 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMalliavin Calculus for Counterfactual Gradient Estimation in Adaptive Inverse Reinforcement Learning
Apr 01, 2026Inverse reinforcement learning (IRL) recovers the loss function of a forward learner from its observed responses adaptive IRL aims to reconstruct the loss function of a forward learner by passively observing its gradients as it performs reinforcement learning (RL). This paper proposes a novel passive Langevin-based algorithm that achieves adaptive IRL. The key difficulty in adaptive IRL is that the required gradients in the passive algorithm are counterfactual, that is, they are conditioned on events of probability zero under the forward learner's trajectory. Therefore, naive Monte Carlo estimators are prohibitively inefficient, and kernel smoothing, though common, suffers from slow convergence. We overcome this by employing Malliavin calculus to efficiently estimate the required counterfactual gradients. We reformulate the counterfactual conditioning as a ratio of unconditioned expectations involving Malliavin quantities, thus recovering standard estimation rates. We derive the necessary Malliavin derivatives and their adjoint Skorohod integral formulations for a general Langevin structure, and provide a concrete algorithmic approach which exploits these for counterfactual gradient estimation.
LLMs as High-Dimensional Nonlinear Autoregressive Models with Attention: Training, Alignment and Inference
Jan 31, 2026Large language models (LLMs) based on transformer architectures are typically described through collections of architectural components and training procedures, obscuring their underlying computational structure. This review article provides a concise mathematical reference for researchers seeking an explicit, equation-level description of LLM training, alignment, and generation. We formulate LLMs as high-dimensional nonlinear autoregressive models with attention-based dependencies. The framework encompasses pretraining via next-token prediction, alignment methods such as reinforcement learning from human feedback (RLHF), direct preference optimization (DPO), rejection sampling fine-tuning (RSFT), and reinforcement learning from verifiable rewards (RLVR), as well as autoregressive generation during inference. Self-attention emerges naturally as a repeated bilinear--softmax--linear composition, yielding highly expressive sequence models. This formulation enables principled analysis of alignment-induced behaviors (including sycophancy), inference-time phenomena (such as hallucination, in-context learning, chain-of-thought prompting, and retrieval-augmented generation), and extensions like continual learning, while serving as a concise reference for interpretation and further theoretical development.
Why Most Optimism Bandit Algorithms Have the Same Regret Analysis: A Simple Unifying Theorem
Dec 20, 2025Several optimism-based stochastic bandit algorithms -- including UCB, UCB-V, linear UCB, and finite-arm GP-UCB -- achieve logarithmic regret using proofs that, despite superficial differences, follow essentially the same structure. This note isolates the minimal ingredients behind these analyses: a single high-probability concentration condition on the estimators, after which logarithmic regret follows from two short deterministic lemmas describing radius collapse and optimism-forced deviations. The framework yields unified, near-minimal proofs for these classical algorithms and extends naturally to many contemporary bandit variants.
Collaborative QA using Interacting LLMs. Impact of Network Structure, Node Capability and Distributed Data
Nov 18, 2025In this paper, we model and analyze how a network of interacting LLMs performs collaborative question-answering (CQA) in order to estimate a ground truth given a distributed set of documents. This problem is interesting because LLMs often hallucinate when direct evidence to answer a question is lacking, and these effects become more pronounced in a network of interacting LLMs. The hallucination spreads, causing previously accurate LLMs to hallucinate. We study interacting LLMs and their hallucination by combining novel ideas of mean-field dynamics (MFD) from network science and the randomized utility model from economics to construct a useful generative model. We model the LLM with a latent state that indicates if it is truthful or not with respect to the ground truth, and extend a tractable analytical model considering an MFD to model the diffusion of information in a directed network of LLMs. To specify the probabilities that govern the dynamics of the MFD, we propose a randomized utility model. For a network of LLMs, where each LLM has two possible latent states, we posit sufficient conditions for the existence and uniqueness of a fixed point and analyze the behavior of the fixed point in terms of the incentive (e.g., test-time compute) given to individual LLMs. We experimentally study and analyze the behavior of a network of $100$ open-source LLMs with respect to data heterogeneity, node capability, network structure, and sensitivity to framing on multiple semi-synthetic datasets.
Approximate MLE of High-Dimensional STAP Covariance Matrices with Banded & Spiked Structure -- A Convex Relaxation Approach
May 12, 2025Estimating the clutter-plus-noise covariance matrix in high-dimensional STAP is challenging in the presence of Internal Clutter Motion (ICM) and a high noise floor. The problem becomes more difficult in low-sample regimes, where the Sample Covariance Matrix (SCM) becomes ill-conditioned. To capture the ICM and high noise floor, we model the covariance matrix using a ``Banded+Spiked'' structure. Since the Maximum Likelihood Estimation (MLE) for this model is non-convex, we propose a convex relaxation which is formulated as a Frobenius norm minimization with non-smooth convex constraints enforcing banded sparsity. This relaxation serves as a provable upper bound for the non-convex likelihood maximization and extends to cases where the covariance matrix dimension exceeds the number of samples. We derive a variational inequality-based bound to assess its quality. We introduce a novel algorithm to jointly estimate the banded clutter covariance and noise power. Additionally, we establish conditions ensuring the estimated covariance matrix remains positive definite and the bandsize is accurately recovered. Numerical results using the high-fidelity RFView radar simulation environment demonstrate that our algorithm achieves a higher Signal-to-Clutter-plus-Noise Ratio (SCNR) than state-of-the-art methods, including TABASCO, Spiked Covariance Stein Shrinkage, and Diagonal Loading, particularly when the covariance matrix dimension exceeds the number of samples.
Efficient Neural SDE Training using Wiener-Space Cubature
Feb 18, 2025A neural stochastic differential equation (SDE) is an SDE with drift and diffusion terms parametrized by neural networks. The training procedure for neural SDEs consists of optimizing the SDE vector field (neural network) parameters to minimize the expected value of an objective functional on infinite-dimensional path-space. Existing training techniques focus on methods to efficiently compute path-wise gradients of the objective functional with respect to these parameters, then pair this with Monte-Carlo simulation to estimate the expectation, and stochastic gradient descent to optimize. In this work we introduce a novel training technique which bypasses and improves upon Monte-Carlo simulation; we extend results in the theory of Wiener-space cubature to approximate the expected objective functional by a weighted sum of deterministic ODE solutions. This allows us to compute gradients by efficient ODE adjoint methods. Furthermore, we exploit a high-order recombination scheme to drastically reduce the number of ODE solutions necessary to achieve a reasonable approximation. We show that this Wiener-space cubature approach can surpass the O(1/sqrt(n)) rate of Monte-Carlo simulation, or the O(log(n)/n) rate of quasi-Monte-Carlo, to achieve a O(1/n) rate under reasonable assumptions.
Interacting Large Language Model Agents. Interpretable Models and Social Learning
Nov 02, 2024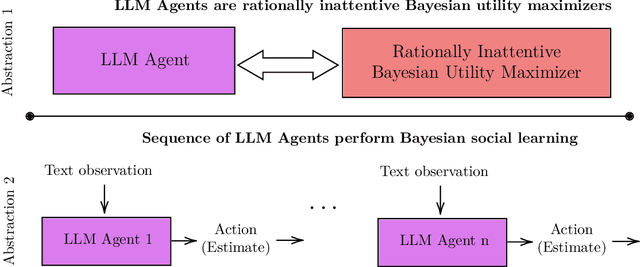
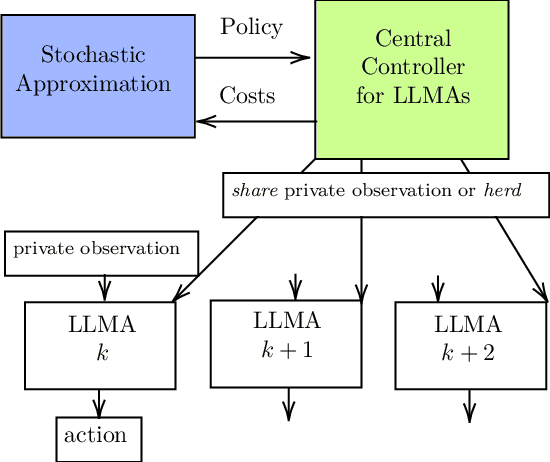
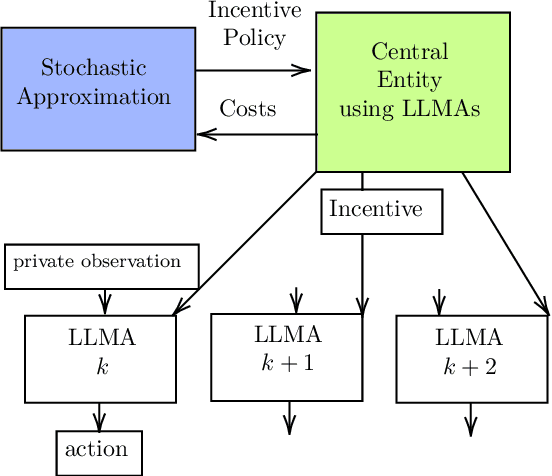
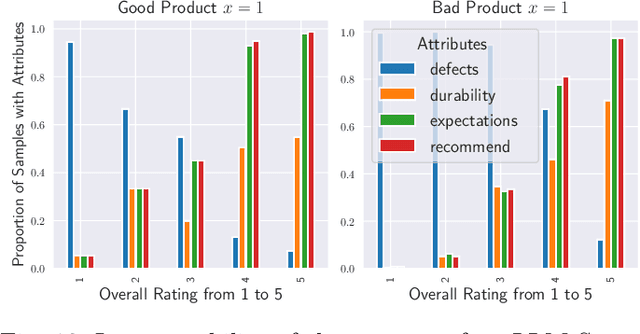
This paper develops theory and algorithms for interacting large language model agents (LLMAs) using methods from statistical signal processing and microeconomics. While both fields are mature, their application to decision-making by interacting LLMAs remains unexplored. Motivated by Bayesian sentiment analysis on online platforms, we construct interpretable models and stochastic control algorithms that enable LLMAs to interact and perform Bayesian inference. Because interacting LLMAs learn from prior decisions and external inputs, they exhibit bias and herding behavior. Thus, developing interpretable models and stochastic control algorithms is essential to understand and mitigate these behaviors. This paper has three main results. First, we show using Bayesian revealed preferences from microeconomics that an individual LLMA satisfies the sufficient conditions for rationally inattentive (bounded rationality) utility maximization and, given an observation, the LLMA chooses an action that maximizes a regularized utility. Second, we utilize Bayesian social learning to construct interpretable models for LLMAs that interact sequentially with each other and the environment while performing Bayesian inference. Our models capture the herding behavior exhibited by interacting LLMAs. Third, we propose a stochastic control framework to delay herding and improve state estimation accuracy under two settings: (a) centrally controlled LLMAs and (b) autonomous LLMAs with incentives. Throughout the paper, we demonstrate the efficacy of our methods on real datasets for hate speech classification and product quality assessment, using open-source models like Mistral and closed-source models like ChatGPT. The main takeaway of this paper, based on substantial empirical analysis and mathematical formalism, is that LLMAs act as rationally bounded Bayesian agents that exhibit social learning when interacting.
Annotation Efficiency: Identifying Hard Samples via Blocked Sparse Linear Bandits
Oct 26, 2024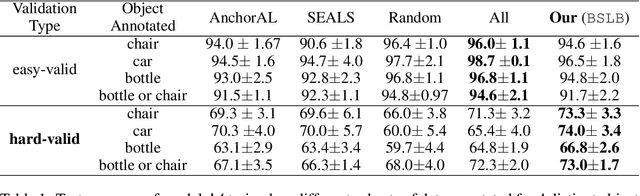
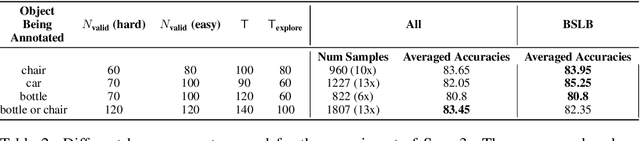
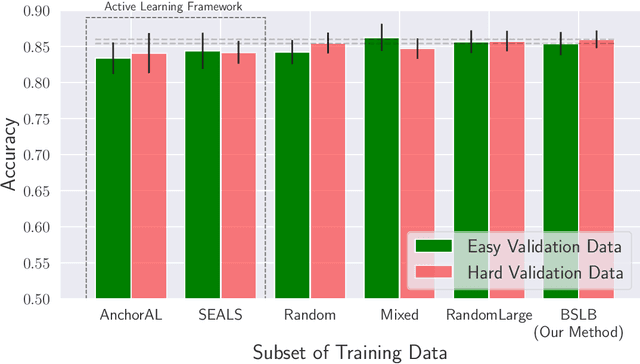
This paper considers the problem of annotating datapoints using an expert with only a few annotation rounds in a label-scarce setting. We propose soliciting reliable feedback on difficulty in annotating a datapoint from the expert in addition to ground truth label. Existing literature in active learning or coreset selection turns out to be less relevant to our setting since they presume the existence of a reliable trained model, which is absent in the label-scarce regime. However, the literature on coreset selection emphasizes the presence of difficult data points in the training set to perform supervised learning in downstream tasks (Mindermann et al., 2022). Therefore, for a given fixed annotation budget of $\mathsf{T}$ rounds, we model the sequential decision-making problem of which (difficult) datapoints to choose for annotation in a sparse linear bandits framework with the constraint that no arm can be pulled more than once (blocking constraint). With mild assumptions on the datapoints, our (computationally efficient) Explore-Then-Commit algorithm BSLB achieves a regret guarantee of $\widetilde{\mathsf{O}}(k^{\frac{1}{3}} \mathsf{T}^{\frac{2}{3}} +k^{-\frac{1}{2}} \beta_k + k^{-\frac{1}{12}} \beta_k^{\frac{1}{2}}\mathsf{T}^{\frac{5}{6}})$ where the unknown parameter vector has tail magnitude $\beta_k$ at sparsity level $k$. To this end, we show offline statistical guarantees of Lasso estimator with mild Restricted Eigenvalue (RE) condition that is also robust to sparsity. Finally, we propose a meta-algorithm C-BSLB that does not need knowledge of the optimal sparsity parameters at a no-regret cost. We demonstrate the efficacy of our BSLB algorithm for annotation in the label-scarce setting for an image classification task on the PASCAL-VOC dataset, where we use real-world annotation difficulty scores.
Slow Convergence of Interacting Kalman Filters in Word-of-Mouth Social Learning
Oct 11, 2024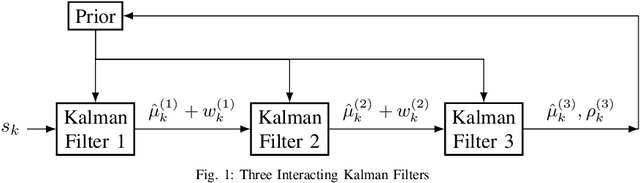
We consider word-of-mouth social learning involving $m$ Kalman filter agents that operate sequentially. The first Kalman filter receives the raw observations, while each subsequent Kalman filter receives a noisy measurement of the conditional mean of the previous Kalman filter. The prior is updated by the $m$-th Kalman filter. When $m=2$, and the observations are noisy measurements of a Gaussian random variable, the covariance goes to zero as $k^{-1/3}$ for $k$ observations, instead of $O(k^{-1})$ in the standard Kalman filter. In this paper we prove that for $m$ agents, the covariance decreases to zero as $k^{-(2^m-1)}$, i.e, the learning slows down exponentially with the number of agents. We also show that by artificially weighing the prior at each time, the learning rate can be made optimal as $k^{-1}$. The implication is that in word-of-mouth social learning, artificially re-weighing the prior can yield the optimal learning rate.
Finite Sample and Large Deviations Analysis of Stochastic Gradient Algorithm with Correlated Noise
Oct 11, 2024We analyze the finite sample regret of a decreasing step size stochastic gradient algorithm. We assume correlated noise and use a perturbed Lyapunov function as a systematic approach for the analysis. Finally we analyze the escape time of the iterates using large deviations theory.