 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
LazyLLM: Dynamic Token Pruning for Efficient Long Context LLM Inference
Jul 19, 2024



The inference of transformer-based large language models consists of two sequential stages: 1) a prefilling stage to compute the KV cache of prompts and generate the first token, and 2) a decoding stage to generate subsequent tokens. For long prompts, the KV cache must be computed for all tokens during the prefilling stage, which can significantly increase the time needed to generate the first token. Consequently, the prefilling stage may become a bottleneck in the generation process. An open question remains whether all prompt tokens are essential for generating the first token. To answer this, we introduce a novel method, LazyLLM, that selectively computes the KV for tokens important for the next token prediction in both the prefilling and decoding stages. Contrary to static pruning approaches that prune the prompt at once, LazyLLM allows language models to dynamically select different subsets of tokens from the context in different generation steps, even though they might be pruned in previous steps. Extensive experiments on standard datasets across various tasks demonstrate that LazyLLM is a generic method that can be seamlessly integrated with existing language models to significantly accelerate the generation without fine-tuning. For instance, in the multi-document question-answering task, LazyLLM accelerates the prefilling stage of the LLama 2 7B model by 2.34x while maintaining accuracy.
Superposition Prompting: Improving and Accelerating Retrieval-Augmented Generation
Apr 10, 2024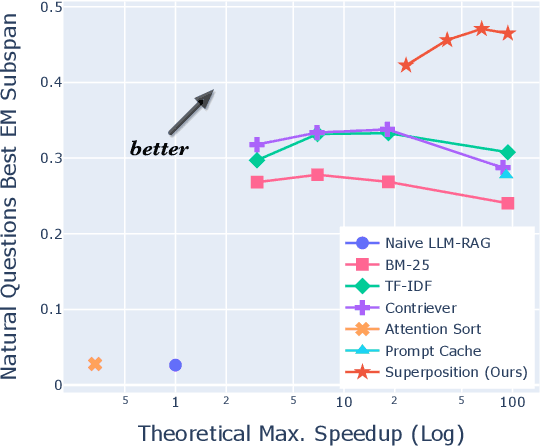
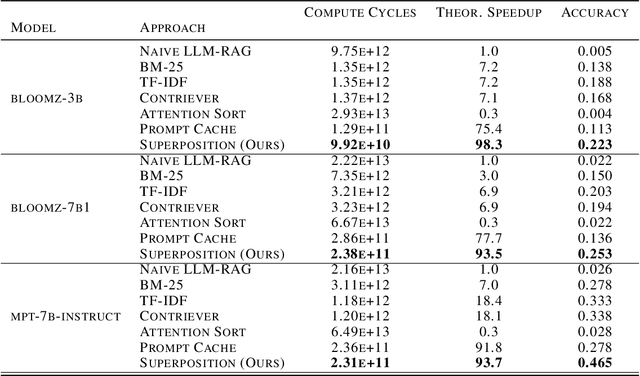
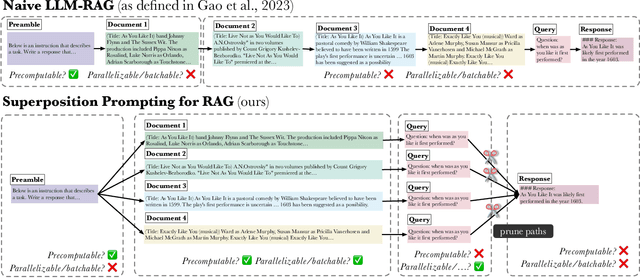
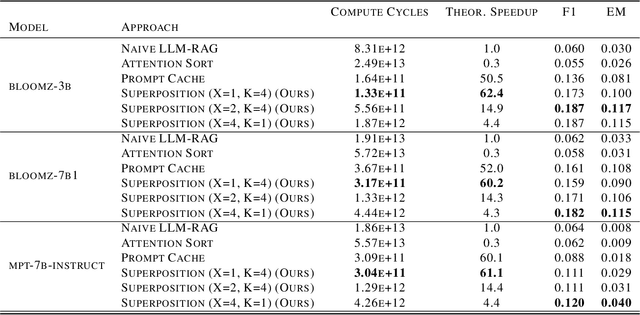
Despite the successes of large language models (LLMs), they exhibit significant drawbacks, particularly when processing long contexts. Their inference cost scales quadratically with respect to sequence length, making it expensive for deployment in some real-world text processing applications, such as retrieval-augmented generation (RAG). Additionally, LLMs also exhibit the "distraction phenomenon," where irrelevant context in the prompt degrades output quality. To address these drawbacks, we propose a novel RAG prompting methodology, superposition prompting, which can be directly applied to pre-trained transformer-based LLMs without the need for fine-tuning. At a high level, superposition prompting allows the LLM to process input documents in parallel prompt paths, discarding paths once they are deemed irrelevant. We demonstrate the capability of our method to simultaneously enhance time efficiency across a variety of question-answering benchmarks using multiple pre-trained LLMs. Furthermore, our technique significantly improves accuracy when the retrieved context is large relative the context the model was trained on. For example, our approach facilitates an 93x reduction in compute time while improving accuracy by 43\% on the NaturalQuestions-Open dataset with the MPT-7B instruction-tuned model over naive RAG.
FastSR-NeRF: Improving NeRF Efficiency on Consumer Devices with A Simple Super-Resolution Pipeline
Dec 20, 2023



Super-resolution (SR) techniques have recently been proposed to upscale the outputs of neural radiance fields (NeRF) and generate high-quality images with enhanced inference speeds. However, existing NeRF+SR methods increase training overhead by using extra input features, loss functions, and/or expensive training procedures such as knowledge distillation. In this paper, we aim to leverage SR for efficiency gains without costly training or architectural changes. Specifically, we build a simple NeRF+SR pipeline that directly combines existing modules, and we propose a lightweight augmentation technique, random patch sampling, for training. Compared to existing NeRF+SR methods, our pipeline mitigates the SR computing overhead and can be trained up to 23x faster, making it feasible to run on consumer devices such as the Apple MacBook. Experiments show our pipeline can upscale NeRF outputs by 2-4x while maintaining high quality, increasing inference speeds by up to 18x on an NVIDIA V100 GPU and 12.8x on an M1 Pro chip. We conclude that SR can be a simple but effective technique for improving the efficiency of NeRF models for consumer devices.
Prompting might be all you need to repair Compressed LLMs
Oct 14, 2023



Large language models (LLMs), while transformative for NLP, come with significant computational demands, underlining the need for efficient, training-free compression. Notably, despite the marked improvement in training-free compression for the largest of LLMs, our tests using LLaMA-7B and OPT-6.7b highlight a significant performance drop in several realistic downstream tasks. Investigation into the trade-off between resource-intensive post-compression re-training highlights the prospect of prompt-driven recovery as a lightweight adaption tool. However, existing studies, confined mainly to perplexity evaluations and simple tasks, fail to offer unequivocal confidence in the scalability and generalizability of prompting. We tackle this uncertainty in two key ways. First, we uncover the vulnerability of naive prompts in LLM compression as an over-reliance on a singular prompt per input. In response, we propose inference-time dynamic prompting (IDP), a mechanism that autonomously chooses from a set of curated prompts based on the context of each individual input. Second, we delve into a scientific understanding of why "prompting might be all you need post-LLM compression." Our findings suggest that compression does not irretrievably erase LLM model knowledge but displace it, necessitating a new inference path. IDP effectively redirects this path, enabling the model to tap into its inherent yet displaced knowledge and thereby recover performance. Empirical tests affirm the value of IDP, demonstrating an average performance improvement of 1.24% across nine varied tasks spanning multiple knowledge domains.
On the Efficacy of Multi-scale Data Samplers for Vision Applications
Sep 08, 2023



Multi-scale resolution training has seen an increased adoption across multiple vision tasks, including classification and detection. Training with smaller resolutions enables faster training at the expense of a drop in accuracy. Conversely, training with larger resolutions has been shown to improve performance, but memory constraints often make this infeasible. In this paper, we empirically study the properties of multi-scale training procedures. We focus on variable batch size multi-scale data samplers that randomly sample an input resolution at each training iteration and dynamically adjust their batch size according to the resolution. Such samplers have been shown to improve model accuracy beyond standard training with a fixed batch size and resolution, though it is not clear why this is the case. We explore the properties of these data samplers by performing extensive experiments on ResNet-101 and validate our conclusions across multiple architectures, tasks, and datasets. We show that multi-scale samplers behave as implicit data regularizers and accelerate training speed. Compared to models trained with single-scale samplers, we show that models trained with multi-scale samplers retain or improve accuracy, while being better-calibrated and more robust to scaling and data distribution shifts. We additionally extend a multi-scale variable batch sampler with a simple curriculum that progressively grows resolutions throughout training, allowing for a compute reduction of more than 30%. We show that the benefits of multi-scale training extend to detection and instance segmentation tasks, where we observe a 37% reduction in training FLOPs along with a 3-4% mAP increase on MS-COCO using a Mask R-CNN model.
SPIN: An Empirical Evaluation on Sharing Parameters of Isotropic Networks
Jul 21, 2022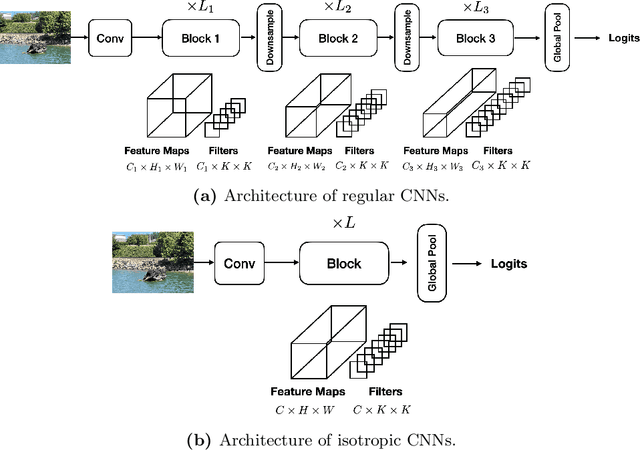
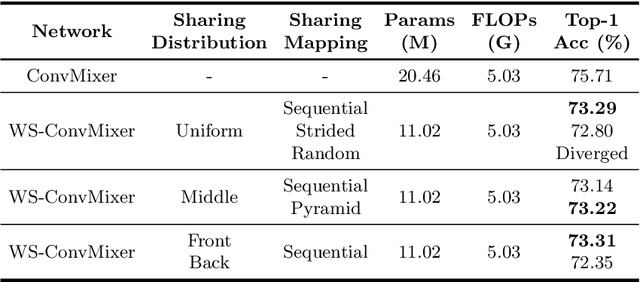
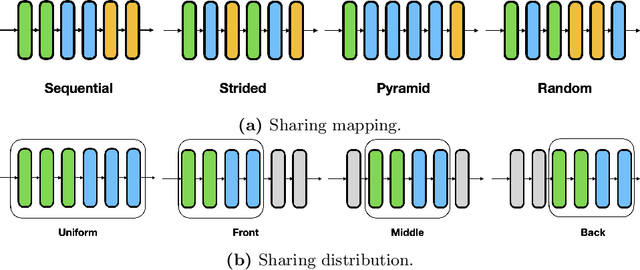
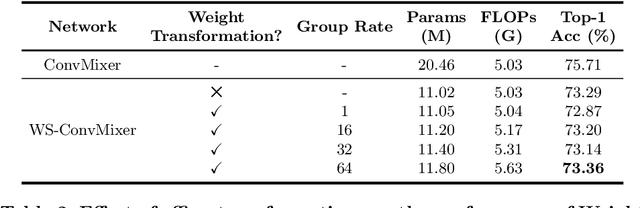
Recent isotropic networks, such as ConvMixer and vision transformers, have found significant success across visual recognition tasks, matching or outperforming non-isotropic convolutional neural networks (CNNs). Isotropic architectures are particularly well-suited to cross-layer weight sharing, an effective neural network compression technique. In this paper, we perform an empirical evaluation on methods for sharing parameters in isotropic networks (SPIN). We present a framework to formalize major weight sharing design decisions and perform a comprehensive empirical evaluation of this design space. Guided by our experimental results, we propose a weight sharing strategy to generate a family of models with better overall efficiency, in terms of FLOPs and parameters versus accuracy, compared to traditional scaling methods alone, for example compressing ConvMixer by 1.9x while improving accuracy on ImageNet. Finally, we perform a qualitative study to further understand the behavior of weight sharing in isotropic architectures. The code is available at https://github.com/apple/ml-spin.