 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Data Pruning: Uncovering and Overcoming Implicit Bias
Apr 08, 2024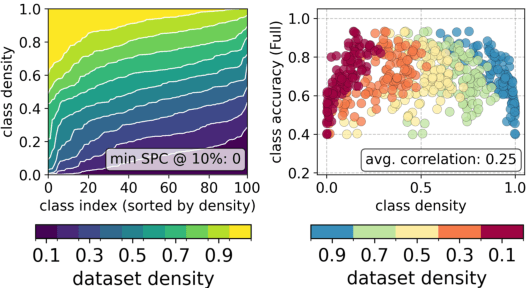
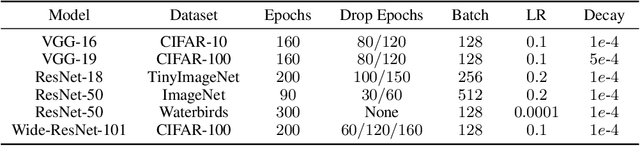
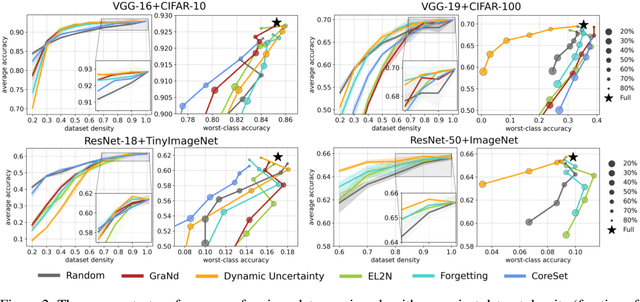
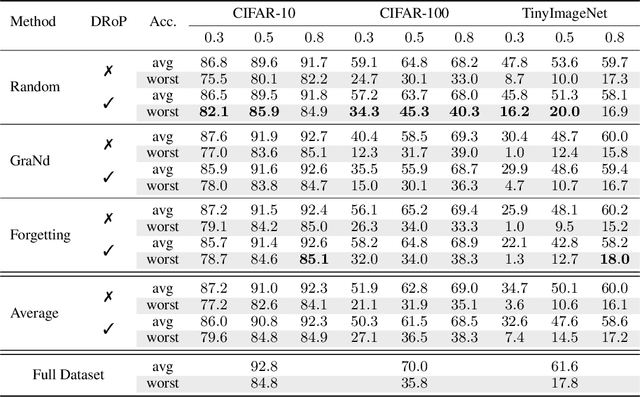
In the era of exceptionally data-hungry models, careful selection of the training data is essential to mitigate the extensive costs of deep learning. Data pruning offers a solution by removing redundant or uninformative samples from the dataset, which yields faster convergence and improved neural scaling laws. However, little is known about its impact on classification bias of the trained models. We conduct the first systematic study of this effect and reveal that existing data pruning algorithms can produce highly biased classifiers. At the same time, we argue that random data pruning with appropriate class ratios has potential to improve the worst-class performance. We propose a "fairness-aware" approach to pruning and empirically demonstrate its performance on standard computer vision benchmarks. In sharp contrast to existing algorithms, our proposed method continues improving robustness at a tolerable drop of average performance as we prune more from the datasets. We present theoretical analysis of the classification risk in a mixture of Gaussians to further motivate our algorithm and support our findings.
Towards Efficient Active Learning in NLP via Pretrained Representations
Feb 23, 2024Fine-tuning Large Language Models (LLMs) is now a common approach for text classification in a wide range of applications. When labeled documents are scarce, active learning helps save annotation efforts but requires retraining of massive models on each acquisition iteration. We drastically expedite this process by using pretrained representations of LLMs within the active learning loop and, once the desired amount of labeled data is acquired, fine-tuning that or even a different pretrained LLM on this labeled data to achieve the best performance. As verified on common text classification benchmarks with pretrained BERT and RoBERTa as the backbone, our strategy yields similar performance to fine-tuning all the way through the active learning loop but is orders of magnitude less computationally expensive. The data acquired with our procedure generalizes across pretrained networks, allowing flexibility in choosing the final model or updating it as newer versions get released.
Deconstructing the Goldilocks Zone of Neural Network Initialization
Feb 05, 2024The second-order properties of the training loss have a massive impact on the optimization dynamics of deep learning models. Fort & Scherlis (2019) discovered that a high positive curvature and local convexity of the loss Hessian are associated with highly trainable initial points located in a region coined the "Goldilocks zone". Only a handful of subsequent studies touched upon this relationship, so it remains largely unexplained. In this paper, we present a rigorous and comprehensive analysis of the Goldilocks zone for homogeneous neural networks. In particular, we derive the fundamental condition resulting in non-zero positive curvature of the loss Hessian and argue that it is only incidentally related to the initialization norm, contrary to prior beliefs. Further, we relate high positive curvature to model confidence, low initial loss, and a previously unknown type of vanishing cross-entropy loss gradient. To understand the importance of positive curvature for trainability of deep networks, we optimize both fully-connected and convolutional architectures outside the Goldilocks zone and analyze the emergent behaviors. We find that strong model performance is not necessarily aligned with the Goldilocks zone, which questions the practical significance of this concept.
ImpressLearn: Continual Learning via Combined Task Impressions
Oct 05, 2022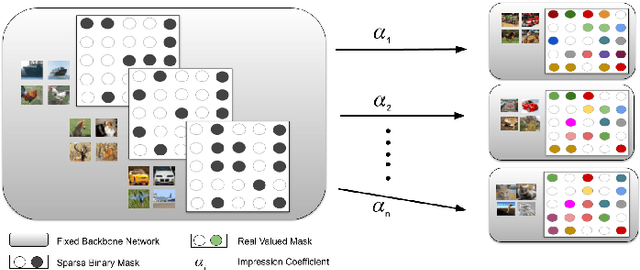
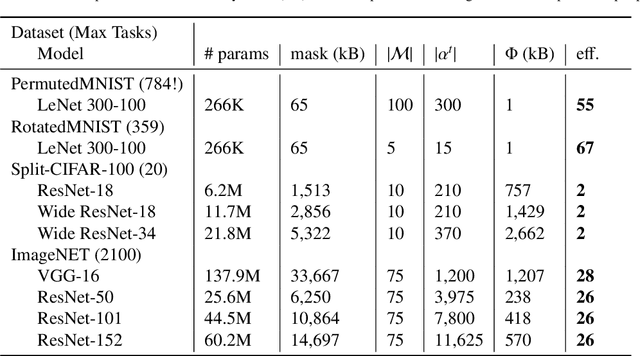
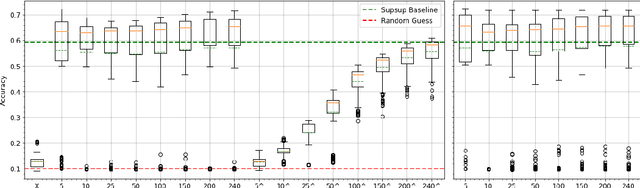
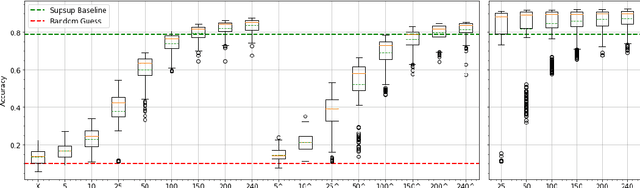
This work proposes a new method to sequentially train a deep neural network on multiple tasks without suffering catastrophic forgetting, while endowing it with the capability to quickly adapt to unseen tasks. Starting from existing work on network masking (Wortsman et al., 2020), we show that simply learning a linear combination of a small number of task-specific masks (impressions) on a randomly initialized backbone network is sufficient to both retain accuracy on previously learned tasks, as well as achieve high accuracy on new tasks. In contrast to previous methods, we do not require to generate dedicated masks or contexts for each new task, instead leveraging transfer learning to keep per-task parameter overhead small. Our work illustrates the power of linearly combining individual impressions, each of which fares poorly in isolation, to achieve performance comparable to a dedicated mask. Moreover, even repeated impressions from the same task (homogeneous masks), when combined can approach the performance of heterogeneous combinations if sufficiently many impressions are used. Our approach scales more efficiently than existing methods, often requiring orders of magnitude fewer parameters and can function without modification even when task identity is missing. In addition, in the setting where task labels are not given at inference, our algorithm gives an often favorable alternative to the entropy based task-inference methods proposed in (Wortsman et al., 2020). We evaluate our method on a number of well known image classification data sets and architectures.
Connectivity Matters: Neural Network Pruning Through the Lens of Effective Sparsity
Jul 05, 2021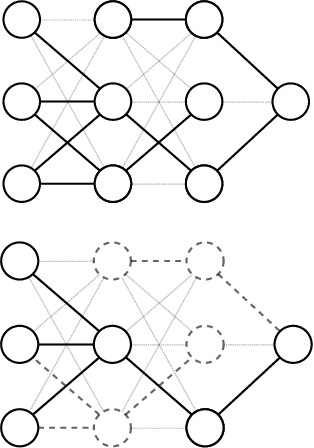
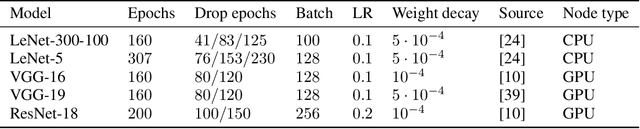
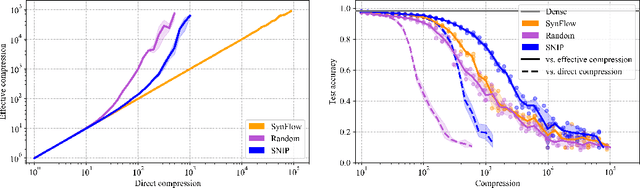
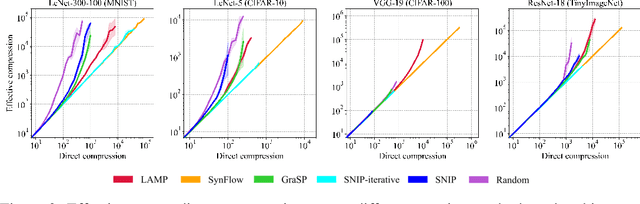
Neural network pruning is a fruitful area of research with surging interest in high sparsity regimes. Benchmarking in this domain heavily relies on faithful representation of the sparsity of subnetworks, which has been traditionally computed as the fraction of removed connections (direct sparsity). This definition, however, fails to recognize unpruned parameters that detached from input or output layers of underlying subnetworks, potentially underestimating actual effective sparsity: the fraction of inactivated connections. While this effect might be negligible for moderately pruned networks (up to 10-100 compression rates), we find that it plays an increasing role for thinner subnetworks, greatly distorting comparison between different pruning algorithms. For example, we show that effective compression of a randomly pruned LeNet-300-100 can be orders of magnitude larger than its direct counterpart, while no discrepancy is ever observed when using SynFlow for pruning [Tanaka et al., 2020]. In this work, we adopt the lens of effective sparsity to reevaluate several recent pruning algorithms on common benchmark architectures (e.g., LeNet-300-100, VGG-19, ResNet-18) and discover that their absolute and relative performance changes dramatically in this new and more appropriate framework. To aim for effective, rather than direct, sparsity, we develop a low-cost extension to most pruning algorithms. Further, equipped with effective sparsity as a reference frame, we partially reconfirm that random pruning with appropriate sparsity allocation across layers performs as well or better than more sophisticated algorithms for pruning at initialization [Su et al., 2020]. In response to this observation, using a simple analogy of pressure distribution in coupled cylinders from physics, we design novel layerwise sparsity quotas that outperform all existing baselines in the context of random pruning.
Automating Artifact Detection in Video Games
Nov 30, 2020


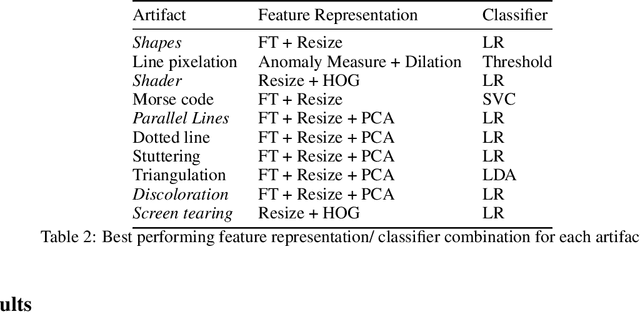
In spite of advances in gaming hardware and software, gameplay is often tainted with graphics errors, glitches, and screen artifacts. This proof of concept study presents a machine learning approach for automated detection of graphics corruptions in video games. Based on a sample of representative screen corruption examples, the model was able to identify 10 of the most commonly occurring screen artifacts with reasonable accuracy. Feature representation of the data included discrete Fourier transforms, histograms of oriented gradients, and graph Laplacians. Various combinations of these features were used to train machine learning models that identify individual classes of graphics corruptions and that later were assembled into a single mixed experts "ensemble" classifier. The ensemble classifier was tested on heldout test sets, and produced an accuracy of 84% on the games it had seen before, and 69% on games it had never seen before.