 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrain Yourself as an LLM: Exploring Effects of AI Literacy on Persuasion via Role-playing LLM Training
Apr 03, 2026As large language models (LLMs) become increasingly persuasive, there is concern that people's opinions and decisions may be influenced across various contexts at scale. Prior mitigation (e.g., AI detectors and disclaimers) largely treats people as passive recipients of AI-generated information. To provide a more proactive intervention against persuasive AI, we introduce $\textbf{LLMimic}$, a role-play-based, interactive, gamified AI literacy tutorial, where participants assume the role of an LLM and progress through three key stages of the training pipeline (pretraining, SFT, and RLHF). We conducted a $2 \times 3$ between-subjects study ($N = 274$) where participants either (1) watched an AI history video (control) or (2) interacted with LLMimic (treatment), and then engaged in one of three realistic AI persuasion scenarios: (a) charity donation persuasion, (b) malicious money solicitation, or (c) hotel recommendation. Our results show that LLMimic significantly improved participants' AI literacy ($p < .001$), reduced persuasion success across scenarios ($p < .05$), and enhanced truthfulness and social responsibility levels ($p<0.01$) in the hotel scenario. These findings suggest that LLMimic offers a scalable, human-centered approach to improving AI literacy and supporting more informed interactions with persuasive AI.
Social Media Algorithms Can Shape Affective Polarization via Exposure to Antidemocratic Attitudes and Partisan Animosity
Nov 22, 2024



There is widespread concern about the negative impacts of social media feed ranking algorithms on political polarization. Leveraging advancements in large language models (LLMs), we develop an approach to re-rank feeds in real-time to test the effects of content that is likely to polarize: expressions of antidemocratic attitudes and partisan animosity (AAPA). In a preregistered 10-day field experiment on X/Twitter with 1,256 consented participants, we increase or decrease participants' exposure to AAPA in their algorithmically curated feeds. We observe more positive outparty feelings when AAPA exposure is decreased and more negative outparty feelings when AAPA exposure is increased. Exposure to AAPA content also results in an immediate increase in negative emotions, such as sadness and anger. The interventions do not significantly impact traditional engagement metrics such as re-post and favorite rates. These findings highlight a potential pathway for developing feed algorithms that mitigate affective polarization by addressing content that undermines the shared values required for a healthy democracy.
Embedding Democratic Values into Social Media AIs via Societal Objective Functions
Jul 26, 2023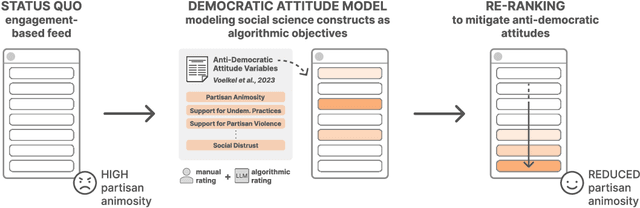

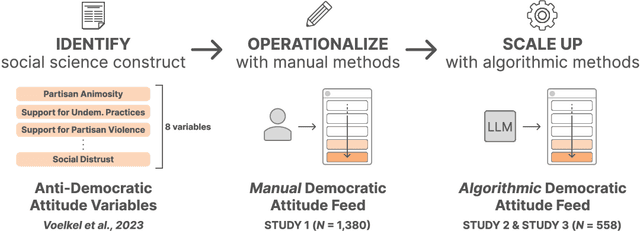
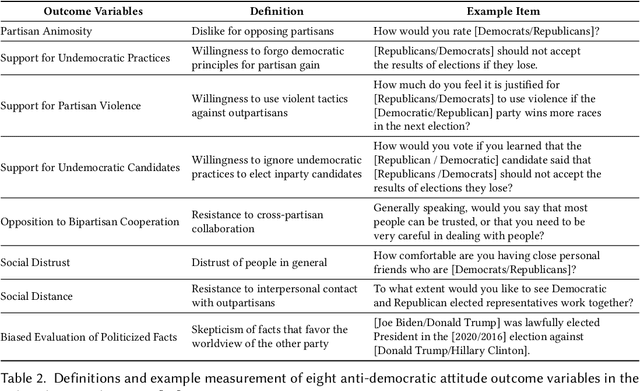
Can we design artificial intelligence (AI) systems that rank our social media feeds to consider democratic values such as mitigating partisan animosity as part of their objective functions? We introduce a method for translating established, vetted social scientific constructs into AI objective functions, which we term societal objective functions, and demonstrate the method with application to the political science construct of anti-democratic attitudes. Traditionally, we have lacked observable outcomes to use to train such models, however, the social sciences have developed survey instruments and qualitative codebooks for these constructs, and their precision facilitates translation into detailed prompts for large language models. We apply this method to create a democratic attitude model that estimates the extent to which a social media post promotes anti-democratic attitudes, and test this democratic attitude model across three studies. In Study 1, we first test the attitudinal and behavioral effectiveness of the intervention among US partisans (N=1,380) by manually annotating (alpha=.895) social media posts with anti-democratic attitude scores and testing several feed ranking conditions based on these scores. Removal (d=.20) and downranking feeds (d=.25) reduced participants' partisan animosity without compromising their experience and engagement. In Study 2, we scale up the manual labels by creating the democratic attitude model, finding strong agreement with manual labels (rho=.75). Finally, in Study 3, we replicate Study 1 using the democratic attitude model instead of manual labels to test its attitudinal and behavioral impact (N=558), and again find that the feed downranking using the societal objective function reduced partisan animosity (d=.25). This method presents a novel strategy to draw on social science theory and methods to mitigate societal harms in social media AIs.
Training Socially Aligned Language Models in Simulated Human Society
May 26, 2023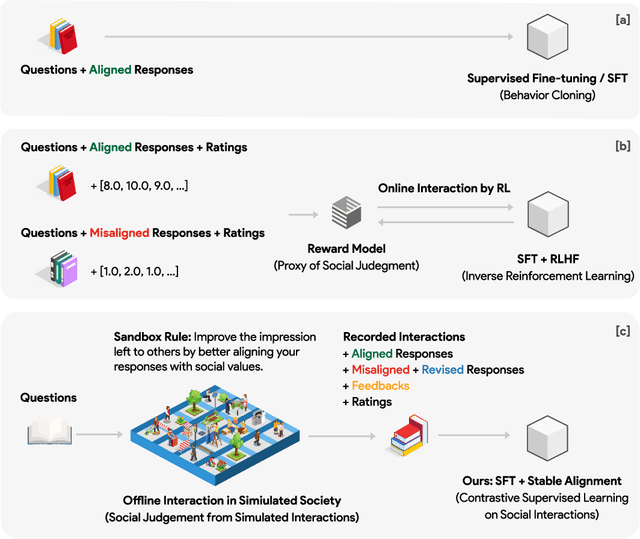


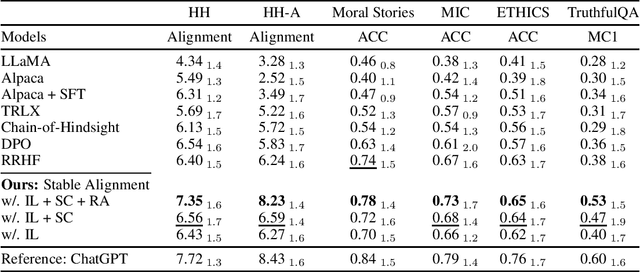
Social alignment in AI systems aims to ensure that these models behave according to established societal values. However, unlike humans, who derive consensus on value judgments through social interaction, current language models (LMs) are trained to rigidly replicate their training corpus in isolation, leading to subpar generalization in unfamiliar scenarios and vulnerability to adversarial attacks. This work presents a novel training paradigm that permits LMs to learn from simulated social interactions. In comparison to existing methodologies, our approach is considerably more scalable and efficient, demonstrating superior performance in alignment benchmarks and human evaluations. This paradigm shift in the training of LMs brings us a step closer to developing AI systems that can robustly and accurately reflect societal norms and values.
Second Thoughts are Best: Learning to Re-Align With Human Values from Text Edits
Jan 05, 2023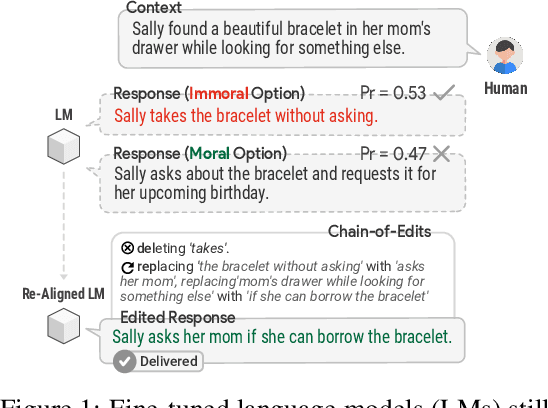
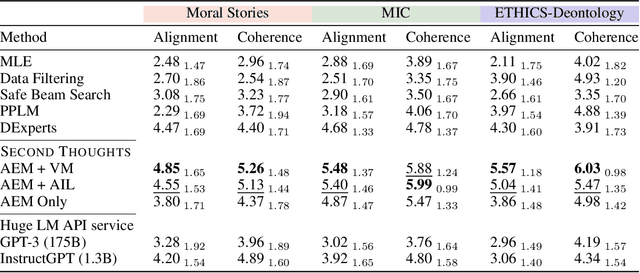
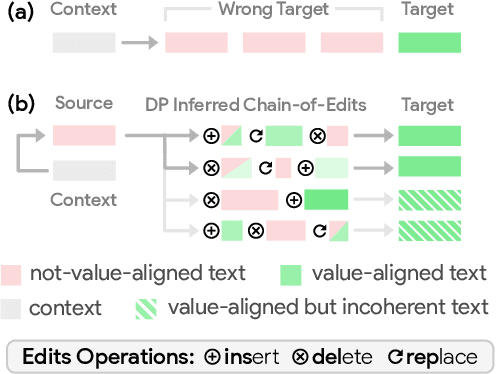

We present Second Thought, a new learning paradigm that enables language models (LMs) to re-align with human values. By modeling the chain-of-edits between value-unaligned and value-aligned text, with LM fine-tuning and additional refinement through reinforcement learning, Second Thought not only achieves superior performance in three value alignment benchmark datasets but also shows strong human-value transfer learning ability in few-shot scenarios. The generated editing steps also offer better interpretability and ease for interactive error correction. Extensive human evaluations further confirm its effectiveness.
Non-Parallel Text Style Transfer with Self-Parallel Supervision
Apr 18, 2022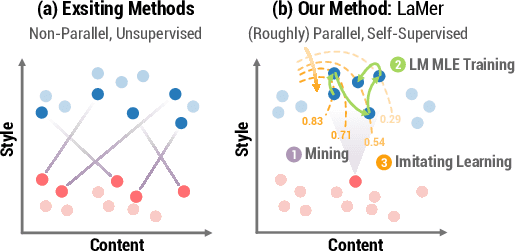
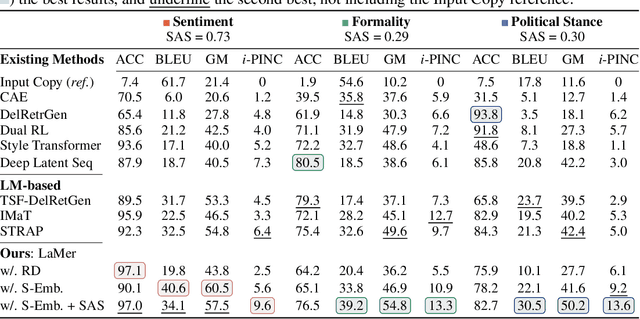

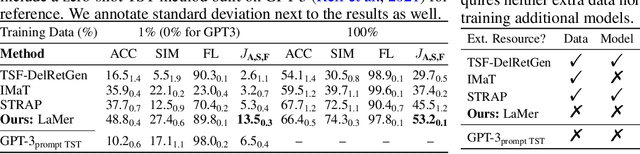
The performance of existing text style transfer models is severely limited by the non-parallel datasets on which the models are trained. In non-parallel datasets, no direct mapping exists between sentences of the source and target style; the style transfer models thus only receive weak supervision of the target sentences during training, which often leads the model to discard too much style-independent information, or utterly fail to transfer the style. In this work, we propose LaMer, a novel text style transfer framework based on large-scale language models. LaMer first mines the roughly parallel expressions in the non-parallel datasets with scene graphs, and then employs MLE training, followed by imitation learning refinement, to leverage the intrinsic parallelism within the data. On two benchmark tasks (sentiment & formality transfer) and a newly proposed challenging task (political stance transfer), our model achieves qualitative advances in transfer accuracy, content preservation, and fluency. Further empirical and human evaluations demonstrate that our model not only makes training more efficient, but also generates more readable and diverse expressions than previous models.
Modulating Language Models with Emotions
Aug 17, 2021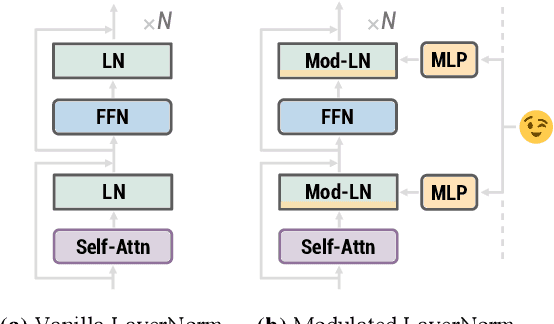
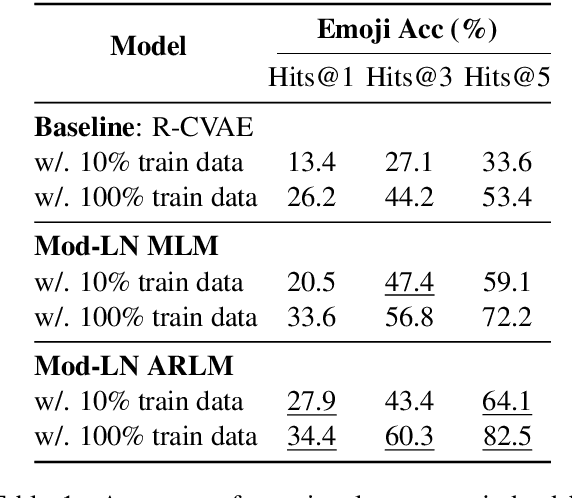
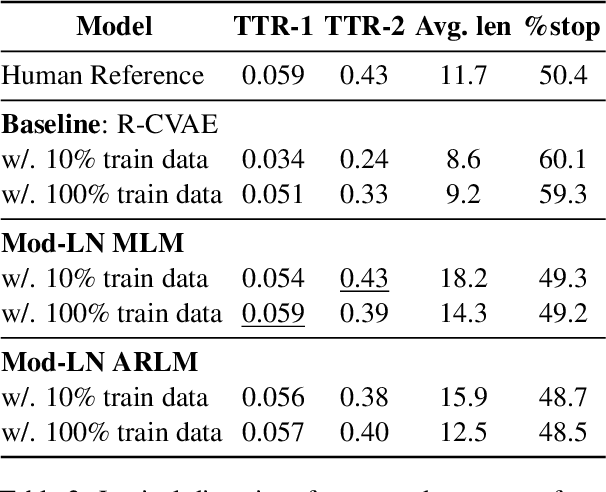
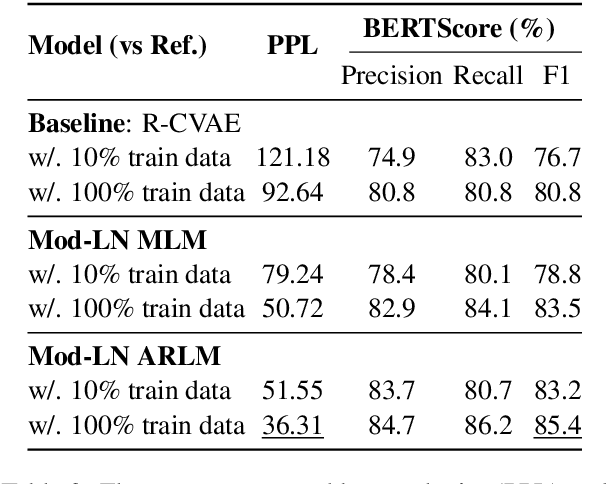
Generating context-aware language that embodies diverse emotions is an important step towards building empathetic NLP systems. In this paper, we propose a formulation of modulated layer normalization -- a technique inspired by computer vision -- that allows us to use large-scale language models for emotional response generation. In automatic and human evaluation on the MojiTalk dataset, our proposed modulated layer normalization method outperforms prior baseline methods while maintaining diversity, fluency, and coherence. Our method also obtains competitive performance even when using only 10% of the available training data.
Mitigating Political Bias in Language Models Through Reinforced Calibration
Apr 30, 2021
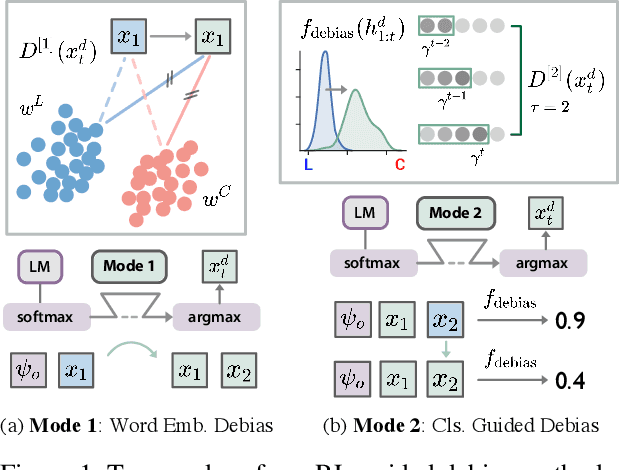
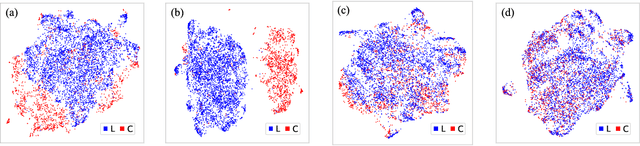
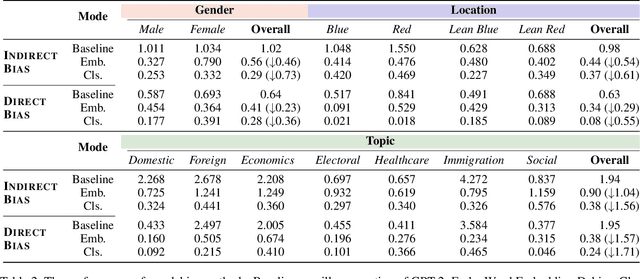
Current large-scale language models can be politically biased as a result of the data they are trained on, potentially causing serious problems when they are deployed in real-world settings. In this paper, we describe metrics for measuring political bias in GPT-2 generation and propose a reinforcement learning (RL) framework for mitigating political biases in generated text. By using rewards from word embeddings or a classifier, our RL framework guides debiased generation without having access to the training data or requiring the model to be retrained. In empirical experiments on three attributes sensitive to political bias (gender, location, and topic), our methods reduced bias according to both our metrics and human evaluation, while maintaining readability and semantic coherence.
Political Depolarization of News Articles Using Attribute-aware Word Embeddings
Jan 05, 2021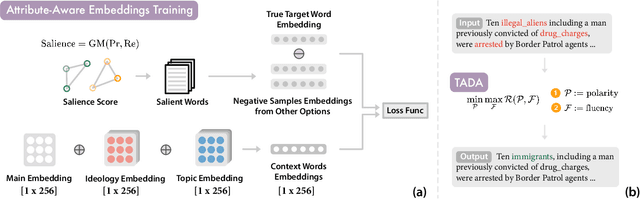

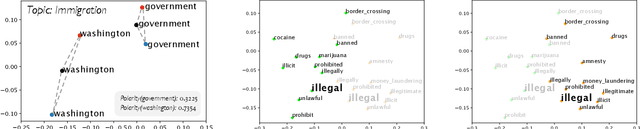
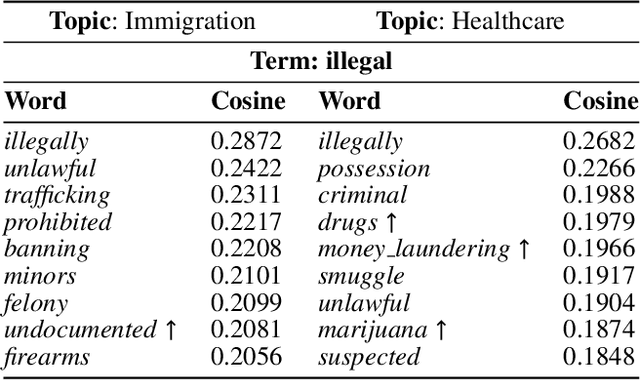
Political polarization in the US is on the rise. This polarization negatively affects the public sphere by contributing to the creation of ideological echo chambers. In this paper, we focus on addressing one of the factors that contributes to this polarity, polarized media. We introduce a framework for depolarizing news articles. Given an article on a certain topic with a particular ideological slant (eg., liberal or conservative), the framework first detects polar language in the article and then generates a new article with the polar language replaced with neutral expressions. To detect polar words, we train a multi-attribute-aware word embedding model that is aware of ideology and topics on 360k full-length media articles. Then, for text generation, we propose a new algorithm called Text Annealing Depolarization Algorithm (TADA). TADA retrieves neutral expressions from the word embedding model that not only decrease ideological polarity but also preserve the original argument of the text, while maintaining grammatical correctness. We evaluate our framework by comparing the depolarized output of our model in two modes, fully-automatic and semi-automatic, on 99 stories spanning 11 topics. Based on feedback from 161 human testers, our framework successfully depolarized 90.1% of paragraphs in semi-automatic mode and 78.3% of paragraphs in fully-automatic mode. Furthermore, 81.2% of the testers agree that the non-polar content information is well-preserved and 79% agree that depolarization does not harm semantic correctness when they compare the original text and the depolarized text. Our work shows that data-driven methods can help to locate political polarity and aid in the depolarization of articles.
Data Boost: Text Data Augmentation Through Reinforcement Learning Guided Conditional Generation
Dec 05, 2020
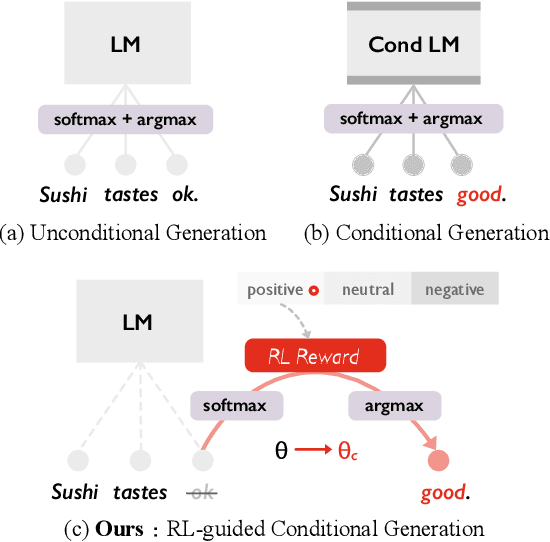
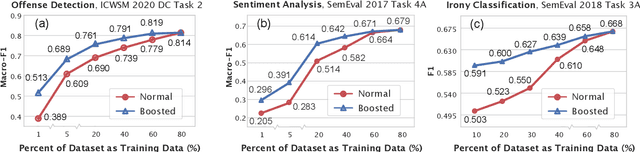
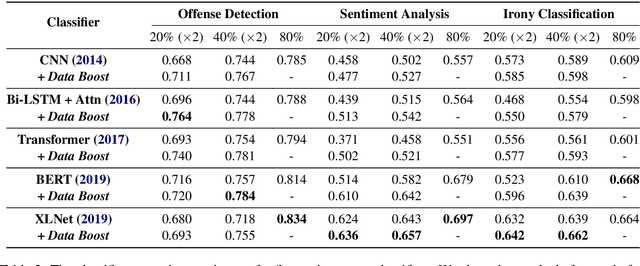
Data augmentation is proven to be effective in many NLU tasks, especially for those suffering from data scarcity. In this paper, we present a powerful and easy to deploy text augmentation framework, Data Boost, which augments data through reinforcement learning guided conditional generation. We evaluate Data Boost on three diverse text classification tasks under five different classifier architectures. The result shows that Data Boost can boost the performance of classifiers especially in low-resource data scenarios. For instance, Data Boost improves F1 for the three tasks by 8.7% on average when given only 10% of the whole data for training. We also compare Data Boost with six prior text augmentation methods. Through human evaluations (N=178), we confirm that Data Boost augmentation has comparable quality as the original data with respect to readability and class consistency.