 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORBIT: Preserving Foundational Language Capabilities in GenRetrieval via Origin-Regulated Merging
May 12, 2026Despite the rapid advancements in large language model (LLM) development, fine-tuning them for specific tasks often results in the catastrophic forgetting of their general, language-based reasoning abilities. This work investigates and addresses this challenge in the context of the Generative Retrieval (GenRetrieval) task. During GenRetrieval fine-tuning, we find this forgetting occurs rapidly and correlates with the distance between the fine-tuned and original model parameters. Given these observations, we propose ORBIT, a novel approach that actively tracks the distance between fine-tuned and initial model weights, and uses a weight averaging strategy to constrain model drift during GenRetrieval fine-tuning when this inter-model distance exceeds a maximum threshold. Our results show that ORBIT retains substantial text and retrieval performance by outperforming both common continual learning baselines and related regularization methods that also employ weight averaging.
Vectorizing the Trie: Efficient Constrained Decoding for LLM-based Generative Retrieval on Accelerators
Feb 26, 2026Generative retrieval has emerged as a powerful paradigm for LLM-based recommendation. However, industrial recommender systems often benefit from restricting the output space to a constrained subset of items based on business logic (e.g. enforcing content freshness or product category), which standard autoregressive decoding cannot natively support. Moreover, existing constrained decoding methods that make use of prefix trees (Tries) incur severe latency penalties on hardware accelerators (TPUs/GPUs). In this work, we introduce STATIC (Sparse Transition Matrix-Accelerated Trie Index for Constrained Decoding), an efficient and scalable constrained decoding technique designed specifically for high-throughput LLM-based generative retrieval on TPUs/GPUs. By flattening the prefix tree into a static Compressed Sparse Row (CSR) matrix, we transform irregular tree traversals into fully vectorized sparse matrix operations, unlocking massive efficiency gains on hardware accelerators. We deploy STATIC on a large-scale industrial video recommendation platform serving billions of users. STATIC produces significant product metric impact with minimal latency overhead (0.033 ms per step and 0.25% of inference time), achieving a 948x speedup over a CPU trie implementation and a 47-1033x speedup over a hardware-accelerated binary-search baseline. Furthermore, the runtime overhead of STATIC remains extremely low across a wide range of practical configurations. To the best of our knowledge, STATIC enables the first production-scale deployment of strictly constrained generative retrieval. In addition, evaluation on academic benchmarks demonstrates that STATIC can considerably improve cold-start performance for generative retrieval. Our code is available at https://github.com/youtube/static-constraint-decoding.
PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
Oct 09, 2025Large Language Models (LLMs) pose a new paradigm of modeling and computation for information tasks. Recommendation systems are a critical application domain poised to benefit significantly from the sequence modeling capabilities and world knowledge inherent in these large models. In this paper, we introduce PLUM, a framework designed to adapt pre-trained LLMs for industry-scale recommendation tasks. PLUM consists of item tokenization using Semantic IDs, continued pre-training (CPT) on domain-specific data, and task-specific fine-tuning for recommendation objectives. For fine-tuning, we focus particularly on generative retrieval, where the model is directly trained to generate Semantic IDs of recommended items based on user context. We conduct comprehensive experiments on large-scale internal video recommendation datasets. Our results demonstrate that PLUM achieves substantial improvements for retrieval compared to a heavily-optimized production model built with large embedding tables. We also present a scaling study for the model's retrieval performance, our learnings about CPT, a few enhancements to Semantic IDs, along with an overview of the training and inference methods that enable launching this framework to billions of users in YouTube.
STAR: A Simple Training-free Approach for Recommendations using Large Language Models
Oct 21, 2024Recent progress in large language models (LLMs) offers promising new approaches for recommendation system (RecSys) tasks. While the current state-of-the-art methods rely on fine-tuning LLMs to achieve optimal results, this process is costly and introduces significant engineering complexities. Conversely, methods that bypass fine-tuning and use LLMs directly are less resource-intensive but often fail to fully capture both semantic and collaborative information, resulting in sub-optimal performance compared to their fine-tuned counterparts. In this paper, we propose a Simple Training-free Approach for Recommendation (STAR), a framework that utilizes LLMs and can be applied to various recommendation tasks without the need for fine-tuning. Our approach involves a retrieval stage that uses semantic embeddings from LLMs combined with collaborative user information to retrieve candidate items. We then apply an LLM for pairwise ranking to enhance next-item prediction. Experimental results on the Amazon Review dataset show competitive performance for next item prediction, even with our retrieval stage alone. Our full method achieves Hits@10 performance of +23.8% on Beauty, +37.5% on Toys and Games, and -1.8% on Sports and Outdoors relative to the best supervised models. This framework offers an effective alternative to traditional supervised models, highlighting the potential of LLMs in recommendation systems without extensive training or custom architectures.
Leveraging LLM Reasoning Enhances Personalized Recommender Systems
Jul 22, 2024



Recent advancements have showcased the potential of Large Language Models (LLMs) in executing reasoning tasks, particularly facilitated by Chain-of-Thought (CoT) prompting. While tasks like arithmetic reasoning involve clear, definitive answers and logical chains of thought, the application of LLM reasoning in recommendation systems (RecSys) presents a distinct challenge. RecSys tasks revolve around subjectivity and personalized preferences, an under-explored domain in utilizing LLMs' reasoning capabilities. Our study explores several aspects to better understand reasoning for RecSys and demonstrate how task quality improves by utilizing LLM reasoning in both zero-shot and finetuning settings. Additionally, we propose RecSAVER (Recommender Systems Automatic Verification and Evaluation of Reasoning) to automatically assess the quality of LLM reasoning responses without the requirement of curated gold references or human raters. We show that our framework aligns with real human judgment on the coherence and faithfulness of reasoning responses. Overall, our work shows that incorporating reasoning into RecSys can improve personalized tasks, paving the way for further advancements in recommender system methodologies.
Aligning Large Language Models with Recommendation Knowledge
Mar 30, 2024



Large language models (LLMs) have recently been used as backbones for recommender systems. However, their performance often lags behind conventional methods in standard tasks like retrieval. We attribute this to a mismatch between LLMs' knowledge and the knowledge crucial for effective recommendations. While LLMs excel at natural language reasoning, they cannot model complex user-item interactions inherent in recommendation tasks. We propose bridging the knowledge gap and equipping LLMs with recommendation-specific knowledge to address this. Operations such as Masked Item Modeling (MIM) and Bayesian Personalized Ranking (BPR) have found success in conventional recommender systems. Inspired by this, we simulate these operations through natural language to generate auxiliary-task data samples that encode item correlations and user preferences. Fine-tuning LLMs on such auxiliary-task data samples and incorporating more informative recommendation-task data samples facilitates the injection of recommendation-specific knowledge into LLMs. Extensive experiments across retrieval, ranking, and rating prediction tasks on LLMs such as FLAN-T5-Base and FLAN-T5-XL show the effectiveness of our technique in domains such as Amazon Toys & Games, Beauty, and Sports & Outdoors. Notably, our method outperforms conventional and LLM-based baselines, including the current SOTA, by significant margins in retrieval, showcasing its potential for enhancing recommendation quality.
Density Weighting for Multi-Interest Personalized Recommendation
Aug 03, 2023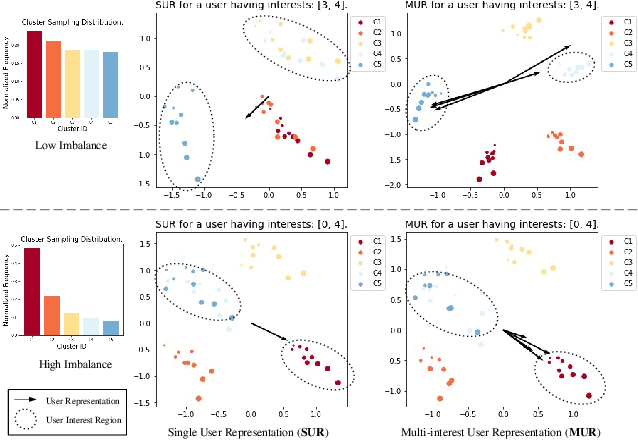


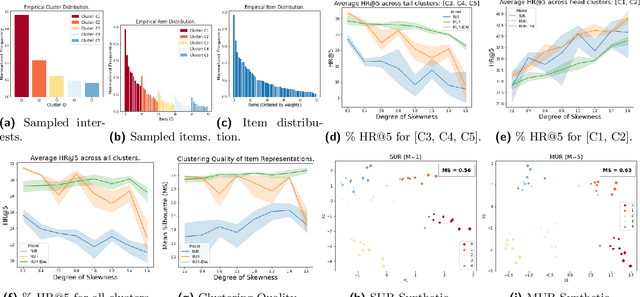
Using multiple user representations (MUR) to model user behavior instead of a single user representation (SUR) has been shown to improve personalization in recommendation systems. However, the performance gains observed with MUR can be sensitive to the skewness in the item and/or user interest distribution. When the data distribution is highly skewed, the gains observed by learning multiple representations diminish since the model dominates on head items/interests, leading to poor performance on tail items. Robustness to data sparsity is therefore essential for MUR-based approaches to achieve good performance for recommendations. Yet, research in MUR and data imbalance have largely been done independently. In this paper, we delve deeper into the shortcomings of MUR inferred from imbalanced data distributions. We make several contributions: (1) Using synthetic datasets, we demonstrate the sensitivity of MUR with respect to data imbalance, (2) To improve MUR for tail items, we propose an iterative density weighting scheme (IDW) with user tower calibration to mitigate the effect of training over long-tail distribution on personalization, and (3) Through extensive experiments on three real-world benchmarks, we demonstrate IDW outperforms other alternatives that address data imbalance.
Online Matching: A Real-time Bandit System for Large-scale Recommendations
Jul 29, 2023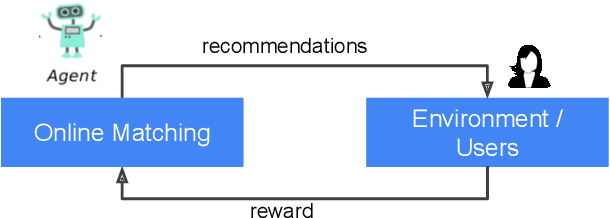

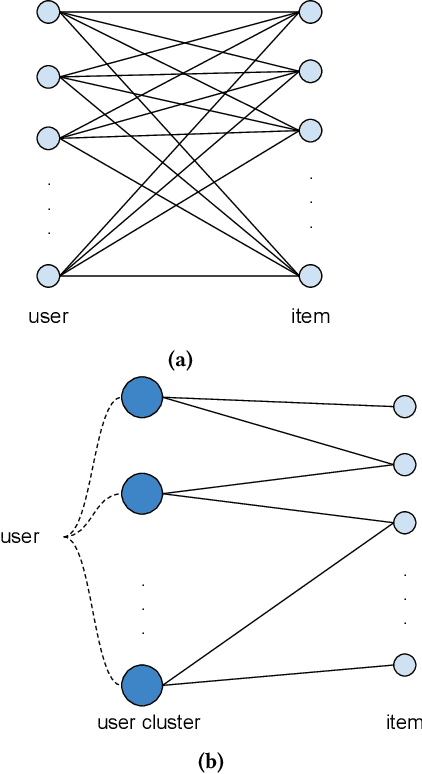

The last decade has witnessed many successes of deep learning-based models for industry-scale recommender systems. These models are typically trained offline in a batch manner. While being effective in capturing users' past interactions with recommendation platforms, batch learning suffers from long model-update latency and is vulnerable to system biases, making it hard to adapt to distribution shift and explore new items or user interests. Although online learning-based approaches (e.g., multi-armed bandits) have demonstrated promising theoretical results in tackling these challenges, their practical real-time implementation in large-scale recommender systems remains limited. First, the scalability of online approaches in servicing a massive online traffic while ensuring timely updates of bandit parameters poses a significant challenge. Additionally, exploring uncertainty in recommender systems can easily result in unfavorable user experience, highlighting the need for devising intricate strategies that effectively balance the trade-off between exploitation and exploration. In this paper, we introduce Online Matching: a scalable closed-loop bandit system learning from users' direct feedback on items in real time. We present a hybrid "offline + online" approach for constructing this system, accompanied by a comprehensive exposition of the end-to-end system architecture. We propose Diag-LinUCB -- a novel extension of the LinUCB algorithm -- to enable distributed updates of bandits parameter in a scalable and timely manner. We conduct live experiments in YouTube and show that Online Matching is able to enhance the capabilities of fresh content discovery and item exploration in the present platform.
Better Generalization with Semantic IDs: A case study in Ranking for Recommendations
Jun 13, 2023Training good representations for items is critical in recommender models. Typically, an item is assigned a unique randomly generated ID, and is commonly represented by learning an embedding corresponding to the value of the random ID. Although widely used, this approach have limitations when the number of items are large and items are power-law distributed -- typical characteristics of real-world recommendation systems. This leads to the item cold-start problem, where the model is unable to make reliable inferences for tail and previously unseen items. Removing these ID features and their learned embeddings altogether to combat cold-start issue severely degrades the recommendation quality. Content-based item embeddings are more reliable, but they are expensive to store and use, particularly for users' past item interaction sequence. In this paper, we use Semantic IDs, a compact discrete item representations learned from content embeddings using RQ-VAE that captures hierarchy of concepts in items. We showcase how we use them as a replacement of item IDs in a resource-constrained ranking model used in an industrial-scale video sharing platform. Moreover, we show how Semantic IDs improves the generalization ability of our system, without sacrificing top-level metrics.
Improving Training Stability for Multitask Ranking Models in Recommender Systems
Feb 17, 2023



Recommender systems play an important role in many content platforms. While most recommendation research is dedicated to designing better models to improve user experience, we found that research on stabilizing the training for such models is severely under-explored. As recommendation models become larger and more sophisticated, they are more susceptible to training instability issues, \emph{i.e.}, loss divergence, which can make the model unusable, waste significant resources and block model developments. In this paper, we share our findings and best practices we learned for improving the training stability of a real-world multitask ranking model for YouTube recommendations. We show some properties of the model that lead to unstable training and conjecture on the causes. Furthermore, based on our observations of training dynamics near the point of training instability, we hypothesize why existing solutions would fail, and propose a new algorithm to mitigate the limitations of existing solutions. Our experiments on YouTube production dataset show the proposed algorithm can significantly improve training stability while not compromising convergence, comparing with several commonly used baseline methods.