 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset and Case Studies for Visual Near-Duplicates Detection in the Context of Social Media
Paper and Code
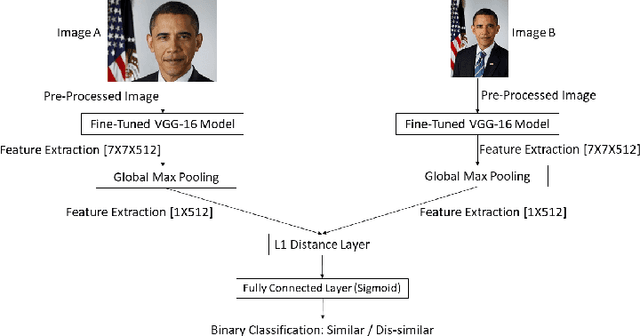
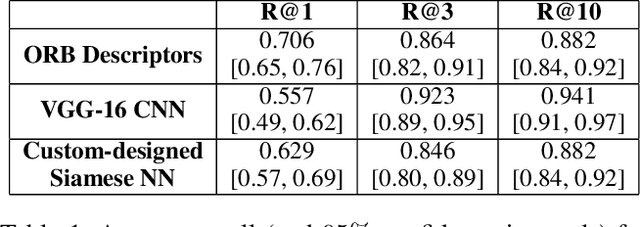

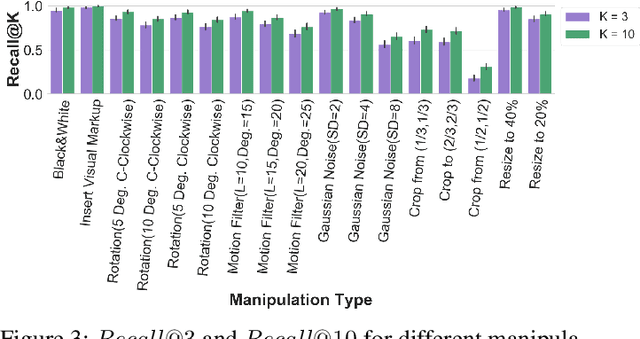
The massive spread of visual content through the web and social media poses both challenges and opportunities. Tracking visually-similar content is an important task for studying and analyzing social phenomena related to the spread of such content. In this paper, we address this need by building a dataset of social media images and evaluating visual near-duplicates retrieval methods based on image retrieval and several advanced visual feature extraction methods. We evaluate the methods using a large-scale dataset of images we crawl from social media and their manipulated versions we generated, presenting promising results in terms of recall. We demonstrate the potential of this method in two case studies: one that shows the value of creating systems supporting manual content review, and another that demonstrates the usefulness of automatic large-scale data analysis.