 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Training Stability for Multitask Ranking Models in Recommender Systems
Feb 17, 2023



Recommender systems play an important role in many content platforms. While most recommendation research is dedicated to designing better models to improve user experience, we found that research on stabilizing the training for such models is severely under-explored. As recommendation models become larger and more sophisticated, they are more susceptible to training instability issues, \emph{i.e.}, loss divergence, which can make the model unusable, waste significant resources and block model developments. In this paper, we share our findings and best practices we learned for improving the training stability of a real-world multitask ranking model for YouTube recommendations. We show some properties of the model that lead to unstable training and conjecture on the causes. Furthermore, based on our observations of training dynamics near the point of training instability, we hypothesize why existing solutions would fail, and propose a new algorithm to mitigate the limitations of existing solutions. Our experiments on YouTube production dataset show the proposed algorithm can significantly improve training stability while not compromising convergence, comparing with several commonly used baseline methods.
Revisiting Adversarially Learned Injection Attacks Against Recommender Systems
Aug 28, 2020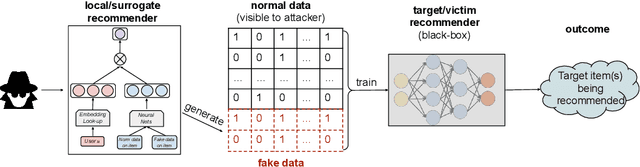

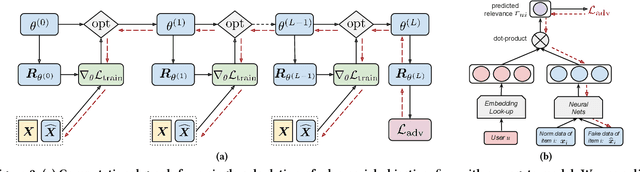

Recommender systems play an important role in modern information and e-commerce applications. While increasing research is dedicated to improving the relevance and diversity of the recommendations, the potential risks of state-of-the-art recommendation models are under-explored, that is, these models could be subject to attacks from malicious third parties, through injecting fake user interactions to achieve their purposes. This paper revisits the adversarially-learned injection attack problem, where the injected fake user `behaviors' are learned locally by the attackers with their own model -- one that is potentially different from the model under attack, but shares similar properties to allow attack transfer. We found that most existing works in literature suffer from two major limitations: (1) they do not solve the optimization problem precisely, making the attack less harmful than it could be, (2) they assume perfect knowledge for the attack, causing the lack of understanding for realistic attack capabilities. We demonstrate that the exact solution for generating fake users as an optimization problem could lead to a much larger impact. Our experiments on a real-world dataset reveal important properties of the attack, including attack transferability and its limitations. These findings can inspire useful defensive methods against this possible existing attack.
Understanding and Improving Knowledge Distillation
Feb 10, 2020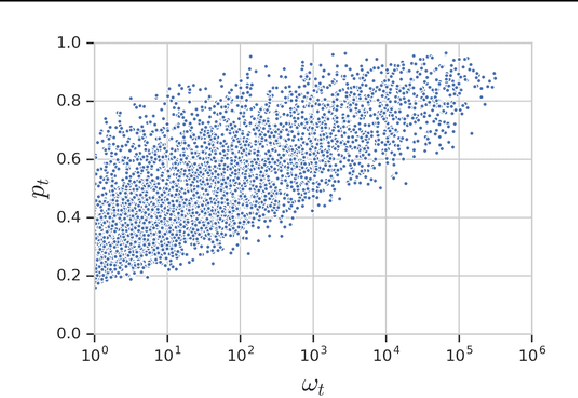
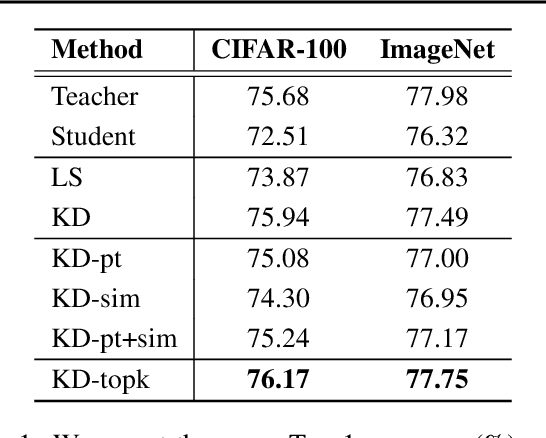
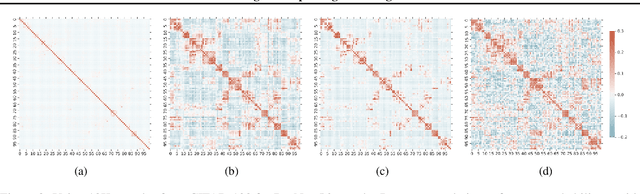
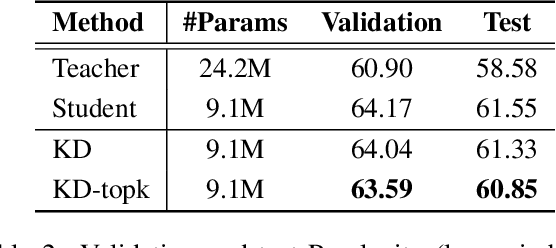
Knowledge distillation is a model-agnostic technique to improve model quality while having a fixed capacity budget. It is a commonly used technique for model compression, where a higher capacity teacher model with better quality is used to train a more compact student model with better inference efficiency. Through distillation, one hopes to benefit from student's compactness, without sacrificing too much on model quality. Despite the large success of knowledge distillation, better understanding of how it benefits student model's training dynamics remains under-explored. In this paper, we dissect the effects of knowledge distillation into three main factors: (1) benefits inherited from label smoothing, (2) example re-weighting based on teacher's confidence on ground-truth, and (3) prior knowledge of optimal output (logit) layer geometry. Using extensive systematic analyses and empirical studies on synthetic and real-world datasets, we confirm that the aforementioned three factors play a major role in knowledge distillation. Furthermore, based on our findings, we propose a simple, yet effective technique to improve knowledge distillation empirically.
Towards Neural Mixture Recommender for Long Range Dependent User Sequences
Feb 22, 2019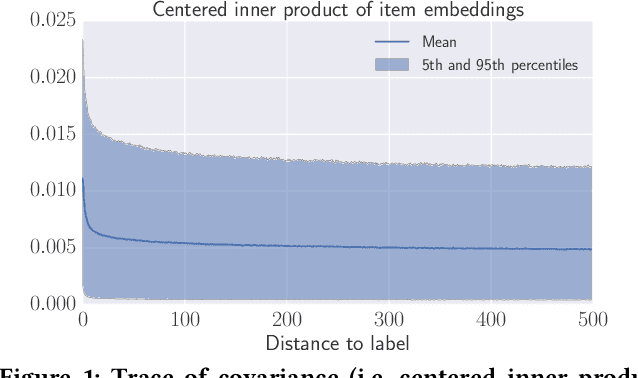

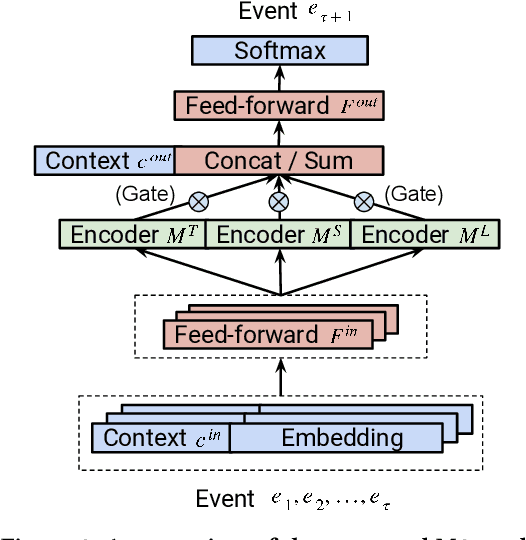
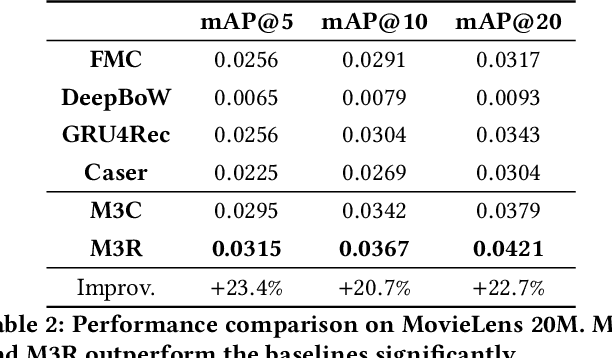
Understanding temporal dynamics has proved to be highly valuable for accurate recommendation. Sequential recommenders have been successful in modeling the dynamics of users and items over time. However, while different model architectures excel at capturing various temporal ranges or dynamics, distinct application contexts require adapting to diverse behaviors. In this paper we examine how to build a model that can make use of different temporal ranges and dynamics depending on the request context. We begin with the analysis of an anonymized Youtube dataset comprising millions of user sequences. We quantify the degree of long-range dependence in these sequences and demonstrate that both short-term and long-term dependent behavioral patterns co-exist. We then propose a neural Multi-temporal-range Mixture Model (M3) as a tailored solution to deal with both short-term and long-term dependencies. Our approach employs a mixture of models, each with a different temporal range. These models are combined by a learned gating mechanism capable of exerting different model combinations given different contextual information. In empirical evaluations on a public dataset and our own anonymized YouTube dataset, M3 consistently outperforms state-of-the-art sequential recommendation methods.
Ranking Distillation: Learning Compact Ranking Models With High Performance for Recommender System
Sep 19, 2018

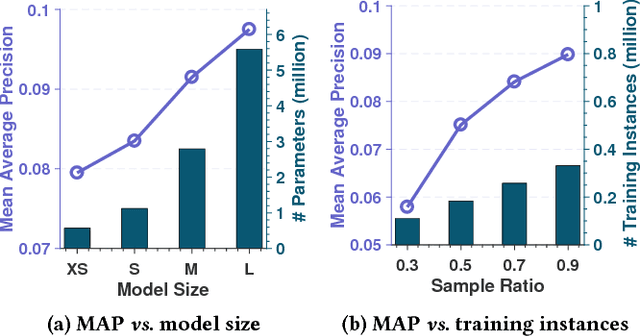

We propose a novel way to train ranking models, such as recommender systems, that are both effective and efficient. Knowledge distillation (KD) was shown to be successful in image recognition to achieve both effectiveness and efficiency. We propose a KD technique for learning to rank problems, called \emph{ranking distillation (RD)}. Specifically, we train a smaller student model to learn to rank documents/items from both the training data and the supervision of a larger teacher model. The student model achieves a similar ranking performance to that of the large teacher model, but its smaller model size makes the online inference more efficient. RD is flexible because it is orthogonal to the choices of ranking models for the teacher and student. We address the challenges of RD for ranking problems. The experiments on public data sets and state-of-the-art recommendation models showed that RD achieves its design purposes: the student model learnt with RD has a model size less than half of the teacher model while achieving a ranking performance similar to the teacher model and much better than the student model learnt without RD.
Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
Sep 19, 2018


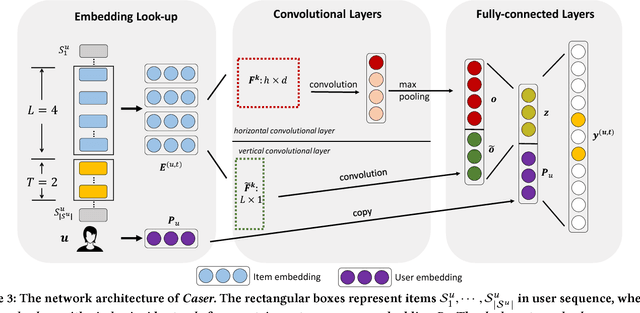
Top-$N$ sequential recommendation models each user as a sequence of items interacted in the past and aims to predict top-$N$ ranked items that a user will likely interact in a `near future'. The order of interaction implies that sequential patterns play an important role where more recent items in a sequence have a larger impact on the next item. In this paper, we propose a Convolutional Sequence Embedding Recommendation Model (\emph{Caser}) as a solution to address this requirement. The idea is to embed a sequence of recent items into an `image' in the time and latent spaces and learn sequential patterns as local features of the image using convolutional filters. This approach provides a unified and flexible network structure for capturing both general preferences and sequential patterns. The experiments on public datasets demonstrated that Caser consistently outperforms state-of-the-art sequential recommendation methods on a variety of common evaluation metrics.