 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactive Writers: How Co-Writing with AI Changes How We Engage with Ideas
Mar 11, 2026Emerging experimental evidence shows that writing with AI assistance can change both the views people express in writing and the opinions they hold afterwards. Yet, we lack substantive understanding of procedural and behavioral changes in co-writing with AI that underlie the observed opinion-shaping power of AI writing tools. We conducted a mixed-methods study, combining retrospective interviews with 19 participants about their AI co-writing experience with a quantitative analysis tracing engagement with ideas and opinions in 1{,}291 AI co-writing sessions. Our analysis shows that engaging with the AI's suggestions -- reading them and deciding whether to accept them -- becomes a central activity in the writing process, taking away from more traditional processes of ideation and language generation. As writers often do not complete their own ideation before engaging with suggestions, the suggested ideas and opinions seeded directions that writers then elaborated on. At the same time, writers did not notice the AI's influence and felt in full control of their writing, as they -- in principle -- could always edit the final text. We term this shift \textit{Reactive Writing}: an evaluation-first, suggestion-led writing practice that departs substantially from conventional composing in the presence of AI assistance and is highly vulnerable to AI-induced biases and opinion shifts.
Penalizing Transparency? How AI Disclosure and Author Demographics Shape Human and AI Judgments About Writing
Jul 02, 2025


As AI integrates in various types of human writing, calls for transparency around AI assistance are growing. However, if transparency operates on uneven ground and certain identity groups bear a heavier cost for being honest, then the burden of openness becomes asymmetrical. This study investigates how AI disclosure statement affects perceptions of writing quality, and whether these effects vary by the author's race and gender. Through a large-scale controlled experiment, both human raters (n = 1,970) and LLM raters (n = 2,520) evaluated a single human-written news article while disclosure statements and author demographics were systematically varied. This approach reflects how both human and algorithmic decisions now influence access to opportunities (e.g., hiring, promotion) and social recognition (e.g., content recommendation algorithms). We find that both human and LLM raters consistently penalize disclosed AI use. However, only LLM raters exhibit demographic interaction effects: they favor articles attributed to women or Black authors when no disclosure is present. But these advantages disappear when AI assistance is revealed. These findings illuminate the complex relationships between AI disclosure and author identity, highlighting disparities between machine and human evaluation patterns.
Examining the Prevalence and Dynamics of AI-Generated Media in Art Subreddits
Oct 09, 2024
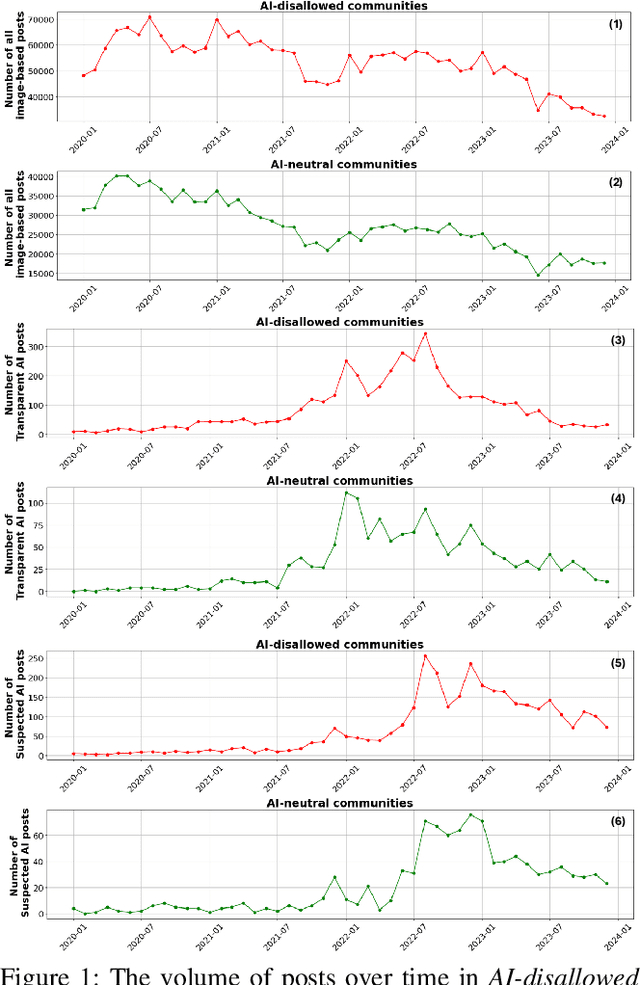
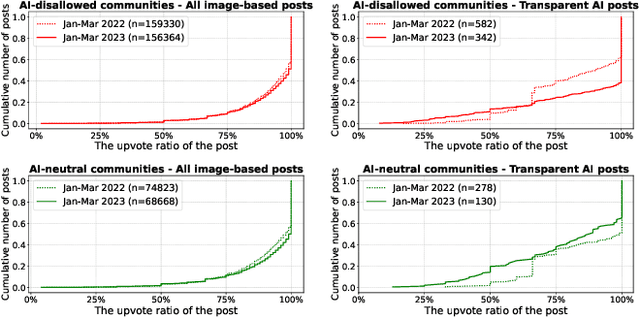
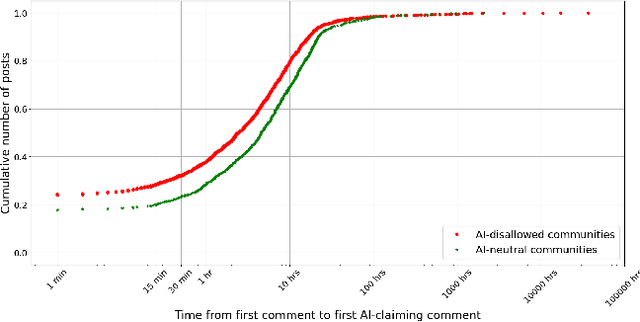
Broadly accessible generative AI models like Dall-E have made it possible for anyone to create compelling visual art. In online communities, the introduction of AI-generated content (AIGC) may impact community dynamics by shifting the kinds of content being posted or the responses to content suspected of being generated by AI. We take steps towards examining the potential impact of AIGC on art-related communities on Reddit. We distinguish between communities that disallow AI content and those without a direct policy. We look at image-based posts made to these communities that are transparently created by AI, or comments in these communities that suspect authors of using generative AI. We find that AI posts (and accusations) have played a very small part in these communities through the end of 2023, accounting for fewer than 0.2% of the image-based posts. Even as the absolute number of author-labelled AI posts dwindles over time, accusations of AI use remain more persistent. We show that AI content is more readily used by newcomers and may help increase participation if it aligns with community rules. However, the tone of comments suspecting AI use by others have become more negative over time, especially in communities that do not have explicit rules about AI. Overall, the results show the changing norms and interactions around AIGC in online communities designated for creativity.
AI Suggestions Homogenize Writing Toward Western Styles and Diminish Cultural Nuances
Sep 17, 2024



Large language models (LLMs) are being increasingly integrated into everyday products and services, such as coding tools and writing assistants. As these embedded AI applications are deployed globally, there is a growing concern that the AI models underlying these applications prioritize Western values. This paper investigates what happens when a Western-centric AI model provides writing suggestions to users from a different cultural background. We conducted a cross-cultural controlled experiment with 118 participants from India and the United States who completed culturally grounded writing tasks with and without AI suggestions. Our analysis reveals that AI provided greater efficiency gains for Americans compared to Indians. Moreover, AI suggestions led Indian participants to adopt Western writing styles, altering not just what is written but also how it is written. These findings show that Western-centric AI models homogenize writing toward Western norms, diminishing nuances that differentiate cultural expression.
Co-Writing with Opinionated Language Models Affects Users' Views
Feb 01, 2023
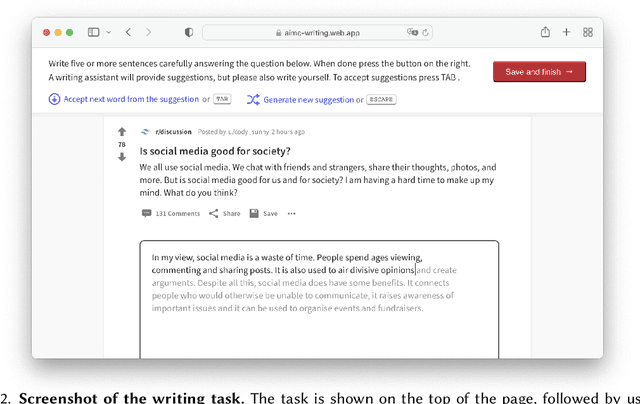
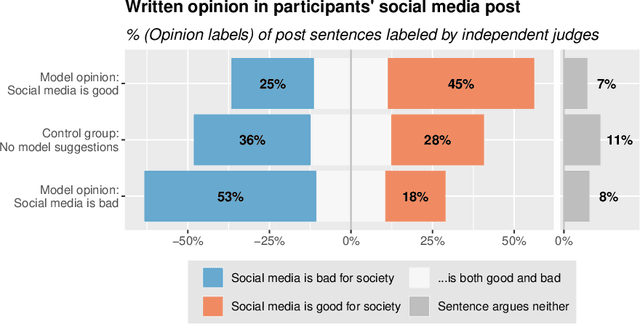
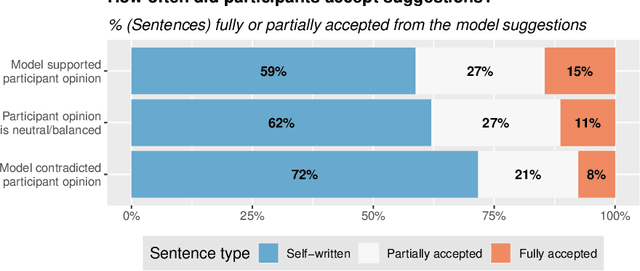
If large language models like GPT-3 preferably produce a particular point of view, they may influence people's opinions on an unknown scale. This study investigates whether a language-model-powered writing assistant that generates some opinions more often than others impacts what users write - and what they think. In an online experiment, we asked participants (N=1,506) to write a post discussing whether social media is good for society. Treatment group participants used a language-model-powered writing assistant configured to argue that social media is good or bad for society. Participants then completed a social media attitude survey, and independent judges (N=500) evaluated the opinions expressed in their writing. Using the opinionated language model affected the opinions expressed in participants' writing and shifted their opinions in the subsequent attitude survey. We discuss the wider implications of our results and argue that the opinions built into AI language technologies need to be monitored and engineered more carefully.
Estimating Exposure to Information on Social Networks
Jul 13, 2022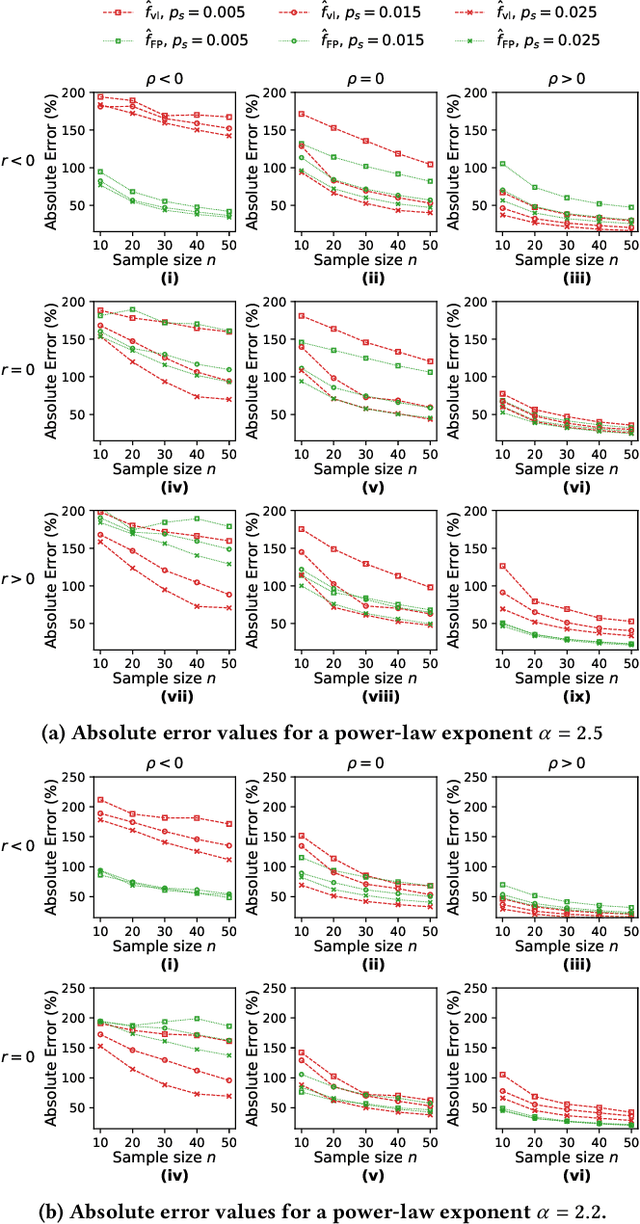
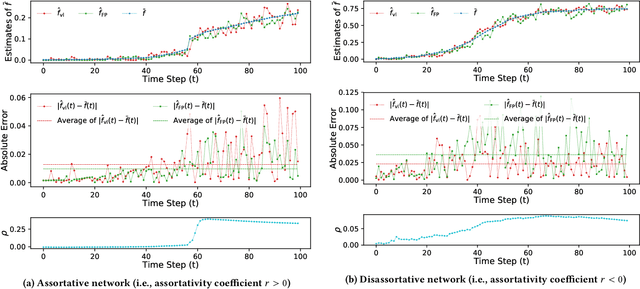
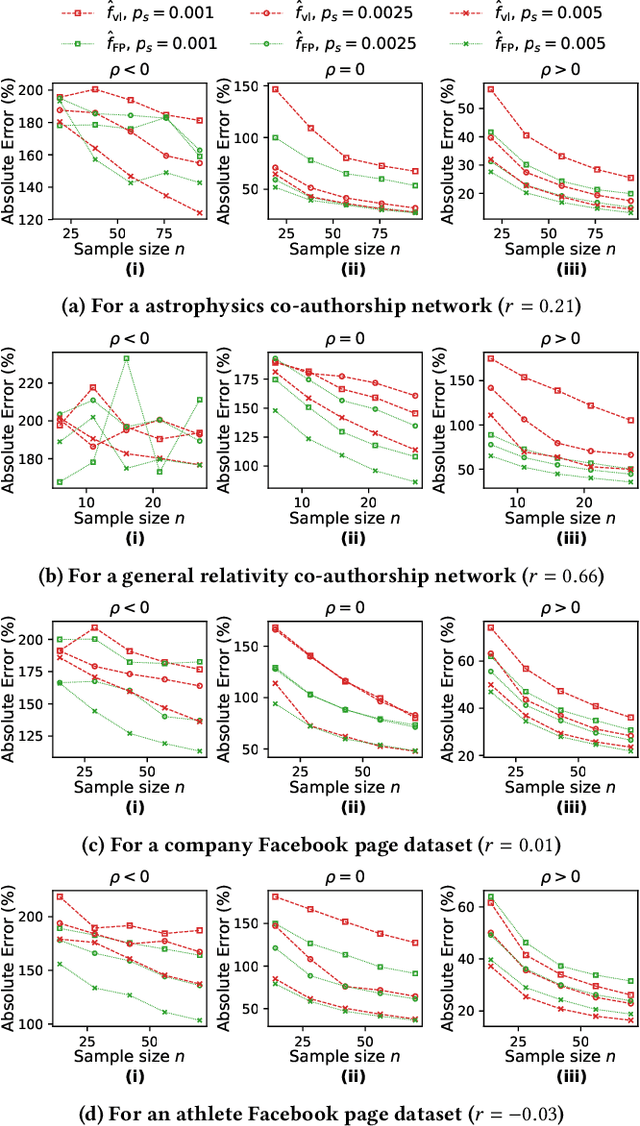
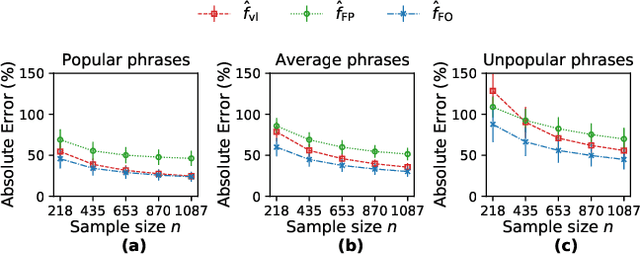
This paper considers the problem of estimating exposure to information in a social network. Given a piece of information (e.g., a URL of a news article on Facebook, a hashtag on Twitter), our aim is to find the fraction of people on the network who have been exposed to it. The exact value of exposure to a piece of information is determined by two features: the structure of the underlying social network and the set of people who shared the piece of information. Often, both features are not publicly available (i.e., access to the two features is limited only to the internal administrators of the platform) and difficult to be estimated from data. As a solution, we propose two methods to estimate the exposure to a piece of information in an unbiased manner: a vanilla method which is based on sampling the network uniformly and a method which non-uniformly samples the network motivated by the Friendship Paradox. We provide theoretical results which characterize the conditions (in terms of properties of the network and the piece of information) under which one method outperforms the other. Further, we outline extensions of the proposed methods to dynamic information cascades (where the exposure needs to be tracked in real-time). We demonstrate the practical feasibility of the proposed methods via experiments on multiple synthetic and real-world datasets.
Human Heuristics for AI-Generated Language Are Flawed
Jun 15, 2022
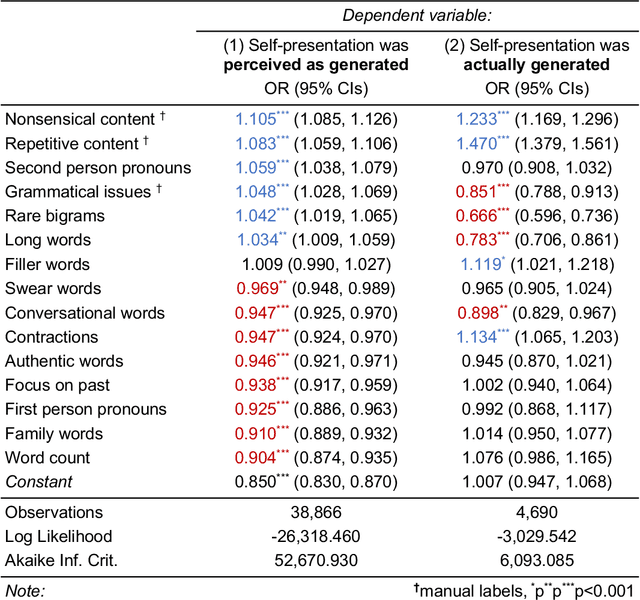
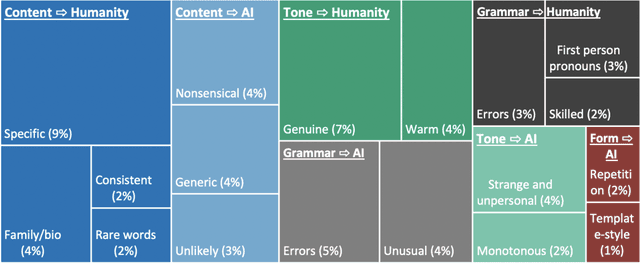

Human communication is increasingly intermixed with language generated by AI. Across chat, email, and social media, AI systems produce smart replies, autocompletes, and translations. AI-generated language is often not identified as such but poses as human language, raising concerns about novel forms of deception and manipulation. Here, we study how humans discern whether one of the most personal and consequential forms of language - a self-presentation - was generated by AI. Across six experiments, participants (N = 4,650) tried to identify self-presentations generated by state-of-the-art language models. Across professional, hospitality, and romantic settings, we find that humans are unable to identify AI-generated self-presentations. Combining qualitative analyses with language feature engineering, we find that human judgments of AI-generated language are handicapped by intuitive but flawed heuristics such as associating first-person pronouns, authentic words, or family topics with humanity. We show that these heuristics make human judgment of generated language predictable and manipulable, allowing AI systems to produce language perceived as more human than human. We conclude by discussing solutions - such as AI accents or fair use policies - to reduce the deceptive potential of generated language, limiting the subversion of human intuition.
Dataset and Case Studies for Visual Near-Duplicates Detection in the Context of Social Media
Mar 14, 2022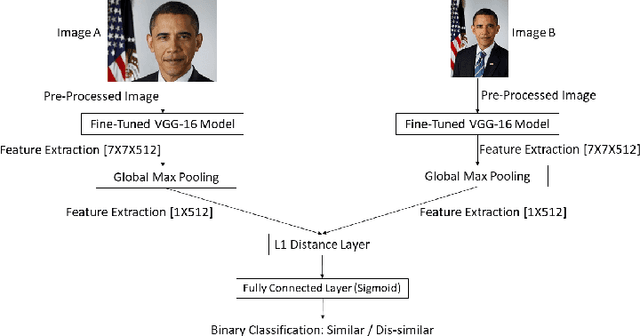
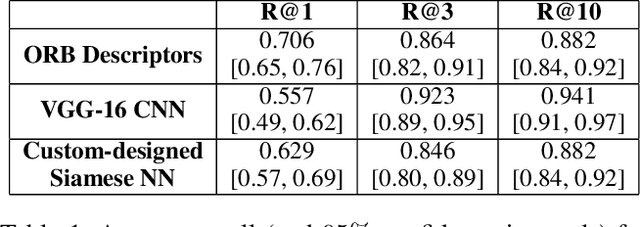

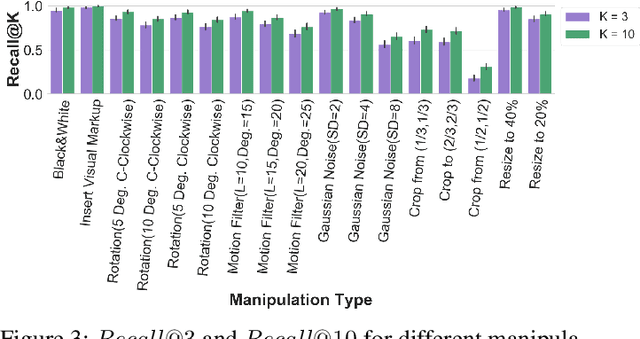
The massive spread of visual content through the web and social media poses both challenges and opportunities. Tracking visually-similar content is an important task for studying and analyzing social phenomena related to the spread of such content. In this paper, we address this need by building a dataset of social media images and evaluating visual near-duplicates retrieval methods based on image retrieval and several advanced visual feature extraction methods. We evaluate the methods using a large-scale dataset of images we crawl from social media and their manipulated versions we generated, presenting promising results in terms of recall. We demonstrate the potential of this method in two case studies: one that shows the value of creating systems supporting manual content review, and another that demonstrates the usefulness of automatic large-scale data analysis.
Artificial intelligence in communication impacts language and social relationships
Feb 10, 2021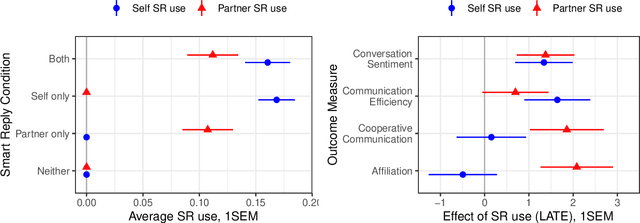
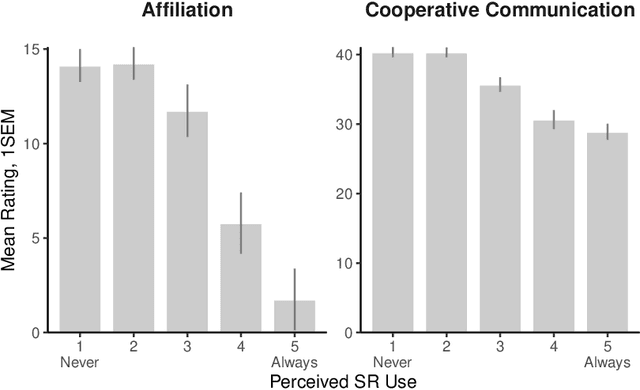
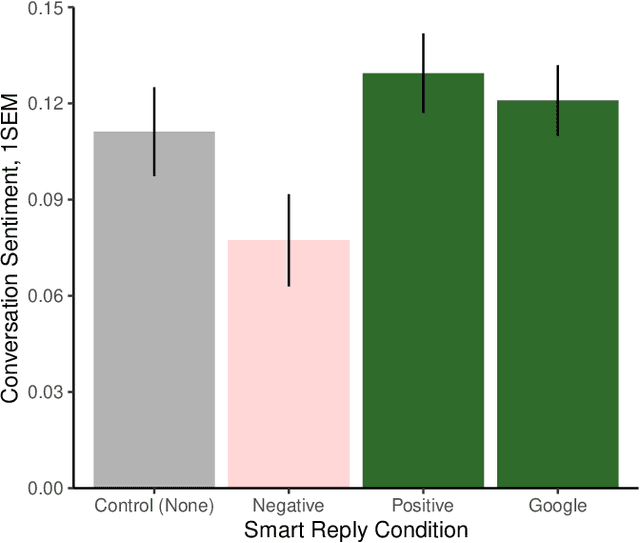
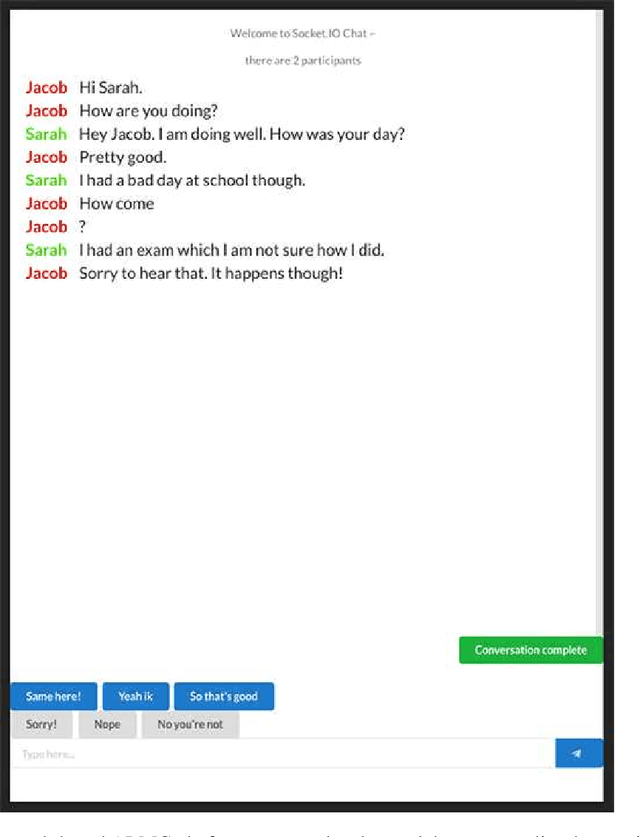
Artificial intelligence (AI) is now widely used to facilitate social interaction, but its impact on social relationships and communication is not well understood. We study the social consequences of one of the most pervasive AI applications: algorithmic response suggestions ("smart replies"). Two randomized experiments (n = 1036) provide evidence that a commercially-deployed AI changes how people interact with and perceive one another in pro-social and anti-social ways. We find that using algorithmic responses increases communication efficiency, use of positive emotional language, and positive evaluations by communication partners. However, consistent with common assumptions about the negative implications of AI, people are evaluated more negatively if they are suspected to be using algorithmic responses. Thus, even though AI can increase communication efficiency and improve interpersonal perceptions, it risks changing users' language production and continues to be viewed negatively.
Understanding Image Quality and Trust in Peer-to-Peer Marketplaces
Nov 26, 2018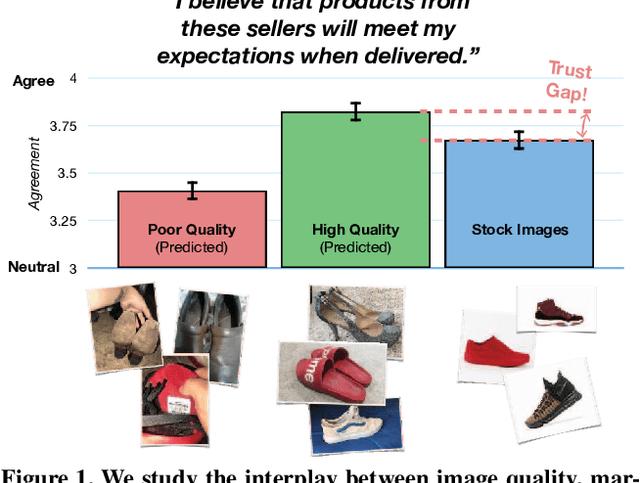

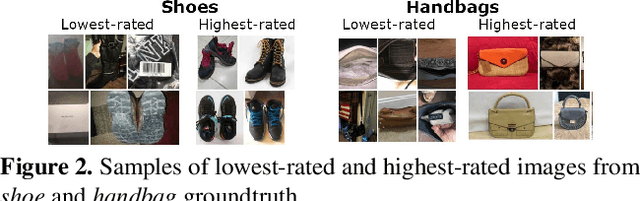
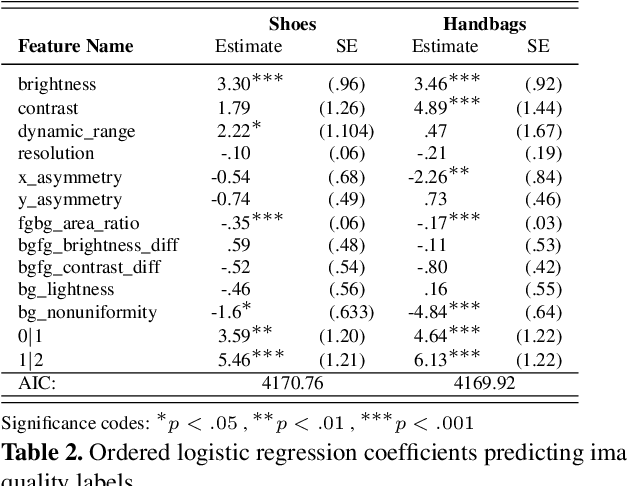
As any savvy online shopper knows, second-hand peer-to-peer marketplaces are filled with images of mixed quality. How does image quality impact marketplace outcomes, and can quality be automatically predicted? In this work, we conducted a large-scale study on the quality of user-generated images in peer-to-peer marketplaces. By gathering a dataset of common second-hand products (~75,000 images) and annotating a subset with human-labeled quality judgments, we were able to model and predict image quality with decent accuracy (~87%). We then conducted two studies focused on understanding the relationship between these image quality scores and two marketplace outcomes: sales and perceived trustworthiness. We show that image quality is associated with higher likelihood that an item will be sold, though other factors such as view count were better predictors of sales. Nonetheless, we show that high quality user-generated images selected by our models outperform stock imagery in eliciting perceptions of trust from users. Our findings can inform the design of future marketplaces and guide potential sellers to take better product images.