 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodified audio language modeling learns useful representations for music information retrieval
Paper and Code
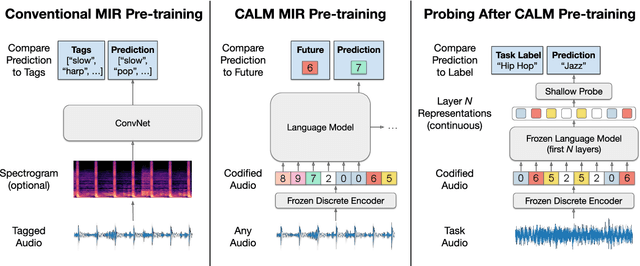
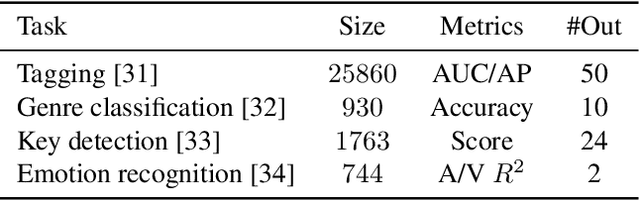
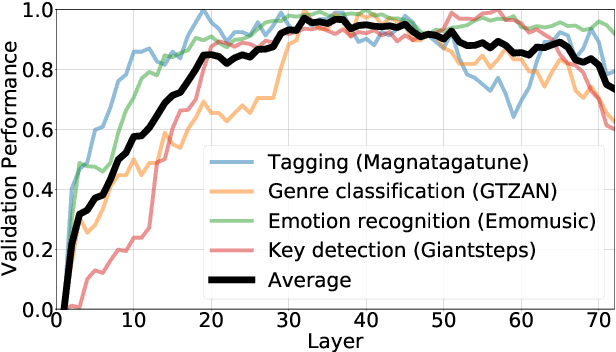

We demonstrate that language models pre-trained on codified (discretely-encoded) music audio learn representations that are useful for downstream MIR tasks. Specifically, we explore representations from Jukebox (Dhariwal et al. 2020): a music generation system containing a language model trained on codified audio from 1M songs. To determine if Jukebox's representations contain useful information for MIR, we use them as input features to train shallow models on several MIR tasks. Relative to representations from conventional MIR models which are pre-trained on tagging, we find that using representations from Jukebox as input features yields 30% stronger performance on average across four MIR tasks: tagging, genre classification, emotion recognition, and key detection. For key detection, we observe that representations from Jukebox are considerably stronger than those from models pre-trained on tagging, suggesting that pre-training via codified audio language modeling may address blind spots in conventional approaches. We interpret the strength of Jukebox's representations as evidence that modeling audio instead of tags provides richer representations for MIR.