 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Reproducibility of Neural Network Predictions
Feb 05, 2021

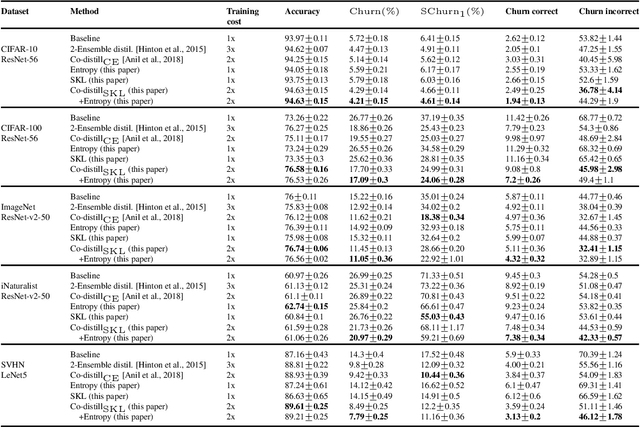
Standard training techniques for neural networks involve multiple sources of randomness, e.g., initialization, mini-batch ordering and in some cases data augmentation. Given that neural networks are heavily over-parameterized in practice, such randomness can cause {\em churn} -- for the same input, disagreements between predictions of the two models independently trained by the same algorithm, contributing to the `reproducibility challenges' in modern machine learning. In this paper, we study this problem of churn, identify factors that cause it, and propose two simple means of mitigating it. We first demonstrate that churn is indeed an issue, even for standard image classification tasks (CIFAR and ImageNet), and study the role of the different sources of training randomness that cause churn. By analyzing the relationship between churn and prediction confidences, we pursue an approach with two components for churn reduction. First, we propose using \emph{minimum entropy regularizers} to increase prediction confidences. Second, \changes{we present a novel variant of co-distillation approach~\citep{anil2018large} to increase model agreement and reduce churn}. We present empirical results showing the effectiveness of both techniques in reducing churn while improving the accuracy of the underlying model.
Coping with Label Shift via Distributionally Robust Optimisation
Oct 23, 2020


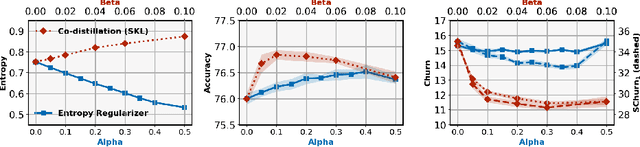
The label shift problem refers to the supervised learning setting where the train and test label distributions do not match. Existing work addressing label shift usually assumes access to an \emph{unlabelled} test sample. This sample may be used to estimate the test label distribution, and to then train a suitably re-weighted classifier. While approaches using this idea have proven effective, their scope is limited as it is not always feasible to access the target domain; further, they require repeated retraining if the model is to be deployed in \emph{multiple} test environments. Can one instead learn a \emph{single} classifier that is robust to arbitrary label shifts from a broad family? In this paper, we answer this question by proposing a model that minimises an objective based on distributionally robust optimisation (DRO). We then design and analyse a gradient descent-proximal mirror ascent algorithm tailored for large-scale problems to optimise the proposed objective. %, and establish its convergence. Finally, through experiments on CIFAR-100 and ImageNet, we show that our technique can significantly improve performance over a number of baselines in settings where label shift is present.
Self-supervised Learning for Deep Models in Recommendations
Jul 25, 2020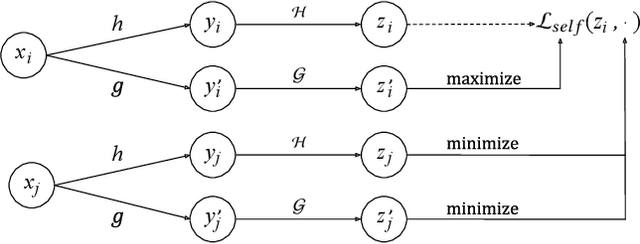
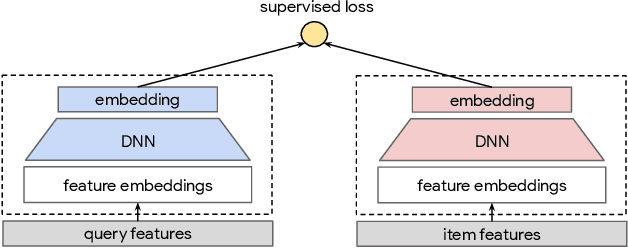
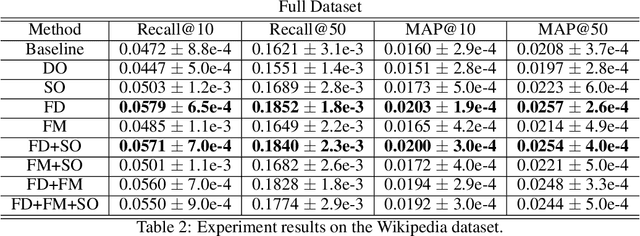
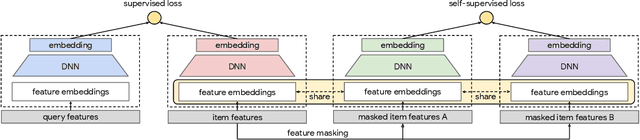
Large scale neural recommender models play a critical role in modern search and recommendation systems. To model large-vocab sparse categorical features, typical recommender models learn a joint embedding space for both queries and items. With millions to billions of items to choose from, the quality of learned embedding representations is crucial to provide high quality recommendations to users with various interests. Inspired by the recent success in self-supervised representation learning research in both computer vision and natural language understanding, we propose a multi-task self-supervised learning (SSL) framework for sparse neural models in recommendations. Furthermore, we propose two highly generalizable self-supervised learning tasks: (i) Feature Masking (FM) and (ii) Feature Dropout (FD) within the proposed SSL framework. We evaluate our framework using two large-scale datasets with ~500M and 1B training examples respectively. Our results demonstrate that the proposed framework outperforms baseline models and state-of-the-art spread-out regularization techniques in the context of retrieval. The SSL framework shows larger improvement with less supervision compared to the counterparts.
Robust Large-Margin Learning in Hyperbolic Space
Apr 11, 2020



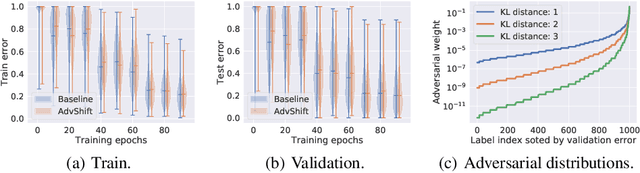
Recently, there has been a surge of interest in representation learning in hyperbolic spaces, driven by their ability to represent hierarchical data with significantly fewer dimensions than standard Euclidean spaces. However, the viability and benefits of hyperbolic spaces for downstream machine learning tasks have received less attention. In this paper, we present, to our knowledge, the first theoretical guarantees for learning a classifier in hyperbolic rather than Euclidean space. Specifically, we consider the problem of learning a large-margin classifier for data possessing a hierarchical structure. Our first contribution is a hyperbolic perceptron algorithm, which provably converges to a separating hyperplane. We then provide an algorithm to efficiently learn a large-margin hyperplane, relying on the careful injection of adversarial examples. Finally, we prove that for hierarchical data that embeds well into hyperbolic space, the low embedding dimension ensures superior guarantees when learning the classifier directly in hyperbolic space.
Making Deep Neural Networks Robust to Label Noise: a Loss Correction Approach
Mar 22, 2017
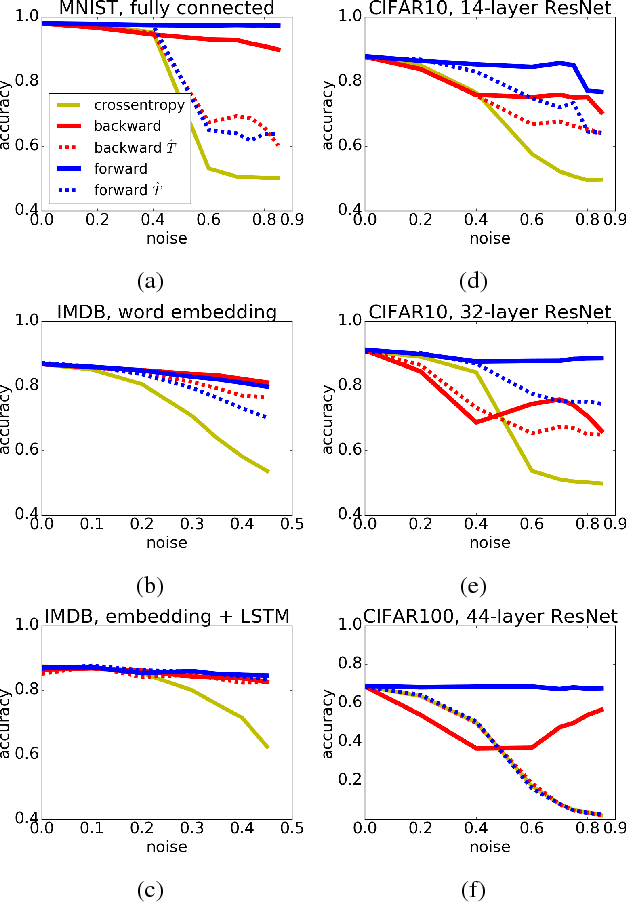

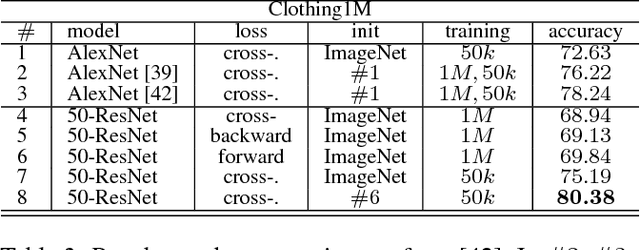
We present a theoretically grounded approach to train deep neural networks, including recurrent networks, subject to class-dependent label noise. We propose two procedures for loss correction that are agnostic to both application domain and network architecture. They simply amount to at most a matrix inversion and multiplication, provided that we know the probability of each class being corrupted into another. We further show how one can estimate these probabilities, adapting a recent technique for noise estimation to the multi-class setting, and thus providing an end-to-end framework. Extensive experiments on MNIST, IMDB, CIFAR-10, CIFAR-100 and a large scale dataset of clothing images employing a diversity of architectures --- stacking dense, convolutional, pooling, dropout, batch normalization, word embedding, LSTM and residual layers --- demonstrate the noise robustness of our proposals. Incidentally, we also prove that, when ReLU is the only non-linearity, the loss curvature is immune to class-dependent label noise.
Predicting accurate probabilities with a ranking loss
Jun 18, 2012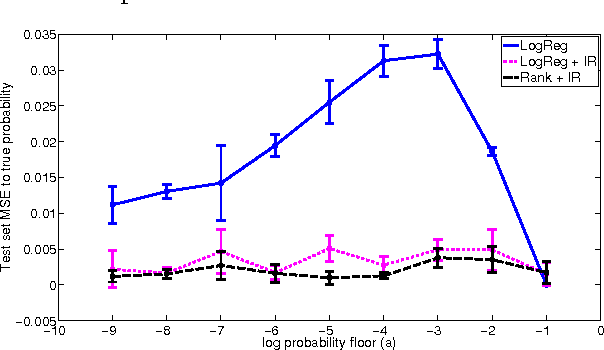
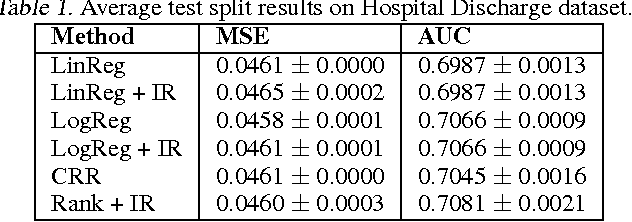
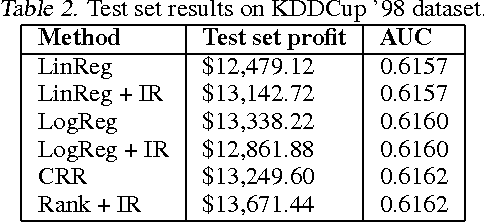
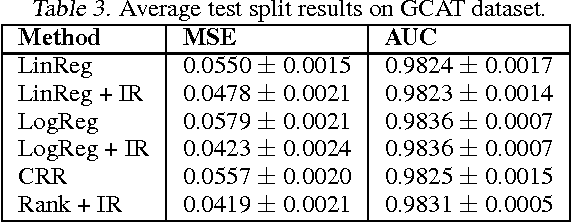
In many real-world applications of machine learning classifiers, it is essential to predict the probability of an example belonging to a particular class. This paper proposes a simple technique for predicting probabilities based on optimizing a ranking loss, followed by isotonic regression. This semi-parametric technique offers both good ranking and regression performance, and models a richer set of probability distributions than statistical workhorses such as logistic regression. We provide experimental results that show the effectiveness of this technique on real-world applications of probability prediction.