 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable VQ-VAE's for Robust White Matter Streamline Encodings
Nov 18, 2023



Given the complex geometry of white matter streamlines, Autoencoders have been proposed as a dimension-reduction tool to simplify the analysis streamlines in a low-dimensional latent spaces. However, despite these recent successes, the majority of encoder architectures only perform dimension reduction on single streamlines as opposed to a full bundle of streamlines. This is a severe limitation of the encoder architecture that completely disregards the global geometric structure of streamlines at the expense of individual fibers. Moreover, the latent space may not be well structured which leads to doubt into their interpretability. In this paper we propose a novel Differentiable Vector Quantized Variational Autoencoder, which are engineered to ingest entire bundles of streamlines as single data-point and provides reliable trustworthy encodings that can then be later used to analyze streamlines in the latent space. Comparisons with several state of the art Autoencoders demonstrate superior performance in both encoding and synthesis.
StreamNet: A WAE for White Matter Streamline Analysis
Sep 03, 2022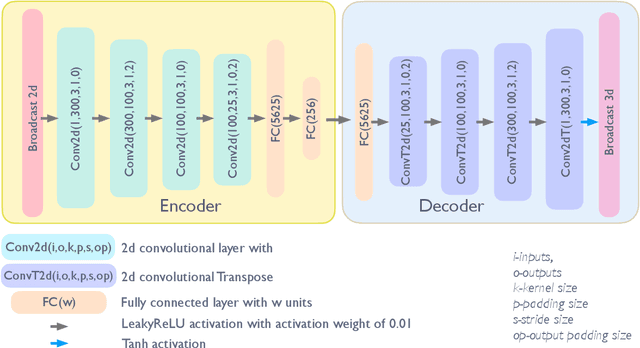

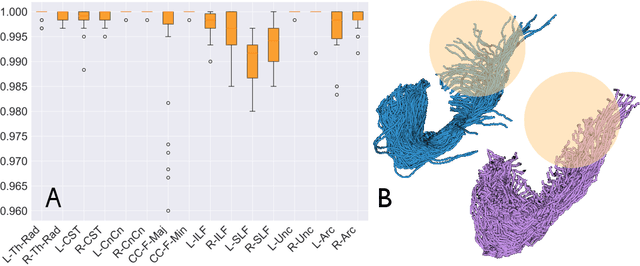
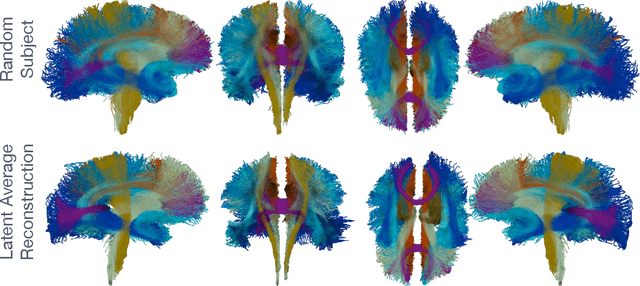
We present StreamNet, an autoencoder architecture for the analysis of the highly heterogeneous geometry of large collections of white matter streamlines. This proposed framework takes advantage of geometry-preserving properties of the Wasserstein-1 metric in order to achieve direct encoding and reconstruction of entire bundles of streamlines. We show that the model not only accurately captures the distributive structures of streamlines in the population, but is also able to achieve superior reconstruction performance between real and synthetic streamlines. Experimental model performance is evaluated on white matter streamlines resulting from T1-weighted diffusion imaging of 40 healthy controls using recent state of the art bundle comparison metric that measures fiber-shape similarities.
Alignment of Tractography Streamlines using Deformation Transfer via Parallel Transport
Aug 08, 2021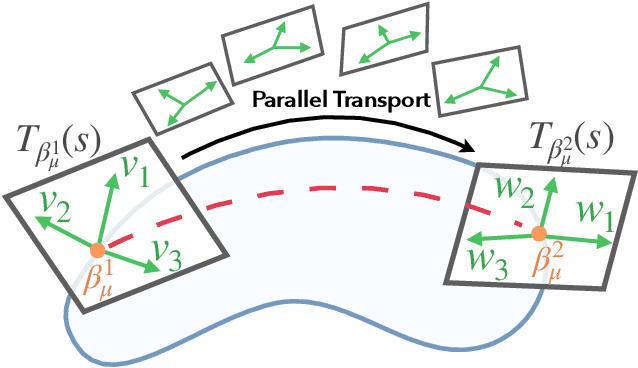
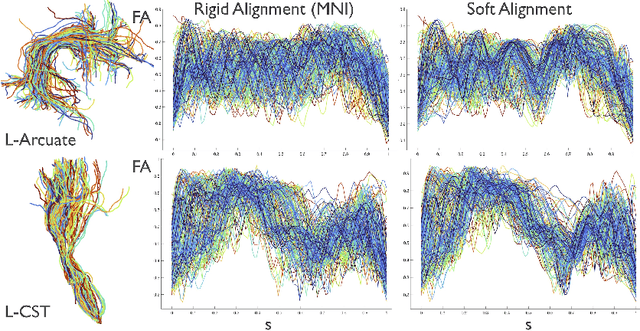


We present a geometric framework for aligning white matter fiber tracts. By registering fiber tracts between brains, one expects to see overlap of anatomical structures that often provide meaningful comparisons across subjects. However, the geometry of white matter tracts is highly heterogeneous, and finding direct tract-correspondence across multiple individuals remains a challenging problem. We present a novel deformation metric between tracts that allows one to compare tracts while simultaneously obtaining a registration. To accomplish this, fiber tracts are represented by an intrinsic mean along with the deformation fields represented by tangent vectors from the mean. In this setting, one can determine a parallel transport between tracts and then register corresponding tangent vectors. We present the results of bundle alignment on a population of 43 healthy adult subjects.
SrvfNet: A Generative Network for Unsupervised Multiple Diffeomorphic Shape Alignment
Apr 27, 2021


We present SrvfNet, a generative deep learning framework for the joint multiple alignment of large collections of functional data comprising square-root velocity functions (SRVF) to their templates. Our proposed framework is fully unsupervised and is capable of aligning to a predefined template as well as jointly predicting an optimal template from data while simultaneously achieving alignment. Our network is constructed as a generative encoder-decoder architecture comprising fully-connected layers capable of producing a distribution space of the warping functions. We demonstrate the strength of our framework by validating it on synthetic data as well as diffusion profiles from magnetic resonance imaging (MRI) data.
Automating Artifact Detection in Video Games
Nov 30, 2020


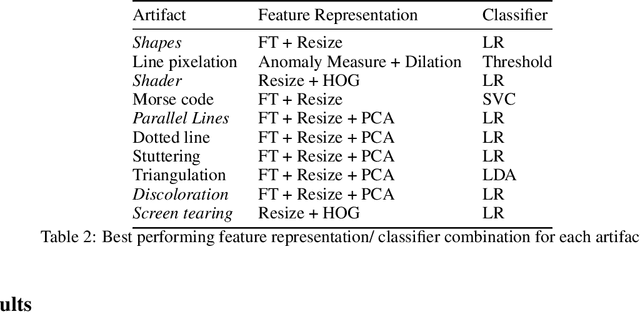
In spite of advances in gaming hardware and software, gameplay is often tainted with graphics errors, glitches, and screen artifacts. This proof of concept study presents a machine learning approach for automated detection of graphics corruptions in video games. Based on a sample of representative screen corruption examples, the model was able to identify 10 of the most commonly occurring screen artifacts with reasonable accuracy. Feature representation of the data included discrete Fourier transforms, histograms of oriented gradients, and graph Laplacians. Various combinations of these features were used to train machine learning models that identify individual classes of graphics corruptions and that later were assembled into a single mixed experts "ensemble" classifier. The ensemble classifier was tested on heldout test sets, and produced an accuracy of 84% on the games it had seen before, and 69% on games it had never seen before.