 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Democratic Values into Social Media AIs via Societal Objective Functions
Jul 26, 2023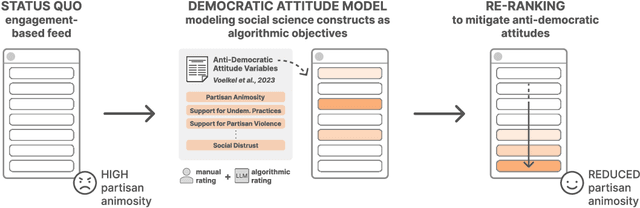

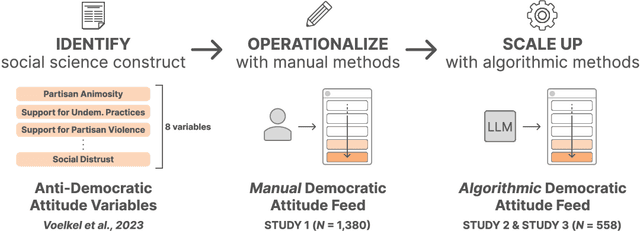
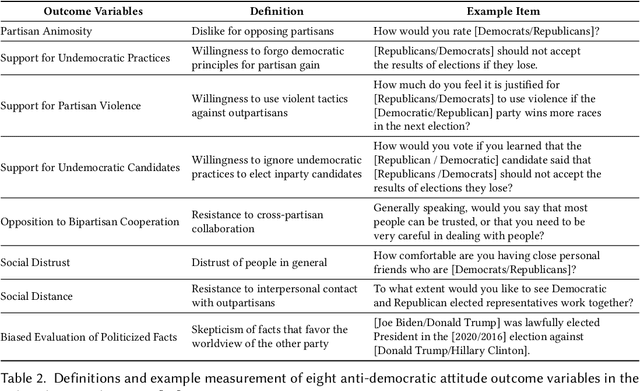
Can we design artificial intelligence (AI) systems that rank our social media feeds to consider democratic values such as mitigating partisan animosity as part of their objective functions? We introduce a method for translating established, vetted social scientific constructs into AI objective functions, which we term societal objective functions, and demonstrate the method with application to the political science construct of anti-democratic attitudes. Traditionally, we have lacked observable outcomes to use to train such models, however, the social sciences have developed survey instruments and qualitative codebooks for these constructs, and their precision facilitates translation into detailed prompts for large language models. We apply this method to create a democratic attitude model that estimates the extent to which a social media post promotes anti-democratic attitudes, and test this democratic attitude model across three studies. In Study 1, we first test the attitudinal and behavioral effectiveness of the intervention among US partisans (N=1,380) by manually annotating (alpha=.895) social media posts with anti-democratic attitude scores and testing several feed ranking conditions based on these scores. Removal (d=.20) and downranking feeds (d=.25) reduced participants' partisan animosity without compromising their experience and engagement. In Study 2, we scale up the manual labels by creating the democratic attitude model, finding strong agreement with manual labels (rho=.75). Finally, in Study 3, we replicate Study 1 using the democratic attitude model instead of manual labels to test its attitudinal and behavioral impact (N=558), and again find that the feed downranking using the societal objective function reduced partisan animosity (d=.25). This method presents a novel strategy to draw on social science theory and methods to mitigate societal harms in social media AIs.
Artificial intelligence in communication impacts language and social relationships
Feb 10, 2021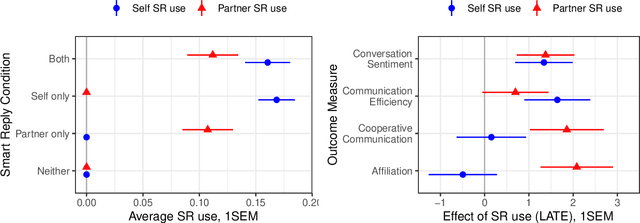
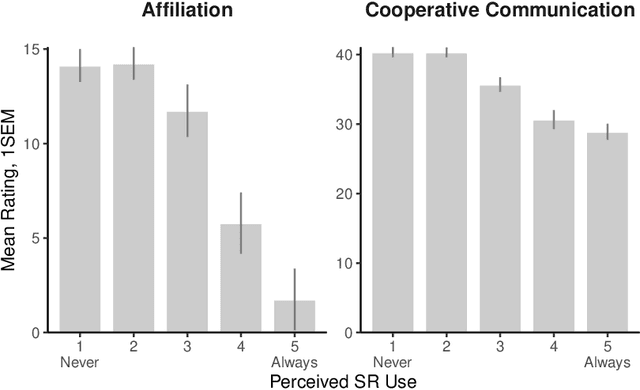
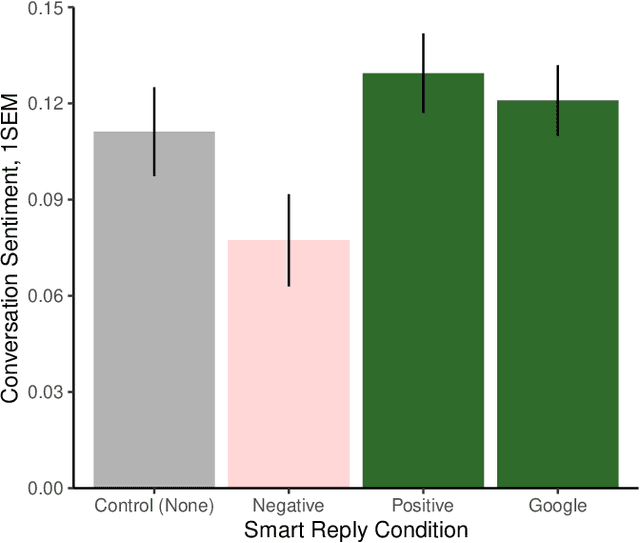
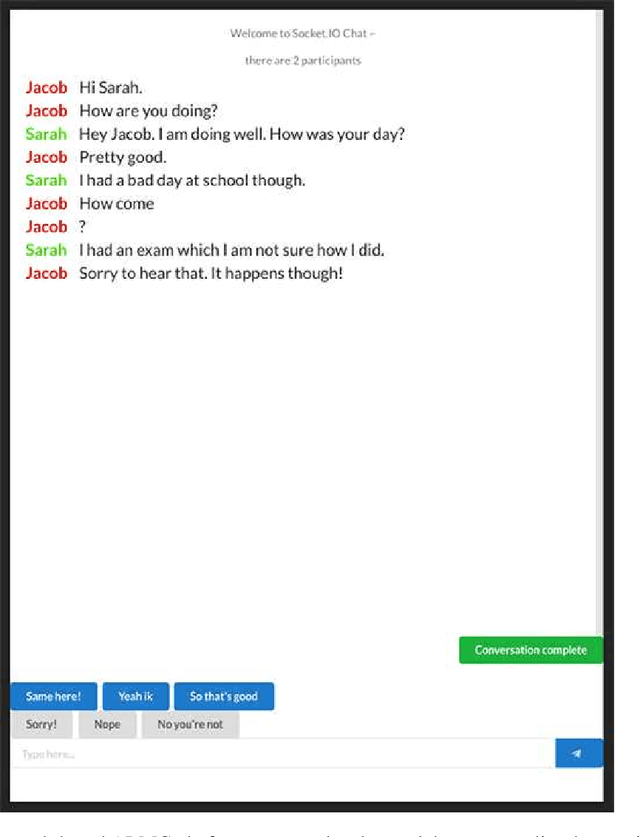
Artificial intelligence (AI) is now widely used to facilitate social interaction, but its impact on social relationships and communication is not well understood. We study the social consequences of one of the most pervasive AI applications: algorithmic response suggestions ("smart replies"). Two randomized experiments (n = 1036) provide evidence that a commercially-deployed AI changes how people interact with and perceive one another in pro-social and anti-social ways. We find that using algorithmic responses increases communication efficiency, use of positive emotional language, and positive evaluations by communication partners. However, consistent with common assumptions about the negative implications of AI, people are evaluated more negatively if they are suspected to be using algorithmic responses. Thus, even though AI can increase communication efficiency and improve interpersonal perceptions, it risks changing users' language production and continues to be viewed negatively.
Estimating the Prevalence of Deception in Online Review Communities
Apr 12, 2012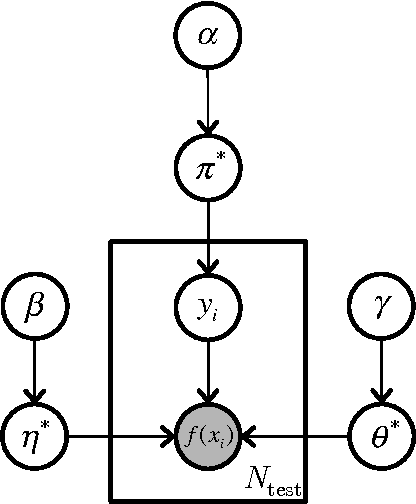
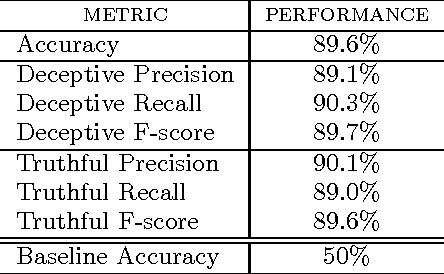
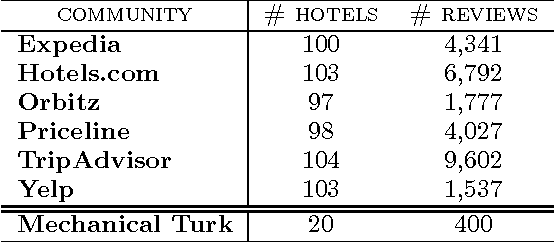
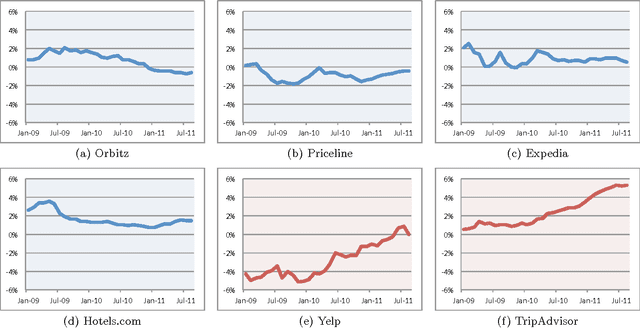
Consumers' purchase decisions are increasingly influenced by user-generated online reviews. Accordingly, there has been growing concern about the potential for posting "deceptive opinion spam" -- fictitious reviews that have been deliberately written to sound authentic, to deceive the reader. But while this practice has received considerable public attention and concern, relatively little is known about the actual prevalence, or rate, of deception in online review communities, and less still about the factors that influence it. We propose a generative model of deception which, in conjunction with a deception classifier, we use to explore the prevalence of deception in six popular online review communities: Expedia, Hotels.com, Orbitz, Priceline, TripAdvisor, and Yelp. We additionally propose a theoretical model of online reviews based on economic signaling theory, in which consumer reviews diminish the inherent information asymmetry between consumers and producers, by acting as a signal to a product's true, unknown quality. We find that deceptive opinion spam is a growing problem overall, but with different growth rates across communities. These rates, we argue, are driven by the different signaling costs associated with deception for each review community, e.g., posting requirements. When measures are taken to increase signaling cost, e.g., filtering reviews written by first-time reviewers, deception prevalence is effectively reduced.