 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-TBART: A Transformer-based Autoregressive Model for Differentially Private Tabular Data Generation
Jul 19, 2023The generation of synthetic tabular data that preserves differential privacy is a problem of growing importance. While traditional marginal-based methods have achieved impressive results, recent work has shown that deep learning-based approaches tend to lag behind. In this work, we present Differentially-Private TaBular AutoRegressive Transformer (DP-TBART), a transformer-based autoregressive model that maintains differential privacy and achieves performance competitive with marginal-based methods on a wide variety of datasets, capable of even outperforming state-of-the-art methods in certain settings. We also provide a theoretical framework for understanding the limitations of marginal-based approaches and where deep learning-based approaches stand to contribute most. These results suggest that deep learning-based techniques should be considered as a viable alternative to marginal-based methods in the generation of differentially private synthetic tabular data.
EDGE: Editable Dance Generation From Music
Nov 27, 2022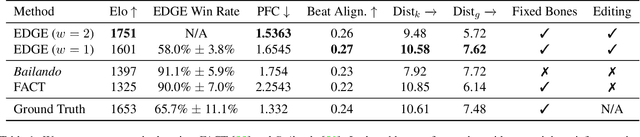
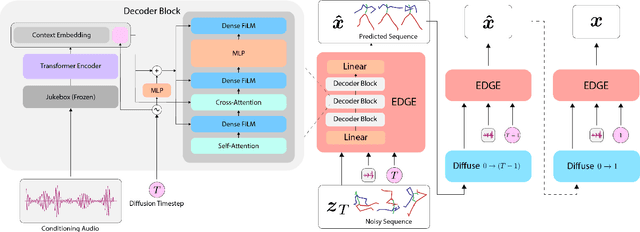
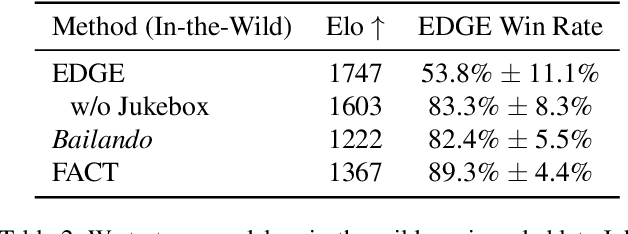
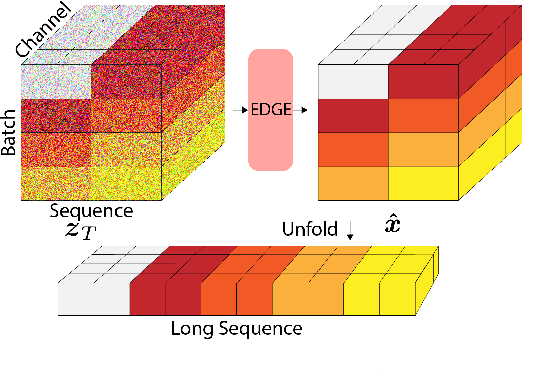
Dance is an important human art form, but creating new dances can be difficult and time-consuming. In this work, we introduce Editable Dance GEneration (EDGE), a state-of-the-art method for editable dance generation that is capable of creating realistic, physically-plausible dances while remaining faithful to the input music. EDGE uses a transformer-based diffusion model paired with Jukebox, a strong music feature extractor, and confers powerful editing capabilities well-suited to dance, including joint-wise conditioning, and in-betweening. We introduce a new metric for physical plausibility, and evaluate dance quality generated by our method extensively through (1) multiple quantitative metrics on physical plausibility, beat alignment, and diversity benchmarks, and more importantly, (2) a large-scale user study, demonstrating a significant improvement over previous state-of-the-art methods. Qualitative samples from our model can be found at our website.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.
Codified audio language modeling learns useful representations for music information retrieval
Jul 12, 2021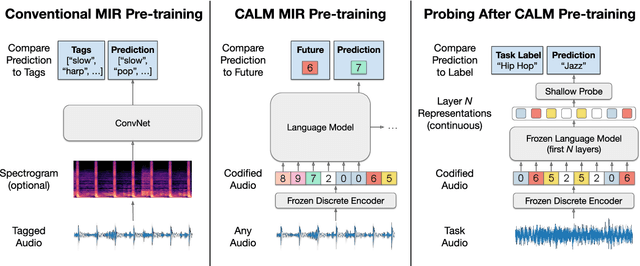
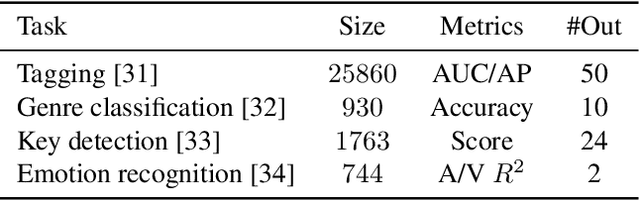
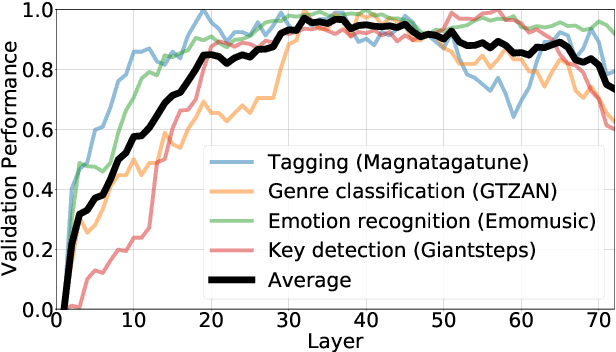

We demonstrate that language models pre-trained on codified (discretely-encoded) music audio learn representations that are useful for downstream MIR tasks. Specifically, we explore representations from Jukebox (Dhariwal et al. 2020): a music generation system containing a language model trained on codified audio from 1M songs. To determine if Jukebox's representations contain useful information for MIR, we use them as input features to train shallow models on several MIR tasks. Relative to representations from conventional MIR models which are pre-trained on tagging, we find that using representations from Jukebox as input features yields 30% stronger performance on average across four MIR tasks: tagging, genre classification, emotion recognition, and key detection. For key detection, we observe that representations from Jukebox are considerably stronger than those from models pre-trained on tagging, suggesting that pre-training via codified audio language modeling may address blind spots in conventional approaches. We interpret the strength of Jukebox's representations as evidence that modeling audio instead of tags provides richer representations for MIR.