 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeACT: Automated Constraint Targeting for Multi-Objective Recommender Systems
Sep 03, 2025Recommender systems often must maximize a primary objective while ensuring secondary ones satisfy minimum thresholds, or "guardrails." This is critical for maintaining a consistent user experience and platform ecosystem, but enforcing these guardrails despite orthogonal system changes is challenging and often requires manual hyperparameter tuning. We introduce the Automated Constraint Targeting (ACT) framework, which automatically finds the minimal set of hyperparameter changes needed to satisfy these guardrails. ACT uses an offline pairwise evaluation on unbiased data to find solutions and continuously retrains to adapt to system and user behavior changes. We empirically demonstrate its efficacy and describe its deployment in a large-scale production environment.
Learned Ranking Function: From Short-term Behavior Predictions to Long-term User Satisfaction
Aug 12, 2024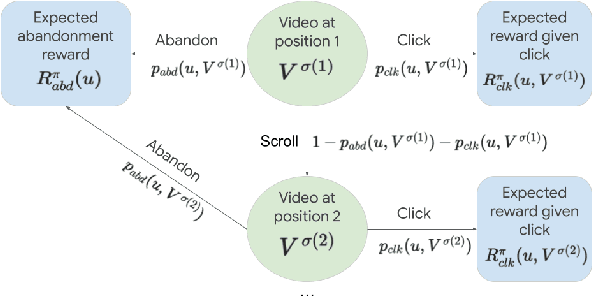
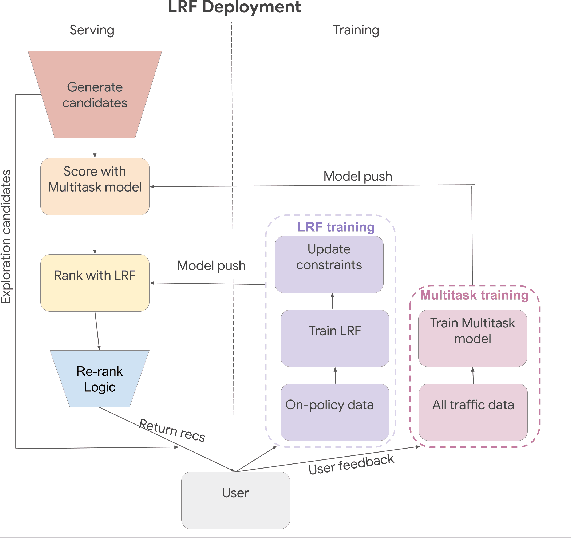
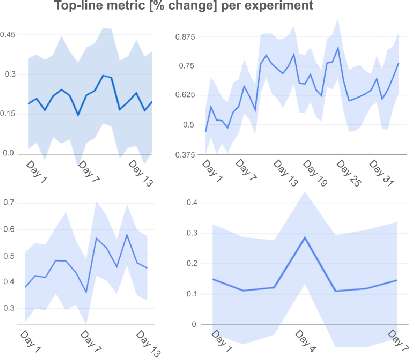
We present the Learned Ranking Function (LRF), a system that takes short-term user-item behavior predictions as input and outputs a slate of recommendations that directly optimizes for long-term user satisfaction. Most previous work is based on optimizing the hyperparameters of a heuristic function. We propose to model the problem directly as a slate optimization problem with the objective of maximizing long-term user satisfaction. We also develop a novel constraint optimization algorithm that stabilizes objective trade-offs for multi-objective optimization. We evaluate our approach with live experiments and describe its deployment on YouTube.
Improving Training Stability for Multitask Ranking Models in Recommender Systems
Feb 17, 2023



Recommender systems play an important role in many content platforms. While most recommendation research is dedicated to designing better models to improve user experience, we found that research on stabilizing the training for such models is severely under-explored. As recommendation models become larger and more sophisticated, they are more susceptible to training instability issues, \emph{i.e.}, loss divergence, which can make the model unusable, waste significant resources and block model developments. In this paper, we share our findings and best practices we learned for improving the training stability of a real-world multitask ranking model for YouTube recommendations. We show some properties of the model that lead to unstable training and conjecture on the causes. Furthermore, based on our observations of training dynamics near the point of training instability, we hypothesize why existing solutions would fail, and propose a new algorithm to mitigate the limitations of existing solutions. Our experiments on YouTube production dataset show the proposed algorithm can significantly improve training stability while not compromising convergence, comparing with several commonly used baseline methods.