 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding Democratic Values into Social Media AIs via Societal Objective Functions
Paper and Code
Jul 26, 2023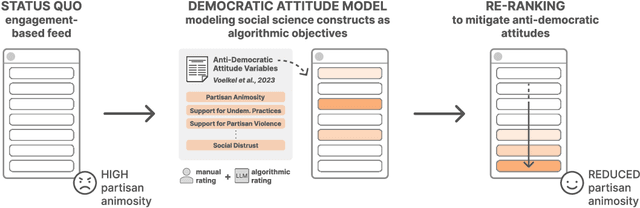

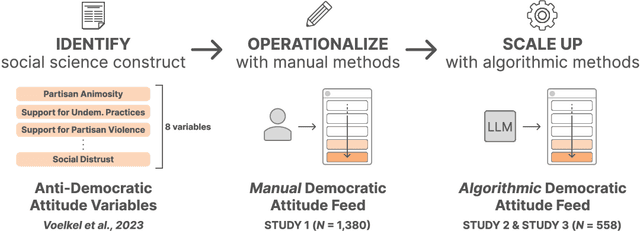
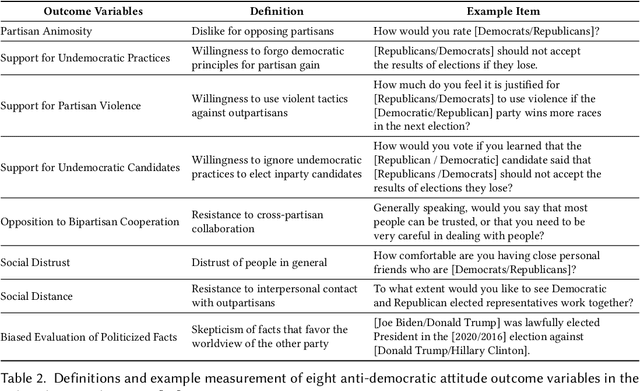
Can we design artificial intelligence (AI) systems that rank our social media feeds to consider democratic values such as mitigating partisan animosity as part of their objective functions? We introduce a method for translating established, vetted social scientific constructs into AI objective functions, which we term societal objective functions, and demonstrate the method with application to the political science construct of anti-democratic attitudes. Traditionally, we have lacked observable outcomes to use to train such models, however, the social sciences have developed survey instruments and qualitative codebooks for these constructs, and their precision facilitates translation into detailed prompts for large language models. We apply this method to create a democratic attitude model that estimates the extent to which a social media post promotes anti-democratic attitudes, and test this democratic attitude model across three studies. In Study 1, we first test the attitudinal and behavioral effectiveness of the intervention among US partisans (N=1,380) by manually annotating (alpha=.895) social media posts with anti-democratic attitude scores and testing several feed ranking conditions based on these scores. Removal (d=.20) and downranking feeds (d=.25) reduced participants' partisan animosity without compromising their experience and engagement. In Study 2, we scale up the manual labels by creating the democratic attitude model, finding strong agreement with manual labels (rho=.75). Finally, in Study 3, we replicate Study 1 using the democratic attitude model instead of manual labels to test its attitudinal and behavioral impact (N=558), and again find that the feed downranking using the societal objective function reduced partisan animosity (d=.25). This method presents a novel strategy to draw on social science theory and methods to mitigate societal harms in social media AIs.