 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolyMaX: General Dense Prediction with Mask Transformer
Nov 09, 2023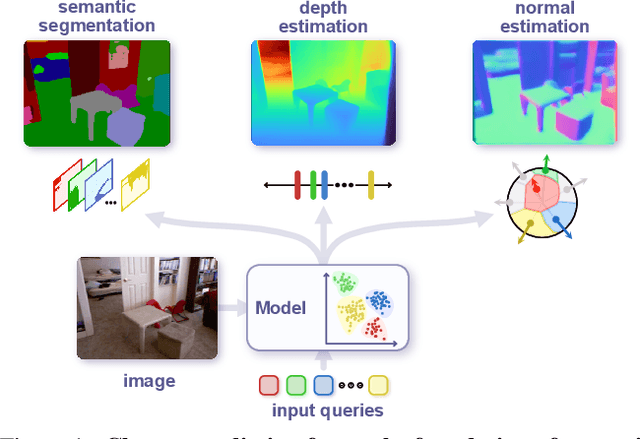
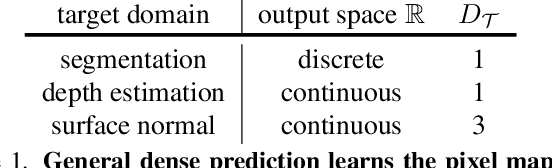
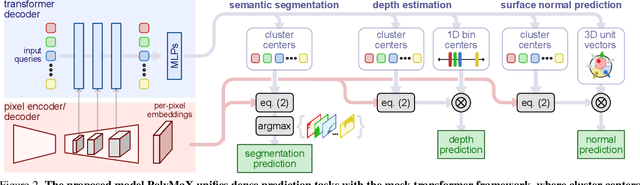
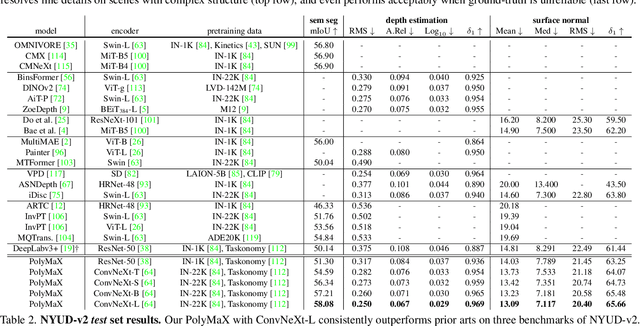
Dense prediction tasks, such as semantic segmentation, depth estimation, and surface normal prediction, can be easily formulated as per-pixel classification (discrete outputs) or regression (continuous outputs). This per-pixel prediction paradigm has remained popular due to the prevalence of fully convolutional networks. However, on the recent frontier of segmentation task, the community has been witnessing a shift of paradigm from per-pixel prediction to cluster-prediction with the emergence of transformer architectures, particularly the mask transformers, which directly predicts a label for a mask instead of a pixel. Despite this shift, methods based on the per-pixel prediction paradigm still dominate the benchmarks on the other dense prediction tasks that require continuous outputs, such as depth estimation and surface normal prediction. Motivated by the success of DORN and AdaBins in depth estimation, achieved by discretizing the continuous output space, we propose to generalize the cluster-prediction based method to general dense prediction tasks. This allows us to unify dense prediction tasks with the mask transformer framework. Remarkably, the resulting model PolyMaX demonstrates state-of-the-art performance on three benchmarks of NYUD-v2 dataset. We hope our simple yet effective design can inspire more research on exploiting mask transformers for more dense prediction tasks. Code and model will be made available.
SANPO: A Scene Understanding, Accessibility, Navigation, Pathfinding, Obstacle Avoidance Dataset
Sep 21, 2023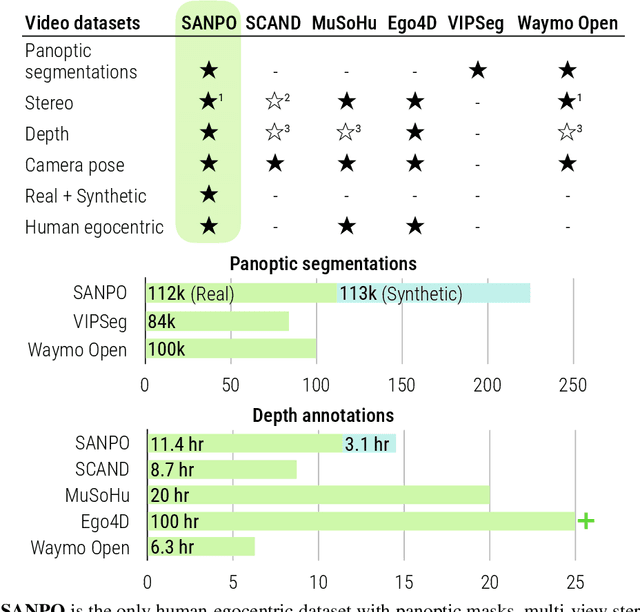
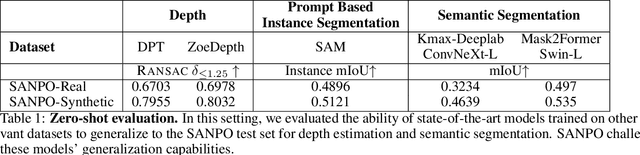
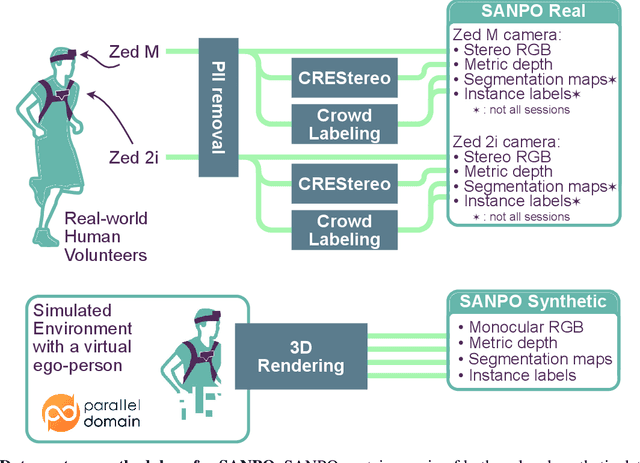
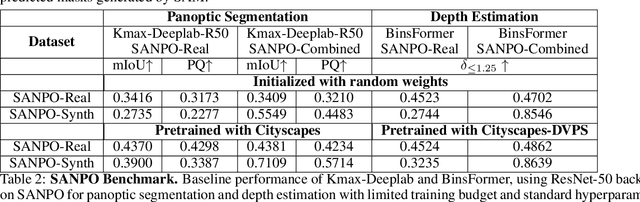
We introduce SANPO, a large-scale egocentric video dataset focused on dense prediction in outdoor environments. It contains stereo video sessions collected across diverse outdoor environments, as well as rendered synthetic video sessions. (Synthetic data was provided by Parallel Domain.) All sessions have (dense) depth and odometry labels. All synthetic sessions and a subset of real sessions have temporally consistent dense panoptic segmentation labels. To our knowledge, this is the first human egocentric video dataset with both large scale dense panoptic segmentation and depth annotations. In addition to the dataset we also provide zero-shot baselines and SANPO benchmarks for future research. We hope that the challenging nature of SANPO will help advance the state-of-the-art in video segmentation, depth estimation, multi-task visual modeling, and synthetic-to-real domain adaptation, while enabling human navigation systems. SANPO is available here: https://google-research-datasets.github.io/sanpo_dataset/
Exploring Fine-Grained Audiovisual Categorization with the SSW60 Dataset
Jul 21, 2022
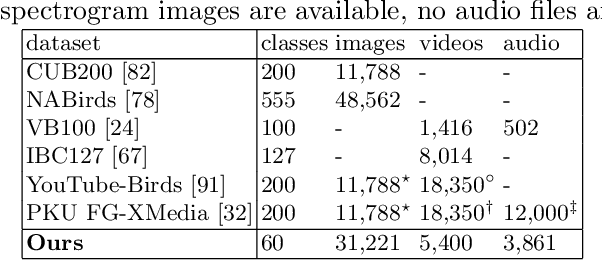
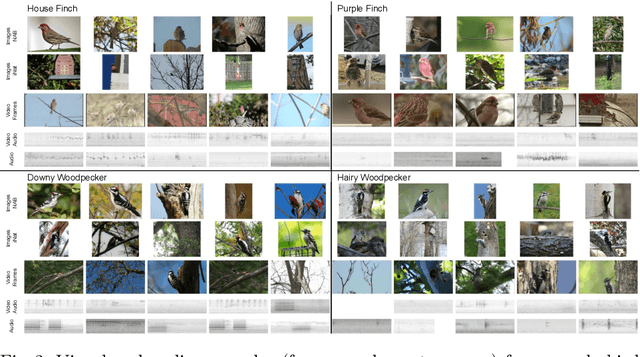
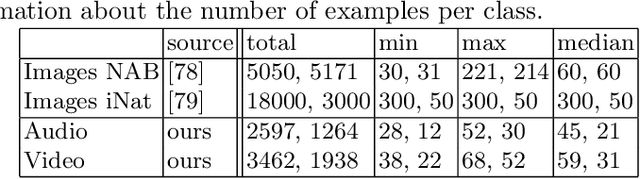
We present a new benchmark dataset, Sapsucker Woods 60 (SSW60), for advancing research on audiovisual fine-grained categorization. While our community has made great strides in fine-grained visual categorization on images, the counterparts in audio and video fine-grained categorization are relatively unexplored. To encourage advancements in this space, we have carefully constructed the SSW60 dataset to enable researchers to experiment with classifying the same set of categories in three different modalities: images, audio, and video. The dataset covers 60 species of birds and is comprised of images from existing datasets, and brand new, expert-curated audio and video datasets. We thoroughly benchmark audiovisual classification performance and modality fusion experiments through the use of state-of-the-art transformer methods. Our findings show that performance of audiovisual fusion methods is better than using exclusively image or audio based methods for the task of video classification. We also present interesting modality transfer experiments, enabled by the unique construction of SSW60 to encompass three different modalities. We hope the SSW60 dataset and accompanying baselines spur research in this fascinating area.
On Label Granularity and Object Localization
Jul 20, 2022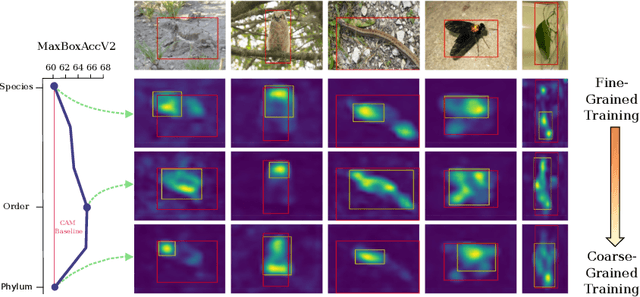

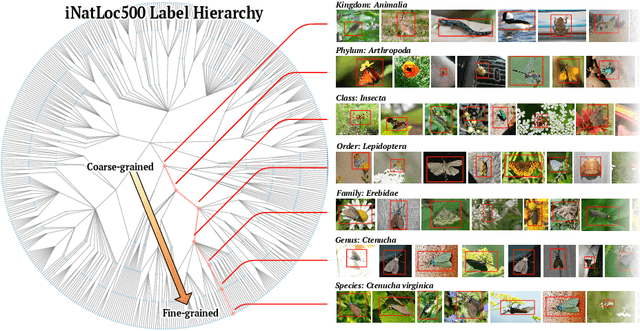
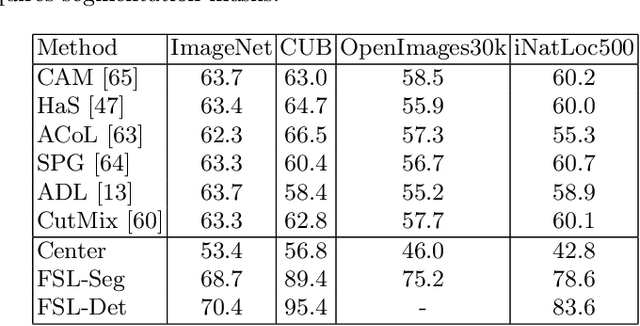
Weakly supervised object localization (WSOL) aims to learn representations that encode object location using only image-level category labels. However, many objects can be labeled at different levels of granularity. Is it an animal, a bird, or a great horned owl? Which image-level labels should we use? In this paper we study the role of label granularity in WSOL. To facilitate this investigation we introduce iNatLoc500, a new large-scale fine-grained benchmark dataset for WSOL. Surprisingly, we find that choosing the right training label granularity provides a much larger performance boost than choosing the best WSOL algorithm. We also show that changing the label granularity can significantly improve data efficiency.
Bridging the Gap Between Object Detection and User Intent via Query-Modulation
Jun 18, 2021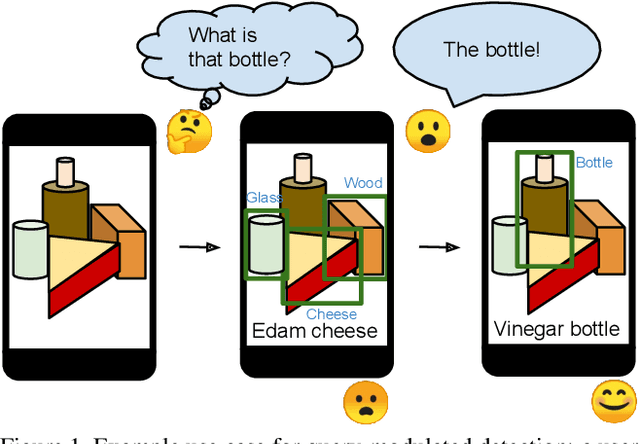

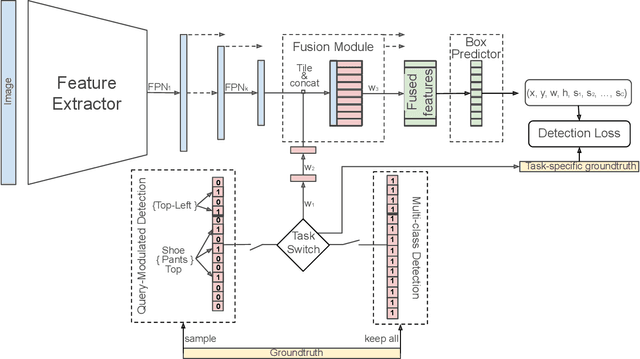
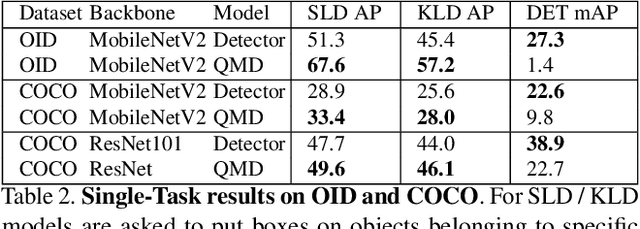
When interacting with objects through cameras, or pictures, users often have a specific intent. For example, they may want to perform a visual search. However, most object detection models ignore the user intent, relying on image pixels as their only input. This often leads to incorrect results, such as lack of a high-confidence detection on the object of interest, or detection with a wrong class label. In this paper we investigate techniques to modulate standard object detectors to explicitly account for the user intent, expressed as an embedding of a simple query. Compared to standard object detectors, query-modulated detectors show superior performance at detecting objects for a given label of interest. Thanks to large-scale training data synthesized from standard object detection annotations, query-modulated detectors can also outperform specialized referring expression recognition systems. Furthermore, they can be simultaneously trained to solve for both query-modulated detection and standard object detection.
When Does Contrastive Visual Representation Learning Work?
May 12, 2021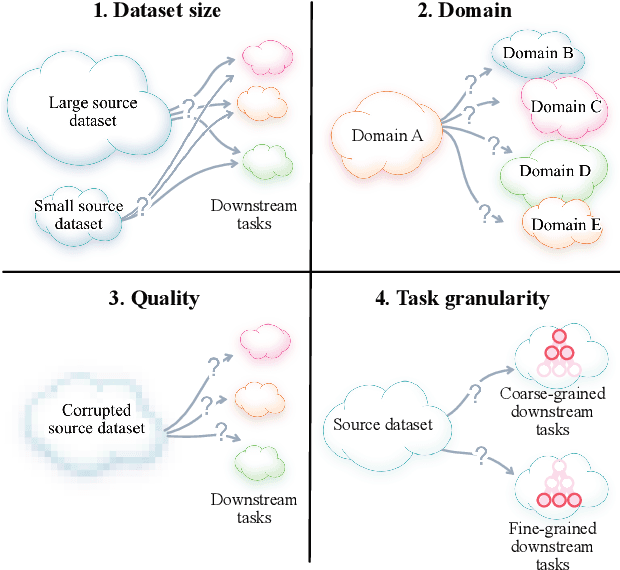
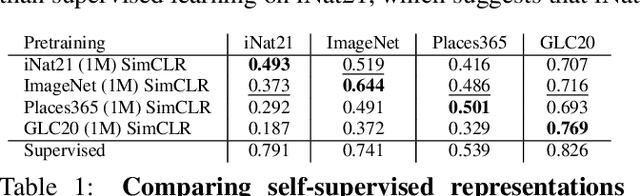
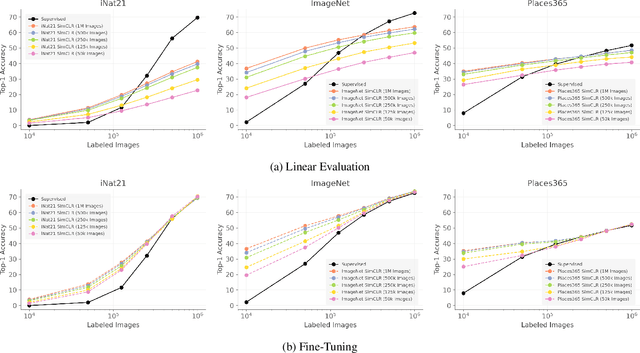
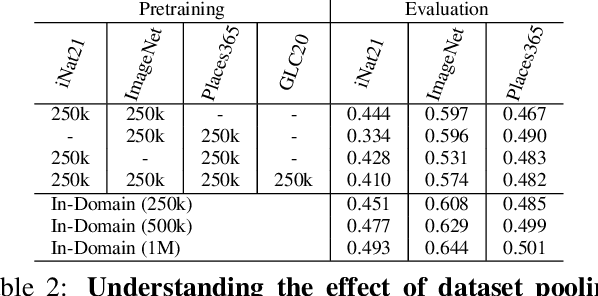
Recent self-supervised representation learning techniques have largely closed the gap between supervised and unsupervised learning on ImageNet classification. While the particulars of pretraining on ImageNet are now relatively well understood, the field still lacks widely accepted best practices for replicating this success on other datasets. As a first step in this direction, we study contrastive self-supervised learning on four diverse large-scale datasets. By looking through the lenses of data quantity, data domain, data quality, and task granularity, we provide new insights into the necessary conditions for successful self-supervised learning. Our key findings include observations such as: (i) the benefit of additional pretraining data beyond 500k images is modest, (ii) adding pretraining images from another domain does not lead to more general representations, (iii) corrupted pretraining images have a disparate impact on supervised and self-supervised pretraining, and (iv) contrastive learning lags far behind supervised learning on fine-grained visual classification tasks.
Benchmarking Representation Learning for Natural World Image Collections
Mar 30, 2021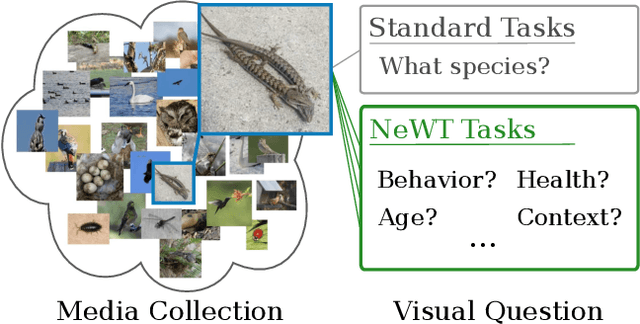

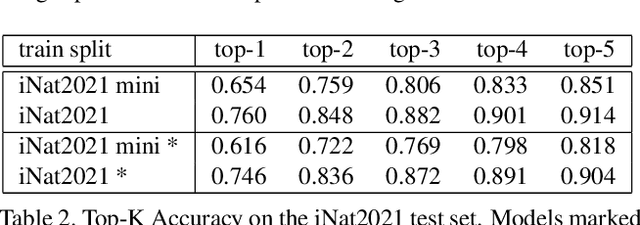

Recent progress in self-supervised learning has resulted in models that are capable of extracting rich representations from image collections without requiring any explicit label supervision. However, to date the vast majority of these approaches have restricted themselves to training on standard benchmark datasets such as ImageNet. We argue that fine-grained visual categorization problems, such as plant and animal species classification, provide an informative testbed for self-supervised learning. In order to facilitate progress in this area we present two new natural world visual classification datasets, iNat2021 and NeWT. The former consists of 2.7M images from 10k different species uploaded by users of the citizen science application iNaturalist. We designed the latter, NeWT, in collaboration with domain experts with the aim of benchmarking the performance of representation learning algorithms on a suite of challenging natural world binary classification tasks that go beyond standard species classification. These two new datasets allow us to explore questions related to large-scale representation and transfer learning in the context of fine-grained categories. We provide a comprehensive analysis of feature extractors trained with and without supervision on ImageNet and iNat2021, shedding light on the strengths and weaknesses of different learned features across a diverse set of tasks. We find that features produced by standard supervised methods still outperform those produced by self-supervised approaches such as SimCLR. However, improved self-supervised learning methods are constantly being released and the iNat2021 and NeWT datasets are a valuable resource for tracking their progress.
On the Reproducibility of Neural Network Predictions
Feb 05, 2021

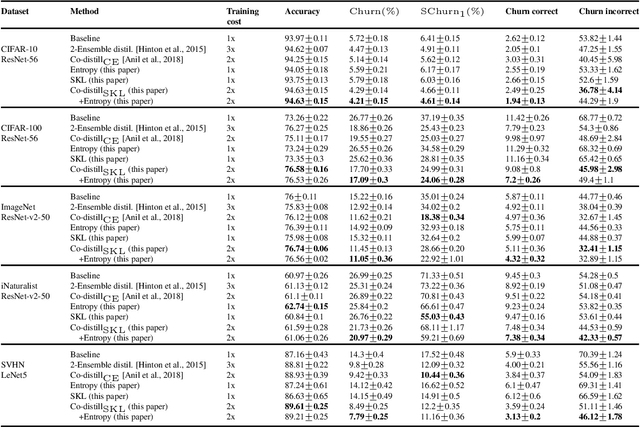
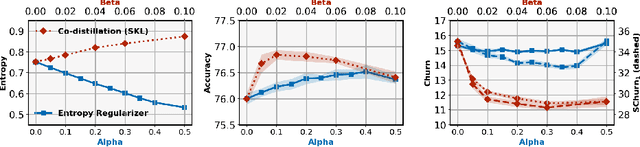
Standard training techniques for neural networks involve multiple sources of randomness, e.g., initialization, mini-batch ordering and in some cases data augmentation. Given that neural networks are heavily over-parameterized in practice, such randomness can cause {\em churn} -- for the same input, disagreements between predictions of the two models independently trained by the same algorithm, contributing to the `reproducibility challenges' in modern machine learning. In this paper, we study this problem of churn, identify factors that cause it, and propose two simple means of mitigating it. We first demonstrate that churn is indeed an issue, even for standard image classification tasks (CIFAR and ImageNet), and study the role of the different sources of training randomness that cause churn. By analyzing the relationship between churn and prediction confidences, we pursue an approach with two components for churn reduction. First, we propose using \emph{minimum entropy regularizers} to increase prediction confidences. Second, \changes{we present a novel variant of co-distillation approach~\citep{anil2018large} to increase model agreement and reduce churn}. We present empirical results showing the effectiveness of both techniques in reducing churn while improving the accuracy of the underlying model.
Improving Calibration in Deep Metric Learning With Cross-Example Softmax
Nov 17, 2020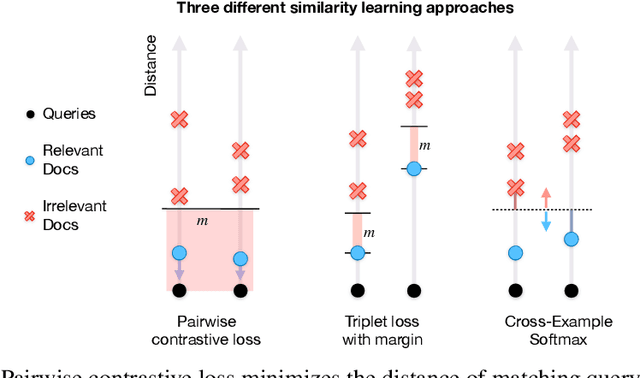
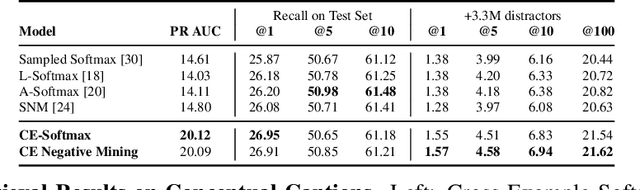
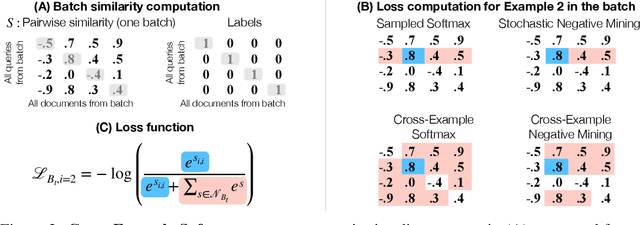
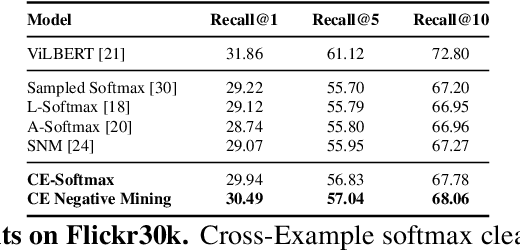
Modern image retrieval systems increasingly rely on the use of deep neural networks to learn embedding spaces in which distance encodes the relevance between a given query and image. In this setting, existing approaches tend to emphasize one of two properties. Triplet-based methods capture top-$k$ relevancy, where all top-$k$ scoring documents are assumed to be relevant to a given query Pairwise contrastive models capture threshold relevancy, where all documents scoring higher than some threshold are assumed to be relevant. In this paper, we propose Cross-Example Softmax which combines the properties of top-$k$ and threshold relevancy. In each iteration, the proposed loss encourages all queries to be closer to their matching images than all queries are to all non-matching images. This leads to a globally more calibrated similarity metric and makes distance more interpretable as an absolute measure of relevance. We further introduce Cross-Example Negative Mining, in which each pair is compared to the hardest negative comparisons across the entire batch. Empirically, we show in a series of experiments on Conceptual Captions and Flickr30k, that the proposed method effectively improves global calibration and also retrieval performance.
Understanding Image Quality and Trust in Peer-to-Peer Marketplaces
Nov 26, 2018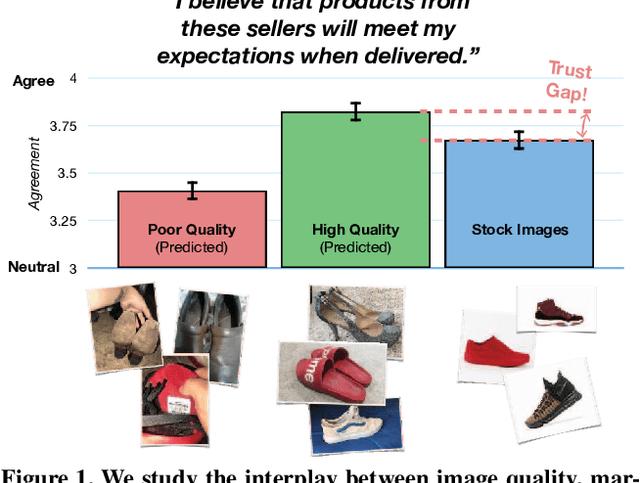

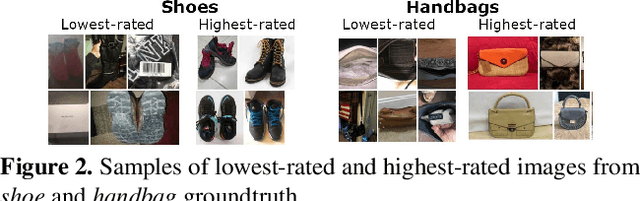
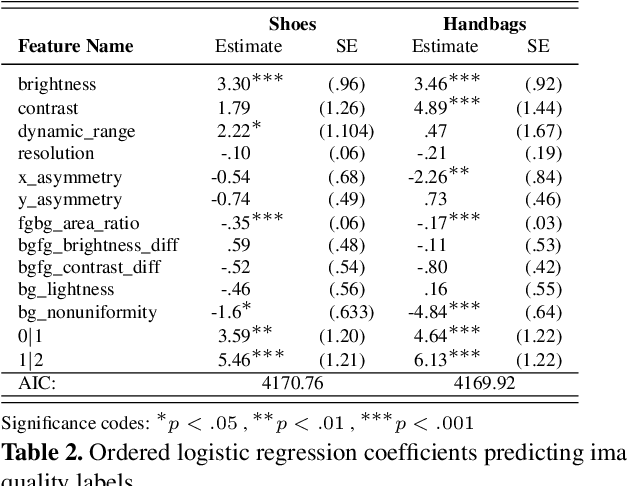
As any savvy online shopper knows, second-hand peer-to-peer marketplaces are filled with images of mixed quality. How does image quality impact marketplace outcomes, and can quality be automatically predicted? In this work, we conducted a large-scale study on the quality of user-generated images in peer-to-peer marketplaces. By gathering a dataset of common second-hand products (~75,000 images) and annotating a subset with human-labeled quality judgments, we were able to model and predict image quality with decent accuracy (~87%). We then conducted two studies focused on understanding the relationship between these image quality scores and two marketplace outcomes: sales and perceived trustworthiness. We show that image quality is associated with higher likelihood that an item will be sold, though other factors such as view count were better predictors of sales. Nonetheless, we show that high quality user-generated images selected by our models outperform stock imagery in eliciting perceptions of trust from users. Our findings can inform the design of future marketplaces and guide potential sellers to take better product images.