 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity Weighting for Multi-Interest Personalized Recommendation
Aug 03, 2023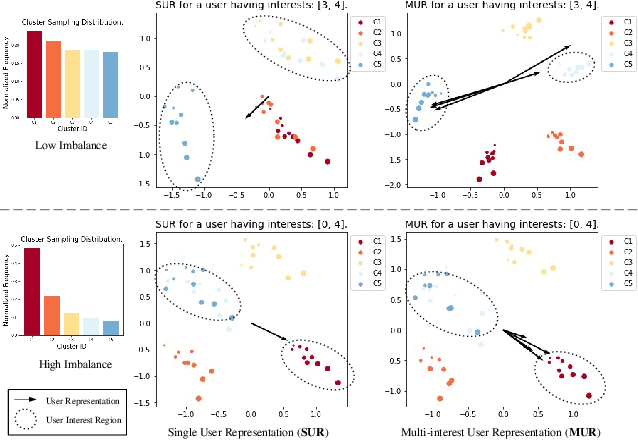


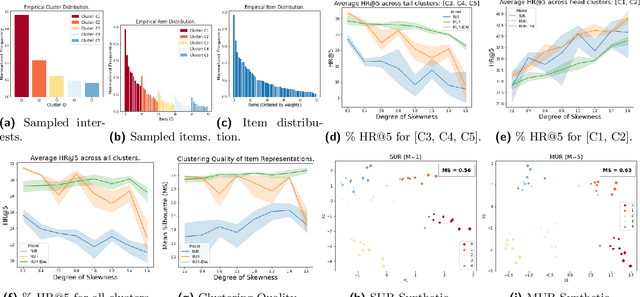
Using multiple user representations (MUR) to model user behavior instead of a single user representation (SUR) has been shown to improve personalization in recommendation systems. However, the performance gains observed with MUR can be sensitive to the skewness in the item and/or user interest distribution. When the data distribution is highly skewed, the gains observed by learning multiple representations diminish since the model dominates on head items/interests, leading to poor performance on tail items. Robustness to data sparsity is therefore essential for MUR-based approaches to achieve good performance for recommendations. Yet, research in MUR and data imbalance have largely been done independently. In this paper, we delve deeper into the shortcomings of MUR inferred from imbalanced data distributions. We make several contributions: (1) Using synthetic datasets, we demonstrate the sensitivity of MUR with respect to data imbalance, (2) To improve MUR for tail items, we propose an iterative density weighting scheme (IDW) with user tower calibration to mitigate the effect of training over long-tail distribution on personalization, and (3) Through extensive experiments on three real-world benchmarks, we demonstrate IDW outperforms other alternatives that address data imbalance.
Better Generalization with Semantic IDs: A case study in Ranking for Recommendations
Jun 13, 2023Training good representations for items is critical in recommender models. Typically, an item is assigned a unique randomly generated ID, and is commonly represented by learning an embedding corresponding to the value of the random ID. Although widely used, this approach have limitations when the number of items are large and items are power-law distributed -- typical characteristics of real-world recommendation systems. This leads to the item cold-start problem, where the model is unable to make reliable inferences for tail and previously unseen items. Removing these ID features and their learned embeddings altogether to combat cold-start issue severely degrades the recommendation quality. Content-based item embeddings are more reliable, but they are expensive to store and use, particularly for users' past item interaction sequence. In this paper, we use Semantic IDs, a compact discrete item representations learned from content embeddings using RQ-VAE that captures hierarchy of concepts in items. We showcase how we use them as a replacement of item IDs in a resource-constrained ranking model used in an industrial-scale video sharing platform. Moreover, we show how Semantic IDs improves the generalization ability of our system, without sacrificing top-level metrics.
Recommender Systems with Generative Retrieval
May 08, 2023Modern recommender systems leverage large-scale retrieval models consisting of two stages: training a dual-encoder model to embed queries and candidates in the same space, followed by an Approximate Nearest Neighbor (ANN) search to select top candidates given a query's embedding. In this paper, we propose a new single-stage paradigm: a generative retrieval model which autoregressively decodes the identifiers for the target candidates in one phase. To do this, instead of assigning randomly generated atomic IDs to each item, we generate Semantic IDs: a semantically meaningful tuple of codewords for each item that serves as its unique identifier. We use a hierarchical method called RQ-VAE to generate these codewords. Once we have the Semantic IDs for all the items, a Transformer based sequence-to-sequence model is trained to predict the Semantic ID of the next item. Since this model predicts the tuple of codewords identifying the next item directly in an autoregressive manner, it can be considered a generative retrieval model. We show that our recommender system trained in this new paradigm improves the results achieved by current SOTA models on the Amazon dataset. Moreover, we demonstrate that the sequence-to-sequence model coupled with hierarchical Semantic IDs offers better generalization and hence improves retrieval of cold-start items for recommendations.
Understanding and Improving Knowledge Distillation
Feb 10, 2020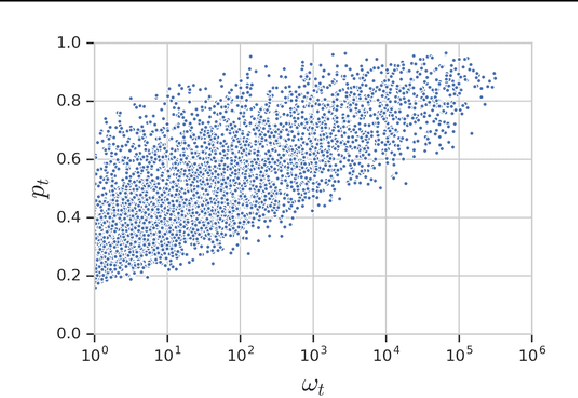
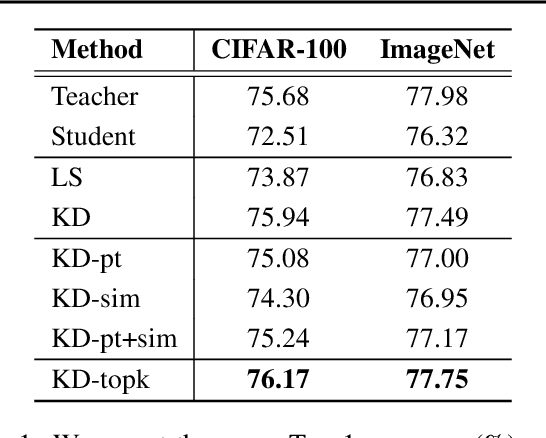
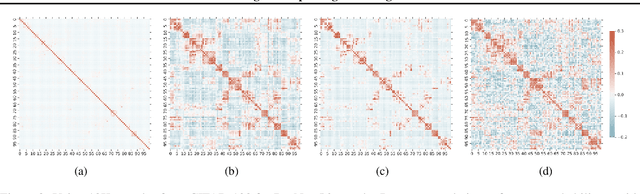
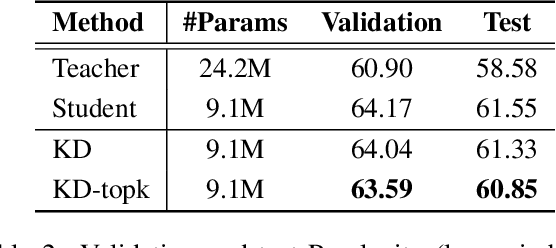
Knowledge distillation is a model-agnostic technique to improve model quality while having a fixed capacity budget. It is a commonly used technique for model compression, where a higher capacity teacher model with better quality is used to train a more compact student model with better inference efficiency. Through distillation, one hopes to benefit from student's compactness, without sacrificing too much on model quality. Despite the large success of knowledge distillation, better understanding of how it benefits student model's training dynamics remains under-explored. In this paper, we dissect the effects of knowledge distillation into three main factors: (1) benefits inherited from label smoothing, (2) example re-weighting based on teacher's confidence on ground-truth, and (3) prior knowledge of optimal output (logit) layer geometry. Using extensive systematic analyses and empirical studies on synthetic and real-world datasets, we confirm that the aforementioned three factors play a major role in knowledge distillation. Furthermore, based on our findings, we propose a simple, yet effective technique to improve knowledge distillation empirically.