 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking Distillation: Learning Compact Ranking Models With High Performance for Recommender System
Paper and Code


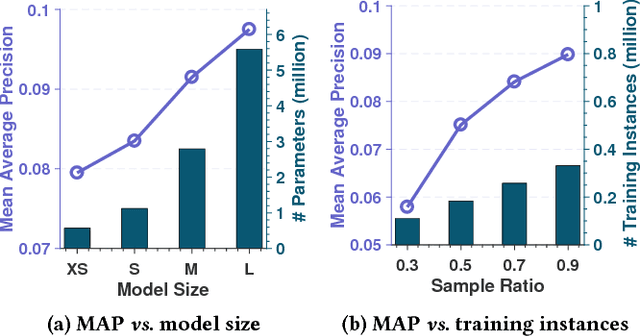

We propose a novel way to train ranking models, such as recommender systems, that are both effective and efficient. Knowledge distillation (KD) was shown to be successful in image recognition to achieve both effectiveness and efficiency. We propose a KD technique for learning to rank problems, called \emph{ranking distillation (RD)}. Specifically, we train a smaller student model to learn to rank documents/items from both the training data and the supervision of a larger teacher model. The student model achieves a similar ranking performance to that of the large teacher model, but its smaller model size makes the online inference more efficient. RD is flexible because it is orthogonal to the choices of ranking models for the teacher and student. We address the challenges of RD for ranking problems. The experiments on public data sets and state-of-the-art recommendation models showed that RD achieves its design purposes: the student model learnt with RD has a model size less than half of the teacher model while achieving a ranking performance similar to the teacher model and much better than the student model learnt without RD.