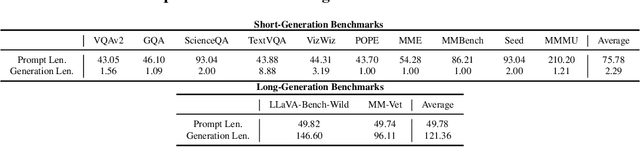
Recent advancements in vision-language models (VLMs) have expanded their potential for real-world applications, enabling these models to perform complex reasoning on images. In the widely used fully autoregressive transformer-based models like LLaVA, projected visual tokens are prepended to textual tokens. Oftentimes, visual tokens are significantly more than prompt tokens, resulting in increased computational overhead during both training and inference. In this paper, we propose Visual Compact Token Registers (Victor), a method that reduces the number of visual tokens by summarizing them into a smaller set of register tokens. Victor adds a few learnable register tokens after the visual tokens and summarizes the visual information into these registers using the first few layers in the language tower of VLMs. After these few layers, all visual tokens are discarded, significantly improving computational efficiency for both training and inference. Notably, our method is easy to implement and requires a small number of new trainable parameters with minimal impact on model performance. In our experiment, with merely 8 visual registers--about 1% of the original tokens--Victor shows less than a 4% accuracy drop while reducing the total training time by 43% and boosting the inference throughput by 3.3X.
CtrlSynth: Controllable Image Text Synthesis for Data-Efficient Multimodal Learning
Oct 15, 2024Pretraining robust vision or multimodal foundation models (e.g., CLIP) relies on large-scale datasets that may be noisy, potentially misaligned, and have long-tail distributions. Previous works have shown promising results in augmenting datasets by generating synthetic samples. However, they only support domain-specific ad hoc use cases (e.g., either image or text only, but not both), and are limited in data diversity due to a lack of fine-grained control over the synthesis process. In this paper, we design a \emph{controllable} image-text synthesis pipeline, CtrlSynth, for data-efficient and robust multimodal learning. The key idea is to decompose the visual semantics of an image into basic elements, apply user-specified control policies (e.g., remove, add, or replace operations), and recompose them to synthesize images or texts. The decompose and recompose feature in CtrlSynth allows users to control data synthesis in a fine-grained manner by defining customized control policies to manipulate the basic elements. CtrlSynth leverages the capabilities of pretrained foundation models such as large language models or diffusion models to reason and recompose basic elements such that synthetic samples are natural and composed in diverse ways. CtrlSynth is a closed-loop, training-free, and modular framework, making it easy to support different pretrained models. With extensive experiments on 31 datasets spanning different vision and vision-language tasks, we show that CtrlSynth substantially improves zero-shot classification, image-text retrieval, and compositional reasoning performance of CLIP models.
SeedLM: Compressing LLM Weights into Seeds of Pseudo-Random Generators
Oct 14, 2024



Large Language Models (LLMs) have transformed natural language processing, but face significant challenges in widespread deployment due to their high runtime cost. In this paper, we introduce SeedLM, a novel post-training compression method that uses seeds of pseudo-random generators to encode and compress model weights. Specifically, for each block of weights, we find a seed that is fed into a Linear Feedback Shift Register (LFSR) during inference to efficiently generate a random matrix. This matrix is then linearly combined with compressed coefficients to reconstruct the weight block. SeedLM reduces memory access and leverages idle compute cycles during inference, effectively speeding up memory-bound tasks by trading compute for fewer memory accesses. Unlike state-of-the-art compression methods that rely on calibration data, our approach is data-free and generalizes well across diverse tasks. Our experiments with Llama 3 70B, which is particularly challenging to compress, show that SeedLM achieves significantly better zero-shot accuracy retention at 4- and 3-bit than state-of-the-art techniques, while maintaining performance comparable to FP16 baselines. Additionally, FPGA-based tests demonstrate that 4-bit SeedLM, as model size increases to 70B, approaches a 4x speed-up over an FP16 Llama 2/3 baseline.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
Jul 19, 2024



The inference of transformer-based large language models consists of two sequential stages: 1) a prefilling stage to compute the KV cache of prompts and generate the first token, and 2) a decoding stage to generate subsequent tokens. For long prompts, the KV cache must be computed for all tokens during the prefilling stage, which can significantly increase the time needed to generate the first token. Consequently, the prefilling stage may become a bottleneck in the generation process. An open question remains whether all prompt tokens are essential for generating the first token. To answer this, we introduce a novel method, LazyLLM, that selectively computes the KV for tokens important for the next token prediction in both the prefilling and decoding stages. Contrary to static pruning approaches that prune the prompt at once, LazyLLM allows language models to dynamically select different subsets of tokens from the context in different generation steps, even though they might be pruned in previous steps. Extensive experiments on standard datasets across various tasks demonstrate that LazyLLM is a generic method that can be seamlessly integrated with existing language models to significantly accelerate the generation without fine-tuning. For instance, in the multi-document question-answering task, LazyLLM accelerates the prefilling stage of the LLama 2 7B model by 2.34x while maintaining accuracy.
OpenELM: An Efficient Language Model Family with Open Training and Inference Framework
May 02, 2024The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring $2\times$ fewer pre-training tokens. Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}. Additionally, \model models can be found on HuggingFace at: \url{https://huggingface.co/apple/OpenELM}.
CatLIP: CLIP-level Visual Recognition Accuracy with 2.7x Faster Pre-training on Web-scale Image-Text Data
Apr 24, 2024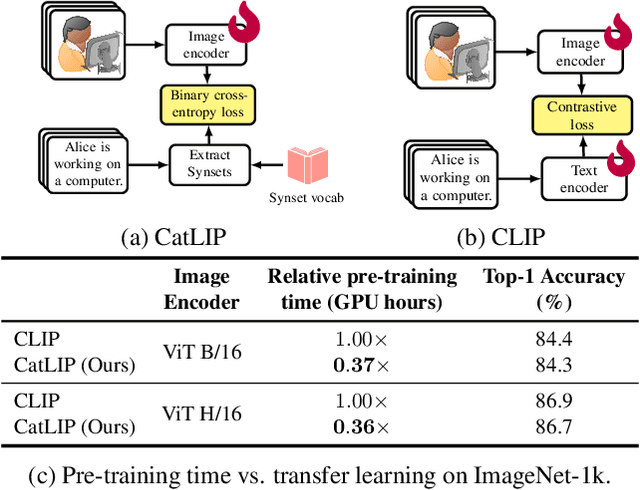

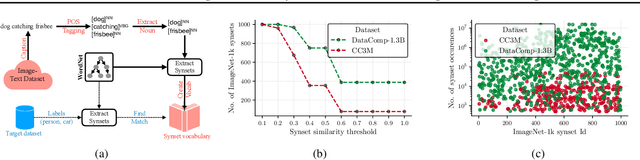
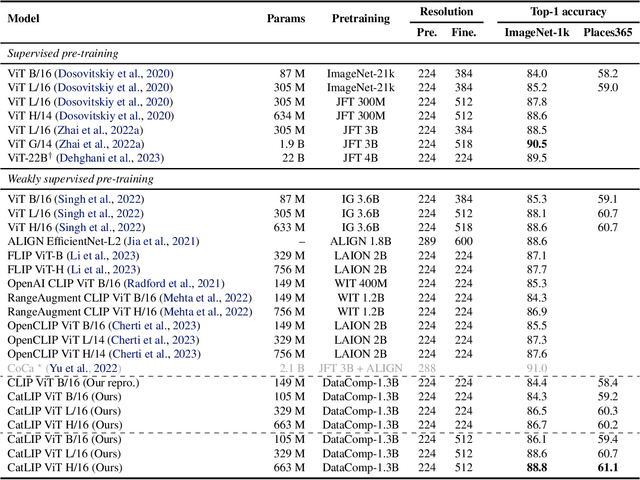
Contrastive learning has emerged as a transformative method for learning effective visual representations through the alignment of image and text embeddings. However, pairwise similarity computation in contrastive loss between image and text pairs poses computational challenges. This paper presents a novel weakly supervised pre-training of vision models on web-scale image-text data. The proposed method reframes pre-training on image-text data as a classification task. Consequently, it eliminates the need for pairwise similarity computations in contrastive loss, achieving a remarkable $2.7\times$ acceleration in training speed compared to contrastive learning on web-scale data. Through extensive experiments spanning diverse vision tasks, including detection and segmentation, we demonstrate that the proposed method maintains high representation quality. Our source code along with pre-trained model weights and training recipes is available at \url{https://github.com/apple/corenet}.
Superposition Prompting: Improving and Accelerating Retrieval-Augmented Generation
Apr 10, 2024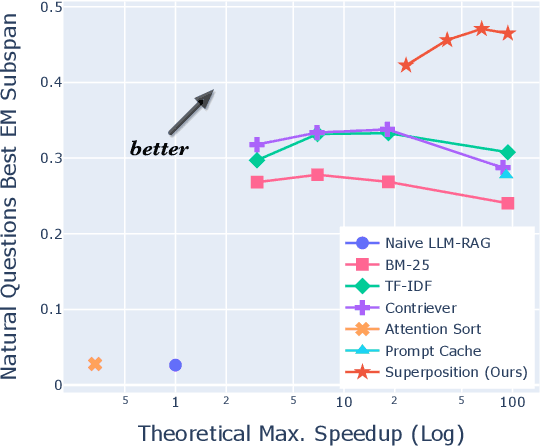
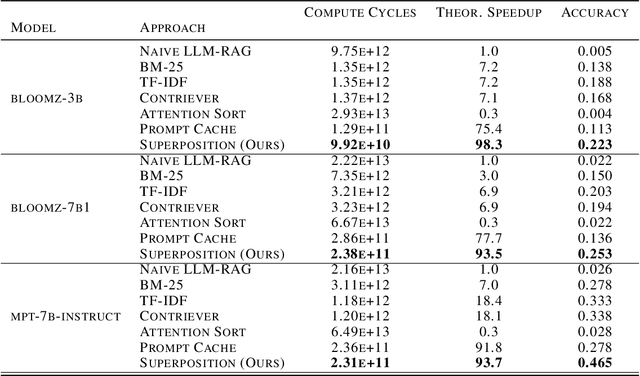
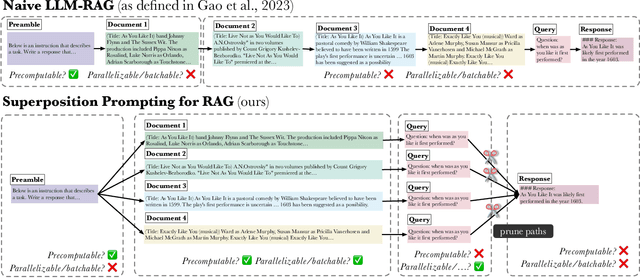
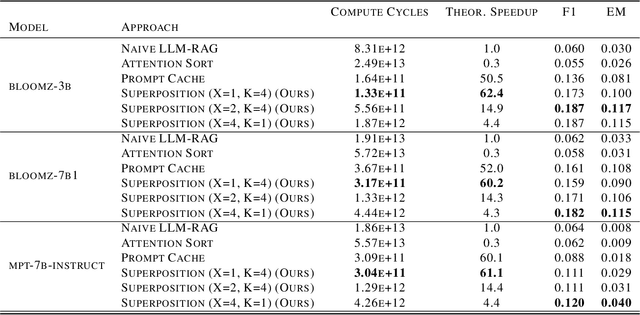
Despite the successes of large language models (LLMs), they exhibit significant drawbacks, particularly when processing long contexts. Their inference cost scales quadratically with respect to sequence length, making it expensive for deployment in some real-world text processing applications, such as retrieval-augmented generation (RAG). Additionally, LLMs also exhibit the "distraction phenomenon," where irrelevant context in the prompt degrades output quality. To address these drawbacks, we propose a novel RAG prompting methodology, superposition prompting, which can be directly applied to pre-trained transformer-based LLMs without the need for fine-tuning. At a high level, superposition prompting allows the LLM to process input documents in parallel prompt paths, discarding paths once they are deemed irrelevant. We demonstrate the capability of our method to simultaneously enhance time efficiency across a variety of question-answering benchmarks using multiple pre-trained LLMs. Furthermore, our technique significantly improves accuracy when the retrieved context is large relative the context the model was trained on. For example, our approach facilitates an 93x reduction in compute time while improving accuracy by 43\% on the NaturalQuestions-Open dataset with the MPT-7B instruction-tuned model over naive RAG.