 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Causal Discovery for Autoregressive Time Series
Jul 10, 2025In this study, we present a novel constraint-based algorithm for causal structure learning specifically designed for nonlinear autoregressive time series. Our algorithm significantly reduces computational complexity compared to existing methods, making it more efficient and scalable to larger problems. We rigorously evaluate its performance on synthetic datasets, demonstrating that our algorithm not only outperforms current techniques, but also excels in scenarios with limited data availability. These results highlight its potential for practical applications in fields requiring efficient and accurate causal inference from nonlinear time series data.
Filling in Missing FX Implied Volatilities with Uncertainties: Improving VAE-Based Volatility Imputation
Nov 08, 2024Missing data is a common problem in finance and often requires methods to fill in the gaps, or in other words, imputation. In this work, we focused on the imputation of missing implied volatilities for FX options. Prior work has used variational autoencoders (VAEs), a neural network-based approach, to solve this problem; however, using stronger classical baselines such as Heston with jumps can significantly outperform their results. We show that simple modifications to the architecture of the VAE lead to significant imputation performance improvements (e.g., in low missingness regimes, nearly cutting the error by half), removing the necessity of using $\beta$-VAEs. Further, we modify the VAE imputation algorithm in order to better handle the uncertainty in data, as well as to obtain accurate uncertainty estimates around imputed values.
NeuralFactors: A Novel Factor Learning Approach to Generative Modeling of Equities
Aug 02, 2024



The use of machine learning for statistical modeling (and thus, generative modeling) has grown in popularity with the proliferation of time series models, text-to-image models, and especially large language models. Fundamentally, the goal of classical factor modeling is statistical modeling of stock returns, and in this work, we explore using deep generative modeling to enhance classical factor models. Prior work has explored the use of deep generative models in order to model hundreds of stocks, leading to accurate risk forecasting and alpha portfolio construction; however, that specific model does not allow for easy factor modeling interpretation in that the factor exposures cannot be deduced. In this work, we introduce NeuralFactors, a novel machine-learning based approach to factor analysis where a neural network outputs factor exposures and factor returns, trained using the same methodology as variational autoencoders. We show that this model outperforms prior approaches both in terms of log-likelihood performance and computational efficiency. Further, we show that this method is competitive to prior work in generating realistic synthetic data, covariance estimation, risk analysis (e.g., value at risk, or VaR, of portfolios), and portfolio optimization. Finally, due to the connection to classical factor analysis, we analyze how the factors our model learns cluster together and show that the factor exposures could be used for embedding stocks.
NeuralBeta: Estimating Beta Using Deep Learning
Aug 02, 2024
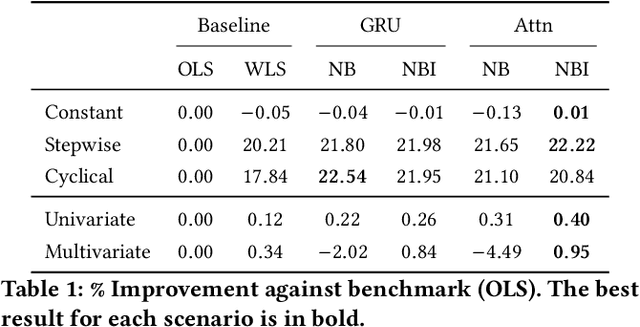


Traditional approaches to estimating beta in finance often involve rigid assumptions and fail to adequately capture beta dynamics, limiting their effectiveness in use cases like hedging. To address these limitations, we have developed a novel method using neural networks called NeuralBeta, which is capable of handling both univariate and multivariate scenarios and tracking the dynamic behavior of beta. To address the issue of interpretability, we introduce a new output layer inspired by regularized weighted linear regression, which provides transparency into the model's decision-making process. We conducted extensive experiments on both synthetic and market data, demonstrating NeuralBeta's superior performance compared to benchmark methods across various scenarios, especially instances where beta is highly time-varying, e.g., during regime shifts in the market. This model not only represents an advancement in the field of beta estimation, but also shows potential for applications in other financial contexts that assume linear relationships.
Towards Efficient Active Learning in NLP via Pretrained Representations
Feb 23, 2024Fine-tuning Large Language Models (LLMs) is now a common approach for text classification in a wide range of applications. When labeled documents are scarce, active learning helps save annotation efforts but requires retraining of massive models on each acquisition iteration. We drastically expedite this process by using pretrained representations of LLMs within the active learning loop and, once the desired amount of labeled data is acquired, fine-tuning that or even a different pretrained LLM on this labeled data to achieve the best performance. As verified on common text classification benchmarks with pretrained BERT and RoBERTa as the backbone, our strategy yields similar performance to fine-tuning all the way through the active learning loop but is orders of magnitude less computationally expensive. The data acquired with our procedure generalizes across pretrained networks, allowing flexibility in choosing the final model or updating it as newer versions get released.
Generative Machine Learning for Multivariate Equity Returns
Nov 21, 2023The use of machine learning to generate synthetic data has grown in popularity with the proliferation of text-to-image models and especially large language models. The core methodology these models use is to learn the distribution of the underlying data, similar to the classical methods common in finance of fitting statistical models to data. In this work, we explore the efficacy of using modern machine learning methods, specifically conditional importance weighted autoencoders (a variant of variational autoencoders) and conditional normalizing flows, for the task of modeling the returns of equities. The main problem we work to address is modeling the joint distribution of all the members of the S&P 500, or, in other words, learning a 500-dimensional joint distribution. We show that this generative model has a broad range of applications in finance, including generating realistic synthetic data, volatility and correlation estimation, risk analysis (e.g., value at risk, or VaR, of portfolios), and portfolio optimization.
DP-TBART: A Transformer-based Autoregressive Model for Differentially Private Tabular Data Generation
Jul 19, 2023The generation of synthetic tabular data that preserves differential privacy is a problem of growing importance. While traditional marginal-based methods have achieved impressive results, recent work has shown that deep learning-based approaches tend to lag behind. In this work, we present Differentially-Private TaBular AutoRegressive Transformer (DP-TBART), a transformer-based autoregressive model that maintains differential privacy and achieves performance competitive with marginal-based methods on a wide variety of datasets, capable of even outperforming state-of-the-art methods in certain settings. We also provide a theoretical framework for understanding the limitations of marginal-based approaches and where deep learning-based approaches stand to contribute most. These results suggest that deep learning-based techniques should be considered as a viable alternative to marginal-based methods in the generation of differentially private synthetic tabular data.
ELF: Exact-Lipschitz Based Universal Density Approximator Flow
Dec 13, 2021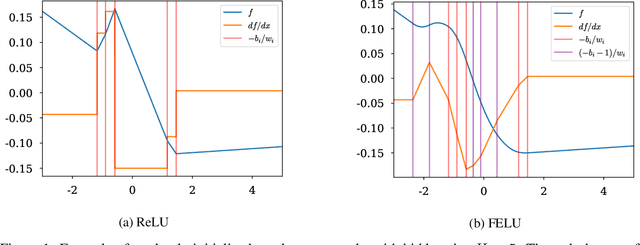
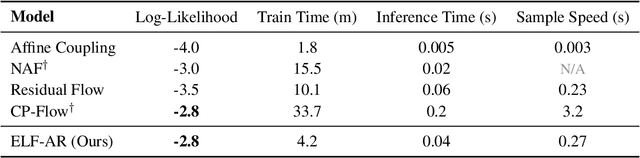
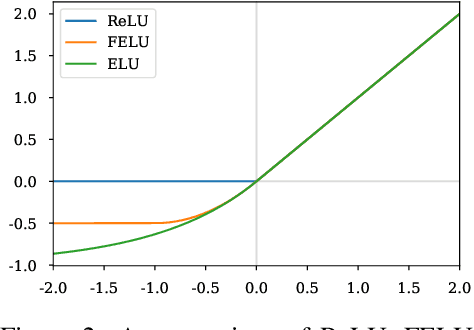
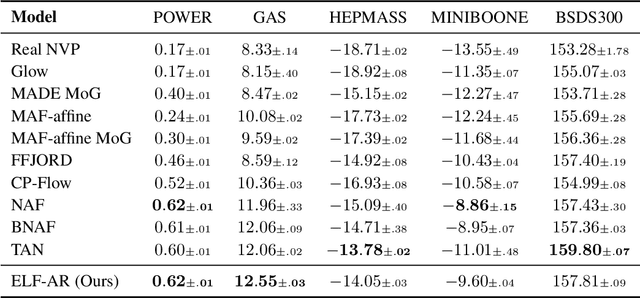
Normalizing flows have grown more popular over the last few years; however, they continue to be computationally expensive, making them difficult to be accepted into the broader machine learning community. In this paper, we introduce a simple one-dimensional one-layer network that has closed form Lipschitz constants; using this, we introduce a new Exact-Lipschitz Flow (ELF) that combines the ease of sampling from residual flows with the strong performance of autoregressive flows. Further, we show that ELF is provably a universal density approximator, more computationally and parameter efficient compared to a multitude of other flows, and achieves state-of-the-art performance on multiple large-scale datasets.
Why Calibration Error is Wrong Given Model Uncertainty: Using Posterior Predictive Checks with Deep Learning
Dec 02, 2021



Within the last few years, there has been a move towards using statistical models in conjunction with neural networks with the end goal of being able to better answer the question, "what do our models know?". From this trend, classical metrics such as Prediction Interval Coverage Probability (PICP) and new metrics such as calibration error have entered the general repertoire of model evaluation in order to gain better insight into how the uncertainty of our model compares to reality. One important component of uncertainty modeling is model uncertainty (epistemic uncertainty), a measurement of what the model does and does not know. However, current evaluation techniques tends to conflate model uncertainty with aleatoric uncertainty (irreducible error), leading to incorrect conclusions. In this paper, using posterior predictive checks, we show how calibration error and its variants are almost always incorrect to use given model uncertainty, and further show how this mistake can lead to trust in bad models and mistrust in good models. Though posterior predictive checks has often been used for in-sample evaluation of Bayesian models, we show it still has an important place in the modern deep learning world.
Discovering Supply Chain Links with Augmented Intelligence
Nov 02, 2021



One of the key components in analyzing the risk of a company is understanding a company's supply chain. Supply chains are constantly disrupted, whether by tariffs, pandemics, severe weather, etc. In this paper, we tackle the problem of predicting previously unknown suppliers and customers of companies using graph neural networks (GNNs) and show strong performance in finding previously unknown connections by combining the predictions of our model and the domain expertise of supply chain analysts.