 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpansion Span: Combining Fading Memory and Retrieval in Hybrid State Space Models
Dec 17, 2024



The "state" of State Space Models (SSMs) represents their memory, which fades exponentially over an unbounded span. By contrast, Attention-based models have "eidetic" (i.e., verbatim, or photographic) memory over a finite span (context size). Hybrid architectures combine State Space layers with Attention, but still cannot recall the distant past and can access only the most recent tokens eidetically. Unlike current methods of combining SSM and Attention layers, we allow the state to be allocated based on relevancy rather than recency. In this way, for every new set of query tokens, our models can "eidetically" access tokens from beyond the Attention span of current Hybrid SSMs without requiring extra hardware resources. We describe a method to expand the memory span of the hybrid state by "reserving" a fraction of the Attention context for tokens retrieved from arbitrarily distant in the past, thus expanding the eidetic memory span of the overall state. We call this reserved fraction of tokens the "expansion span," and the mechanism to retrieve and aggregate it "Span-Expanded Attention" (SE-Attn). To adapt Hybrid models to using SE-Attn, we propose a novel fine-tuning method that extends LoRA to Hybrid models (HyLoRA) and allows efficient adaptation on long spans of tokens. We show that SE-Attn enables us to efficiently adapt pre-trained Hybrid models on sequences of tokens up to 8 times longer than the ones used for pre-training. We show that HyLoRA with SE-Attn is cheaper and more performant than alternatives like LongLoRA when applied to Hybrid models on natural language benchmarks with long-range dependencies, such as PG-19, RULER, and other common natural language downstream tasks.
Diffusion Models as Masked Audio-Video Learners
Oct 05, 2023



Over the past several years, the synchronization between audio and visual signals has been leveraged to learn richer audio-visual representations. Aided by the large availability of unlabeled videos, many unsupervised training frameworks have demonstrated impressive results in various downstream audio and video tasks. Recently, Masked Audio-Video Learners (MAViL) has emerged as a state-of-the-art audio-video pre-training framework. MAViL couples contrastive learning with masked autoencoding to jointly reconstruct audio spectrograms and video frames by fusing information from both modalities. In this paper, we study the potential synergy between diffusion models and MAViL, seeking to derive mutual benefits from these two frameworks. The incorporation of diffusion into MAViL, combined with various training efficiency methodologies that include the utilization of a masking ratio curriculum and adaptive batch sizing, results in a notable 32% reduction in pre-training Floating-Point Operations (FLOPS) and an 18% decrease in pre-training wall clock time. Crucially, this enhanced efficiency does not compromise the model's performance in downstream audio-classification tasks when compared to MAViL's performance.
On the Efficacy of Multi-scale Data Samplers for Vision Applications
Sep 08, 2023



Multi-scale resolution training has seen an increased adoption across multiple vision tasks, including classification and detection. Training with smaller resolutions enables faster training at the expense of a drop in accuracy. Conversely, training with larger resolutions has been shown to improve performance, but memory constraints often make this infeasible. In this paper, we empirically study the properties of multi-scale training procedures. We focus on variable batch size multi-scale data samplers that randomly sample an input resolution at each training iteration and dynamically adjust their batch size according to the resolution. Such samplers have been shown to improve model accuracy beyond standard training with a fixed batch size and resolution, though it is not clear why this is the case. We explore the properties of these data samplers by performing extensive experiments on ResNet-101 and validate our conclusions across multiple architectures, tasks, and datasets. We show that multi-scale samplers behave as implicit data regularizers and accelerate training speed. Compared to models trained with single-scale samplers, we show that models trained with multi-scale samplers retain or improve accuracy, while being better-calibrated and more robust to scaling and data distribution shifts. We additionally extend a multi-scale variable batch sampler with a simple curriculum that progressively grows resolutions throughout training, allowing for a compute reduction of more than 30%. We show that the benefits of multi-scale training extend to detection and instance segmentation tasks, where we observe a 37% reduction in training FLOPs along with a 3-4% mAP increase on MS-COCO using a Mask R-CNN model.
LCS: Learning Compressible Subspaces for Adaptive Network Compression at Inference Time
Oct 08, 2021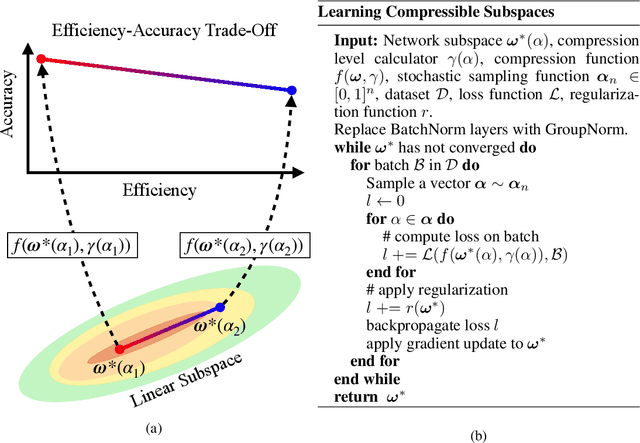

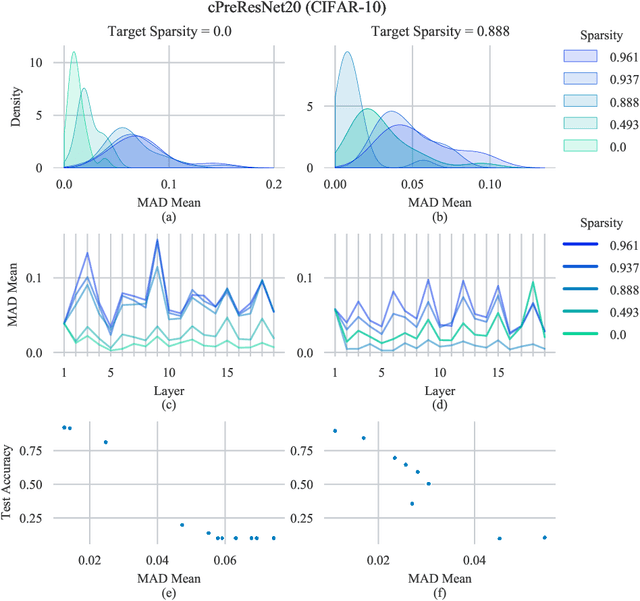
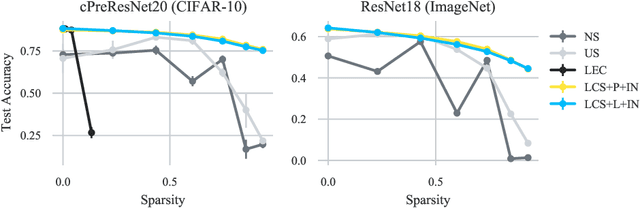
When deploying deep learning models to a device, it is traditionally assumed that available computational resources (compute, memory, and power) remain static. However, real-world computing systems do not always provide stable resource guarantees. Computational resources need to be conserved when load from other processes is high or battery power is low. Inspired by recent works on neural network subspaces, we propose a method for training a "compressible subspace" of neural networks that contains a fine-grained spectrum of models that range from highly efficient to highly accurate. Our models require no retraining, thus our subspace of models can be deployed entirely on-device to allow adaptive network compression at inference time. We present results for achieving arbitrarily fine-grained accuracy-efficiency trade-offs at inference time for structured and unstructured sparsity. We achieve accuracies on-par with standard models when testing our uncompressed models, and maintain high accuracy for sparsity rates above 90% when testing our compressed models. We also demonstrate that our algorithm extends to quantization at variable bit widths, achieving accuracy on par with individually trained networks.
Alignment of Tractography Streamlines using Deformation Transfer via Parallel Transport
Aug 08, 2021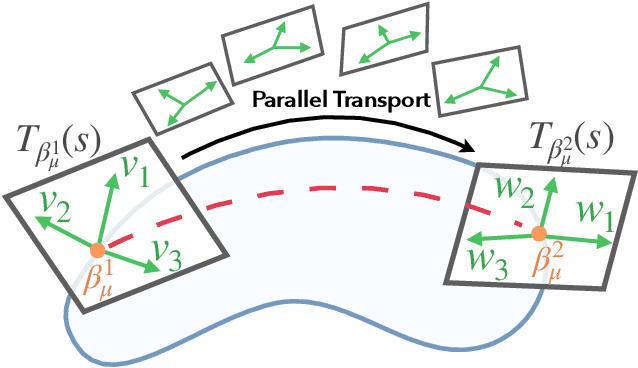
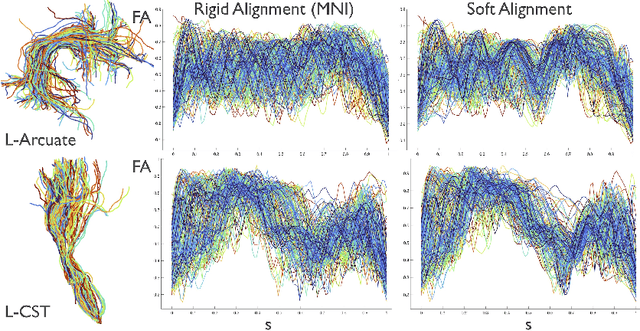


We present a geometric framework for aligning white matter fiber tracts. By registering fiber tracts between brains, one expects to see overlap of anatomical structures that often provide meaningful comparisons across subjects. However, the geometry of white matter tracts is highly heterogeneous, and finding direct tract-correspondence across multiple individuals remains a challenging problem. We present a novel deformation metric between tracts that allows one to compare tracts while simultaneously obtaining a registration. To accomplish this, fiber tracts are represented by an intrinsic mean along with the deformation fields represented by tangent vectors from the mean. In this setting, one can determine a parallel transport between tracts and then register corresponding tangent vectors. We present the results of bundle alignment on a population of 43 healthy adult subjects.
SrvfNet: A Generative Network for Unsupervised Multiple Diffeomorphic Shape Alignment
Apr 27, 2021


We present SrvfNet, a generative deep learning framework for the joint multiple alignment of large collections of functional data comprising square-root velocity functions (SRVF) to their templates. Our proposed framework is fully unsupervised and is capable of aligning to a predefined template as well as jointly predicting an optimal template from data while simultaneously achieving alignment. Our network is constructed as a generative encoder-decoder architecture comprising fully-connected layers capable of producing a distribution space of the warping functions. We demonstrate the strength of our framework by validating it on synthetic data as well as diffusion profiles from magnetic resonance imaging (MRI) data.