 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating General User Models from Computer Use
May 19, 2025Human-computer interaction has long imagined technology that understands us-from our preferences and habits, to the timing and purpose of our everyday actions. Yet current user models remain fragmented, narrowly tailored to specific apps, and incapable of the flexible reasoning required to fulfill these visions. This paper presents an architecture for a general user model (GUM) that learns about you by observing any interaction you have with your computer. The GUM takes as input any unstructured observation of a user (e.g., device screenshots) and constructs confidence-weighted propositions that capture user knowledge and preferences. GUMs can infer that a user is preparing for a wedding they're attending from messages with a friend. Or recognize that a user is struggling with a collaborator's feedback on a draft by observing multiple stalled edits and a switch to reading related work. GUMs introduce an architecture that infers new propositions about a user from multimodal observations, retrieves related propositions for context, and continuously revises existing propositions. To illustrate the breadth of applications that GUMs enable, we demonstrate how they augment chat-based assistants with context, manage OS notifications to selectively surface important information, and enable interactive agents that adapt to preferences across apps. We also instantiate proactive assistants (GUMBOs) that discover and execute useful suggestions on a user's behalf using their GUM. In our evaluations, we find that GUMs make calibrated and accurate inferences about users, and that assistants built on GUMs proactively identify and perform actions that users wouldn't think to request explicitly. Altogether, GUMs introduce methods that leverage multimodal models to understand unstructured context, enabling long-standing visions of HCI and entirely new interactive systems that anticipate user needs.
More than Marketing? On the Information Value of AI Benchmarks for Practitioners
Dec 07, 2024Public AI benchmark results are widely broadcast by model developers as indicators of model quality within a growing and competitive market. However, these advertised scores do not necessarily reflect the traits of interest to those who will ultimately apply AI models. In this paper, we seek to understand if and how AI benchmarks are used to inform decision-making. Based on the analyses of interviews with 19 individuals who have used, or decided against using, benchmarks in their day-to-day work, we find that across these settings, participants use benchmarks as a signal of relative performance difference between models. However, whether this signal was considered a definitive sign of model superiority, sufficient for downstream decisions, varied. In academia, public benchmarks were generally viewed as suitable measures for capturing research progress. By contrast, in both product and policy, benchmarks -- even those developed internally for specific tasks -- were often found to be inadequate for informing substantive decisions. Of the benchmarks deemed unsatisfactory, respondents reported that their goals were neither well-defined nor reflective of real-world use. Based on the study results, we conclude that effective benchmarks should provide meaningful, real-world evaluations, incorporate domain expertise, and maintain transparency in scope and goals. They must capture diverse, task-relevant capabilities, be challenging enough to avoid quick saturation, and account for trade-offs in model performance rather than relying on a single score. Additionally, proprietary data collection and contamination prevention are critical for producing reliable and actionable results. By adhering to these criteria, benchmarks can move beyond mere marketing tricks into robust evaluative frameworks.
Generative Agent Simulations of 1,000 People
Nov 15, 2024



The promise of human behavioral simulation--general-purpose computational agents that replicate human behavior across domains--could enable broad applications in policymaking and social science. We present a novel agent architecture that simulates the attitudes and behaviors of 1,052 real individuals--applying large language models to qualitative interviews about their lives, then measuring how well these agents replicate the attitudes and behaviors of the individuals that they represent. The generative agents replicate participants' responses on the General Social Survey 85% as accurately as participants replicate their own answers two weeks later, and perform comparably in predicting personality traits and outcomes in experimental replications. Our architecture reduces accuracy biases across racial and ideological groups compared to agents given demographic descriptions. This work provides a foundation for new tools that can help investigate individual and collective behavior.
Concept Induction: Analyzing Unstructured Text with High-Level Concepts Using LLooM
Apr 18, 2024
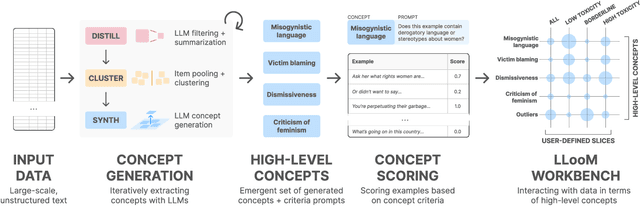


Data analysts have long sought to turn unstructured text data into meaningful concepts. Though common, topic modeling and clustering focus on lower-level keywords and require significant interpretative work. We introduce concept induction, a computational process that instead produces high-level concepts, defined by explicit inclusion criteria, from unstructured text. For a dataset of toxic online comments, where a state-of-the-art BERTopic model outputs "women, power, female," concept induction produces high-level concepts such as "Criticism of traditional gender roles" and "Dismissal of women's concerns." We present LLooM, a concept induction algorithm that leverages large language models to iteratively synthesize sampled text and propose human-interpretable concepts of increasing generality. We then instantiate LLooM in a mixed-initiative text analysis tool, enabling analysts to shift their attention from interpreting topics to engaging in theory-driven analysis. Through technical evaluations and four analysis scenarios ranging from literature review to content moderation, we find that LLooM's concepts improve upon the prior art of topic models in terms of quality and data coverage. In expert case studies, LLooM helped researchers to uncover new insights even from familiar datasets, for example by suggesting a previously unnoticed concept of attacks on out-party stances in a political social media dataset.
Social Skill Training with Large Language Models
Apr 05, 2024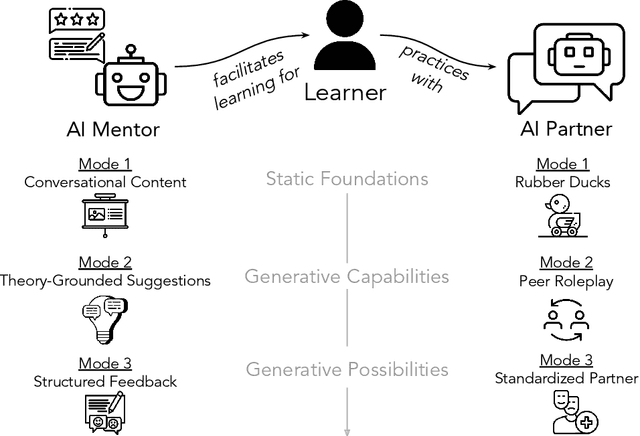
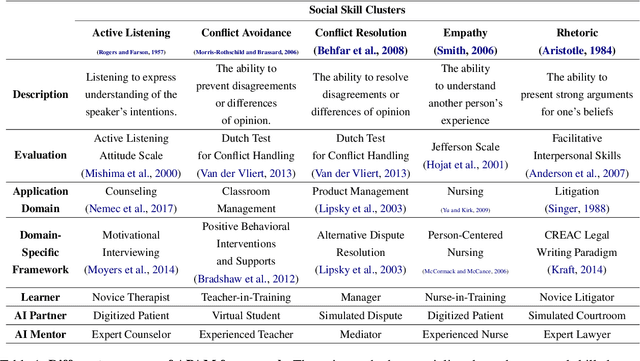
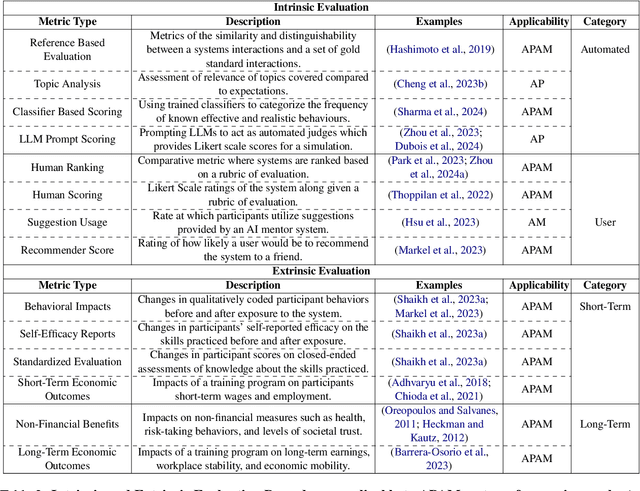
People rely on social skills like conflict resolution to communicate effectively and to thrive in both work and personal life. However, practice environments for social skills are typically out of reach for most people. How can we make social skill training more available, accessible, and inviting? Drawing upon interdisciplinary research from communication and psychology, this perspective paper identifies social skill barriers to enter specialized fields. Then we present a solution that leverages large language models for social skill training via a generic framework. Our AI Partner, AI Mentor framework merges experiential learning with realistic practice and tailored feedback. This work ultimately calls for cross-disciplinary innovation to address the broader implications for workforce development and social equality.
Clarify: Improving Model Robustness With Natural Language Corrections
Feb 06, 2024



In supervised learning, models are trained to extract correlations from a static dataset. This often leads to models that rely on high-level misconceptions. To prevent such misconceptions, we must necessarily provide additional information beyond the training data. Existing methods incorporate forms of additional instance-level supervision, such as labels for spurious features or additional labeled data from a balanced distribution. Such strategies can become prohibitively costly for large-scale datasets since they require additional annotation at a scale close to the original training data. We hypothesize that targeted natural language feedback about a model's misconceptions is a more efficient form of additional supervision. We introduce Clarify, a novel interface and method for interactively correcting model misconceptions. Through Clarify, users need only provide a short text description to describe a model's consistent failure patterns. Then, in an entirely automated way, we use such descriptions to improve the training process by reweighting the training data or gathering additional targeted data. Our user studies show that non-expert users can successfully describe model misconceptions via Clarify, improving worst-group accuracy by an average of 17.1% in two datasets. Additionally, we use Clarify to find and rectify 31 novel hard subpopulations in the ImageNet dataset, improving minority-split accuracy from 21.1% to 28.7%.
Rehearsal: Simulating Conflict to Teach Conflict Resolution
Sep 21, 2023



Interpersonal conflict is an uncomfortable but unavoidable fact of life. Navigating conflict successfully is a skill -- one that can be learned through deliberate practice -- but few have access to effective training or feedback. To expand this access, we introduce Rehearsal, a system that allows users to rehearse conflicts with a believable simulated interlocutor, explore counterfactual "what if?" scenarios to identify alternative conversational paths, and learn through feedback on how and when to apply specific conflict strategies. Users can utilize Rehearsal to practice handling a variety of predefined conflict scenarios, from office disputes to relationship issues, or they can choose to create their own. To enable Rehearsal, we develop IRP prompting, a method of conditioning output of a large language model on the influential Interest-Rights-Power (IRP) theory from conflict resolution. Rehearsal uses IRP to generate utterances grounded in conflict resolution theory, guiding users towards counterfactual conflict resolution strategies that help de-escalate difficult conversations. In a between-subjects evaluation, 40 participants engaged in an actual conflict with a confederate after training. Compared to a control group with lecture material covering the same IRP theory, participants with simulated training from Rehearsal significantly improved their performance in the unaided conflict: they reduced their use of escalating competitive strategies by an average of 67%, while doubling their use of cooperative strategies. Overall, Rehearsal highlights the potential effectiveness of language models as tools for learning and practicing interpersonal skills.
Embedding Democratic Values into Social Media AIs via Societal Objective Functions
Jul 26, 2023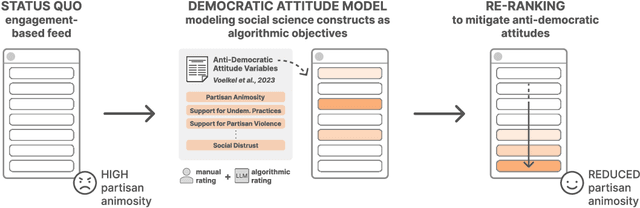

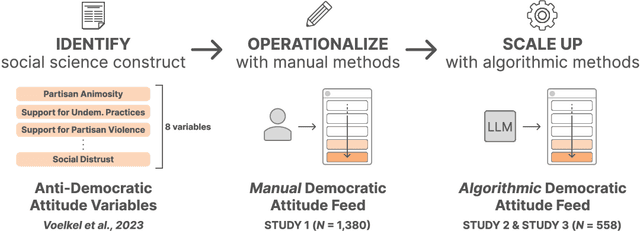
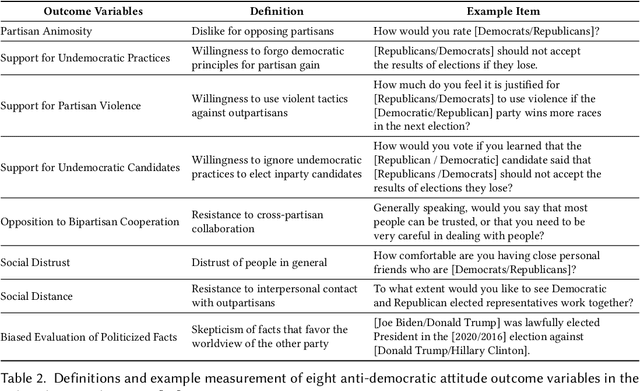
Can we design artificial intelligence (AI) systems that rank our social media feeds to consider democratic values such as mitigating partisan animosity as part of their objective functions? We introduce a method for translating established, vetted social scientific constructs into AI objective functions, which we term societal objective functions, and demonstrate the method with application to the political science construct of anti-democratic attitudes. Traditionally, we have lacked observable outcomes to use to train such models, however, the social sciences have developed survey instruments and qualitative codebooks for these constructs, and their precision facilitates translation into detailed prompts for large language models. We apply this method to create a democratic attitude model that estimates the extent to which a social media post promotes anti-democratic attitudes, and test this democratic attitude model across three studies. In Study 1, we first test the attitudinal and behavioral effectiveness of the intervention among US partisans (N=1,380) by manually annotating (alpha=.895) social media posts with anti-democratic attitude scores and testing several feed ranking conditions based on these scores. Removal (d=.20) and downranking feeds (d=.25) reduced participants' partisan animosity without compromising their experience and engagement. In Study 2, we scale up the manual labels by creating the democratic attitude model, finding strong agreement with manual labels (rho=.75). Finally, in Study 3, we replicate Study 1 using the democratic attitude model instead of manual labels to test its attitudinal and behavioral impact (N=558), and again find that the feed downranking using the societal objective function reduced partisan animosity (d=.25). This method presents a novel strategy to draw on social science theory and methods to mitigate societal harms in social media AIs.
Generative Agents: Interactive Simulacra of Human Behavior
Apr 07, 2023Believable proxies of human behavior can empower interactive applications ranging from immersive environments to rehearsal spaces for interpersonal communication to prototyping tools. In this paper, we introduce generative agents--computational software agents that simulate believable human behavior. Generative agents wake up, cook breakfast, and head to work; artists paint, while authors write; they form opinions, notice each other, and initiate conversations; they remember and reflect on days past as they plan the next day. To enable generative agents, we describe an architecture that extends a large language model to store a complete record of the agent's experiences using natural language, synthesize those memories over time into higher-level reflections, and retrieve them dynamically to plan behavior. We instantiate generative agents to populate an interactive sandbox environment inspired by The Sims, where end users can interact with a small town of twenty five agents using natural language. In an evaluation, these generative agents produce believable individual and emergent social behaviors: for example, starting with only a single user-specified notion that one agent wants to throw a Valentine's Day party, the agents autonomously spread invitations to the party over the next two days, make new acquaintances, ask each other out on dates to the party, and coordinate to show up for the party together at the right time. We demonstrate through ablation that the components of our agent architecture--observation, planning, and reflection--each contribute critically to the believability of agent behavior. By fusing large language models with computational, interactive agents, this work introduces architectural and interaction patterns for enabling believable simulations of human behavior.
Model Sketching: Centering Concepts in Early-Stage Machine Learning Model Design
Mar 06, 2023



Machine learning practitioners often end up tunneling on low-level technical details like model architectures and performance metrics. Could early model development instead focus on high-level questions of which factors a model ought to pay attention to? Inspired by the practice of sketching in design, which distills ideas to their minimal representation, we introduce model sketching: a technical framework for iteratively and rapidly authoring functional approximations of a machine learning model's decision-making logic. Model sketching refocuses practitioner attention on composing high-level, human-understandable concepts that the model is expected to reason over (e.g., profanity, racism, or sarcasm in a content moderation task) using zero-shot concept instantiation. In an evaluation with 17 ML practitioners, model sketching reframed thinking from implementation to higher-level exploration, prompted iteration on a broader range of model designs, and helped identify gaps in the problem formulation$\unicode{x2014}$all in a fraction of the time ordinarily required to build a model.