 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenThoughts: Data Recipes for Reasoning Models
Jun 05, 2025Reasoning models have made rapid progress on many benchmarks involving math, code, and science. Yet, there are still many open questions about the best training recipes for reasoning since state-of-the-art models often rely on proprietary datasets with little to no public information available. To address this, the goal of the OpenThoughts project is to create open-source datasets for training reasoning models. After initial explorations, our OpenThoughts2-1M dataset led to OpenThinker2-32B, the first model trained on public reasoning data to match DeepSeek-R1-Distill-32B on standard reasoning benchmarks such as AIME and LiveCodeBench. We then improve our dataset further by systematically investigating each step of our data generation pipeline with 1,000+ controlled experiments, which led to OpenThoughts3. Scaling the pipeline to 1.2M examples and using QwQ-32B as teacher yields our OpenThoughts3-7B model, which achieves state-of-the-art results: 53% on AIME 2025, 51% on LiveCodeBench 06/24-01/25, and 54% on GPQA Diamond - improvements of 15.3, 17.2, and 20.5 percentage points compared to the DeepSeek-R1-Distill-Qwen-7B. All of our datasets and models are available on https://openthoughts.ai.
Toward Holistic Evaluation of Recommender Systems Powered by Generative Models
Apr 09, 2025Recommender systems powered by generative models (Gen-RecSys) extend beyond classical item ranking by producing open-ended content, which simultaneously unlocks richer user experiences and introduces new risks. On one hand, these systems can enhance personalization and appeal through dynamic explanations and multi-turn dialogues. On the other hand, they might venture into unknown territory-hallucinating nonexistent items, amplifying bias, or leaking private information. Traditional accuracy metrics cannot fully capture these challenges, as they fail to measure factual correctness, content safety, or alignment with user intent. This paper makes two main contributions. First, we categorize the evaluation challenges of Gen-RecSys into two groups: (i) existing concerns that are exacerbated by generative outputs (e.g., bias, privacy) and (ii) entirely new risks (e.g., item hallucinations, contradictory explanations). Second, we propose a holistic evaluation approach that includes scenario-based assessments and multi-metric checks-incorporating relevance, factual grounding, bias detection, and policy compliance. Our goal is to provide a guiding framework so researchers and practitioners can thoroughly assess Gen-RecSys, ensuring effective personalization and responsible deployment.
A Review of Modern Recommender Systems Using Generative Models
Mar 31, 2024

Traditional recommender systems (RS) have used user-item rating histories as their primary data source, with collaborative filtering being one of the principal methods. However, generative models have recently developed abilities to model and sample from complex data distributions, including not only user-item interaction histories but also text, images, and videos - unlocking this rich data for novel recommendation tasks. Through this comprehensive and multi-disciplinary survey, we aim to connect the key advancements in RS using Generative Models (Gen-RecSys), encompassing: a foundational overview of interaction-driven generative models; the application of large language models (LLM) for generative recommendation, retrieval, and conversational recommendation; and the integration of multimodal models for processing and generating image and video content in RS. Our holistic perspective allows us to highlight necessary paradigms for evaluating the impact and harm of Gen-RecSys and identify open challenges. A more up-to-date version of the papers is maintained at: https://github.com/yasdel/LLM-RecSys.
Aligning Large Language Models with Recommendation Knowledge
Mar 30, 2024



Large language models (LLMs) have recently been used as backbones for recommender systems. However, their performance often lags behind conventional methods in standard tasks like retrieval. We attribute this to a mismatch between LLMs' knowledge and the knowledge crucial for effective recommendations. While LLMs excel at natural language reasoning, they cannot model complex user-item interactions inherent in recommendation tasks. We propose bridging the knowledge gap and equipping LLMs with recommendation-specific knowledge to address this. Operations such as Masked Item Modeling (MIM) and Bayesian Personalized Ranking (BPR) have found success in conventional recommender systems. Inspired by this, we simulate these operations through natural language to generate auxiliary-task data samples that encode item correlations and user preferences. Fine-tuning LLMs on such auxiliary-task data samples and incorporating more informative recommendation-task data samples facilitates the injection of recommendation-specific knowledge into LLMs. Extensive experiments across retrieval, ranking, and rating prediction tasks on LLMs such as FLAN-T5-Base and FLAN-T5-XL show the effectiveness of our technique in domains such as Amazon Toys & Games, Beauty, and Sports & Outdoors. Notably, our method outperforms conventional and LLM-based baselines, including the current SOTA, by significant margins in retrieval, showcasing its potential for enhancing recommendation quality.
Better Generalization with Semantic IDs: A case study in Ranking for Recommendations
Jun 13, 2023Training good representations for items is critical in recommender models. Typically, an item is assigned a unique randomly generated ID, and is commonly represented by learning an embedding corresponding to the value of the random ID. Although widely used, this approach have limitations when the number of items are large and items are power-law distributed -- typical characteristics of real-world recommendation systems. This leads to the item cold-start problem, where the model is unable to make reliable inferences for tail and previously unseen items. Removing these ID features and their learned embeddings altogether to combat cold-start issue severely degrades the recommendation quality. Content-based item embeddings are more reliable, but they are expensive to store and use, particularly for users' past item interaction sequence. In this paper, we use Semantic IDs, a compact discrete item representations learned from content embeddings using RQ-VAE that captures hierarchy of concepts in items. We showcase how we use them as a replacement of item IDs in a resource-constrained ranking model used in an industrial-scale video sharing platform. Moreover, we show how Semantic IDs improves the generalization ability of our system, without sacrificing top-level metrics.
Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction
May 10, 2023



Large Language Models (LLMs) have demonstrated exceptional capabilities in generalizing to new tasks in a zero-shot or few-shot manner. However, the extent to which LLMs can comprehend user preferences based on their previous behavior remains an emerging and still unclear research question. Traditionally, Collaborative Filtering (CF) has been the most effective method for these tasks, predominantly relying on the extensive volume of rating data. In contrast, LLMs typically demand considerably less data while maintaining an exhaustive world knowledge about each item, such as movies or products. In this paper, we conduct a thorough examination of both CF and LLMs within the classic task of user rating prediction, which involves predicting a user's rating for a candidate item based on their past ratings. We investigate various LLMs in different sizes, ranging from 250M to 540B parameters and evaluate their performance in zero-shot, few-shot, and fine-tuning scenarios. We conduct comprehensive analysis to compare between LLMs and strong CF methods, and find that zero-shot LLMs lag behind traditional recommender models that have the access to user interaction data, indicating the importance of user interaction data. However, through fine-tuning, LLMs achieve comparable or even better performance with only a small fraction of the training data, demonstrating their potential through data efficiency.
Recommender Systems with Generative Retrieval
May 08, 2023Modern recommender systems leverage large-scale retrieval models consisting of two stages: training a dual-encoder model to embed queries and candidates in the same space, followed by an Approximate Nearest Neighbor (ANN) search to select top candidates given a query's embedding. In this paper, we propose a new single-stage paradigm: a generative retrieval model which autoregressively decodes the identifiers for the target candidates in one phase. To do this, instead of assigning randomly generated atomic IDs to each item, we generate Semantic IDs: a semantically meaningful tuple of codewords for each item that serves as its unique identifier. We use a hierarchical method called RQ-VAE to generate these codewords. Once we have the Semantic IDs for all the items, a Transformer based sequence-to-sequence model is trained to predict the Semantic ID of the next item. Since this model predicts the tuple of codewords identifying the next item directly in an autoregressive manner, it can be considered a generative retrieval model. We show that our recommender system trained in this new paradigm improves the results achieved by current SOTA models on the Amazon dataset. Moreover, we demonstrate that the sequence-to-sequence model coupled with hierarchical Semantic IDs offers better generalization and hence improves retrieval of cold-start items for recommendations.
Improving Training Stability for Multitask Ranking Models in Recommender Systems
Feb 17, 2023



Recommender systems play an important role in many content platforms. While most recommendation research is dedicated to designing better models to improve user experience, we found that research on stabilizing the training for such models is severely under-explored. As recommendation models become larger and more sophisticated, they are more susceptible to training instability issues, \emph{i.e.}, loss divergence, which can make the model unusable, waste significant resources and block model developments. In this paper, we share our findings and best practices we learned for improving the training stability of a real-world multitask ranking model for YouTube recommendations. We show some properties of the model that lead to unstable training and conjecture on the causes. Furthermore, based on our observations of training dynamics near the point of training instability, we hypothesize why existing solutions would fail, and propose a new algorithm to mitigate the limitations of existing solutions. Our experiments on YouTube production dataset show the proposed algorithm can significantly improve training stability while not compromising convergence, comparing with several commonly used baseline methods.
Algorithms for Efficiently Learning Low-Rank Neural Networks
Feb 03, 2022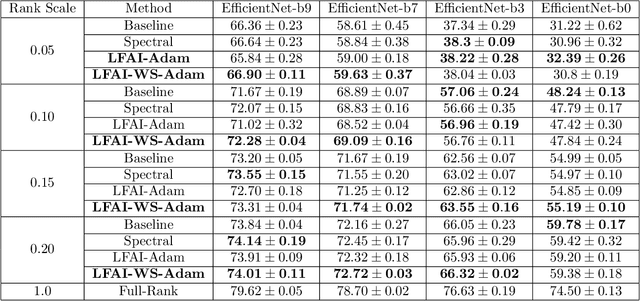
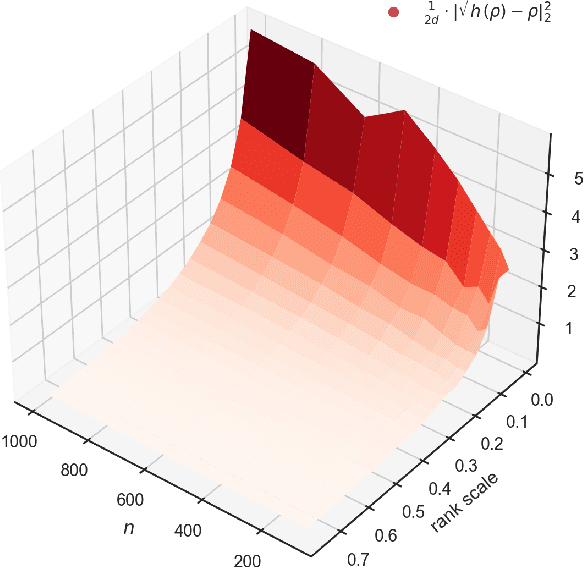
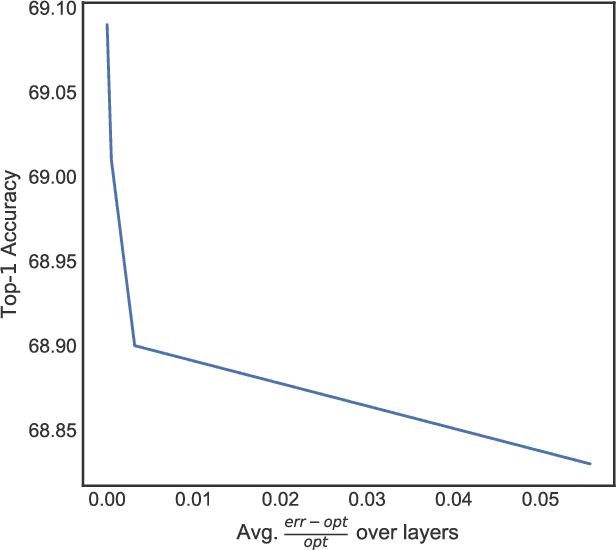

We study algorithms for learning low-rank neural networks -- networks where the weight parameters are re-parameterized by products of two low-rank matrices. First, we present a provably efficient algorithm which learns an optimal low-rank approximation to a single-hidden-layer ReLU network up to additive error $\epsilon$ with probability $\ge 1 - \delta$, given access to noiseless samples with Gaussian marginals in polynomial time and samples. Thus, we provide the first example of an algorithm which can efficiently learn a neural network up to additive error without assuming the ground truth is realizable. To solve this problem, we introduce an efficient SVD-based $\textit{Nonlinear Kernel Projection}$ algorithm for solving a nonlinear low-rank approximation problem over Gaussian space. Inspired by the efficiency of our algorithm, we propose a novel low-rank initialization framework for training low-rank $\textit{deep}$ networks, and prove that for ReLU networks, the gap between our method and existing schemes widens as the desired rank of the approximating weights decreases, or as the dimension of the inputs increases (the latter point holds when network width is superlinear in dimension). Finally, we validate our theory by training ResNet and EfficientNet models on ImageNet.
DSelect-k: Differentiable Selection in the Mixture of Experts with Applications to Multi-Task Learning
Jun 09, 2021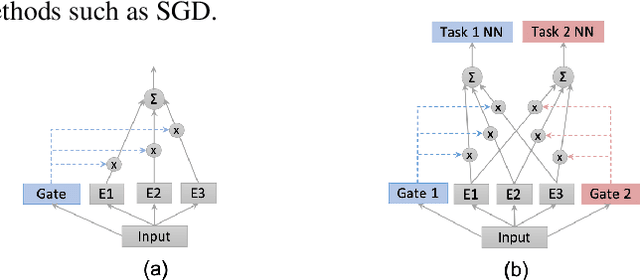
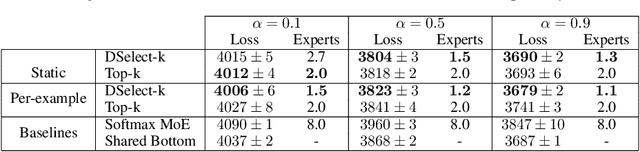
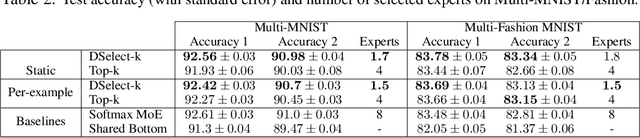
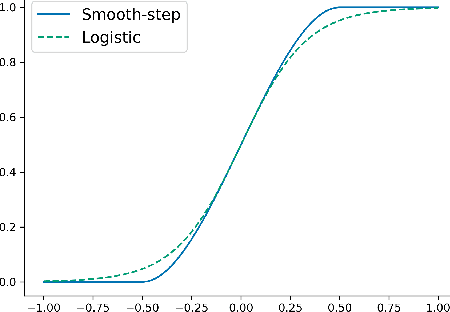
The Mixture-of-experts (MoE) architecture is showing promising results in multi-task learning (MTL) and in scaling high-capacity neural networks. State-of-the-art MoE models use a trainable sparse gate to select a subset of the experts for each input example. While conceptually appealing, existing sparse gates, such as Top-k, are not smooth. The lack of smoothness can lead to convergence and statistical performance issues when training with gradient-based methods. In this paper, we develop DSelect-k: the first, continuously differentiable and sparse gate for MoE, based on a novel binary encoding formulation. Our gate can be trained using first-order methods, such as stochastic gradient descent, and offers explicit control over the number of experts to select. We demonstrate the effectiveness of DSelect-k in the context of MTL, on both synthetic and real datasets with up to 128 tasks. Our experiments indicate that MoE models based on DSelect-k can achieve statistically significant improvements in predictive and expert selection performance. Notably, on a real-world large-scale recommender system, DSelect-k achieves over 22% average improvement in predictive performance compared to the Top-k gate. We provide an open-source TensorFlow implementation of our gate.