 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORBIT: Preserving Foundational Language Capabilities in GenRetrieval via Origin-Regulated Merging
May 12, 2026Despite the rapid advancements in large language model (LLM) development, fine-tuning them for specific tasks often results in the catastrophic forgetting of their general, language-based reasoning abilities. This work investigates and addresses this challenge in the context of the Generative Retrieval (GenRetrieval) task. During GenRetrieval fine-tuning, we find this forgetting occurs rapidly and correlates with the distance between the fine-tuned and original model parameters. Given these observations, we propose ORBIT, a novel approach that actively tracks the distance between fine-tuned and initial model weights, and uses a weight averaging strategy to constrain model drift during GenRetrieval fine-tuning when this inter-model distance exceeds a maximum threshold. Our results show that ORBIT retains substantial text and retrieval performance by outperforming both common continual learning baselines and related regularization methods that also employ weight averaging.
A Proposed Biomedical Data Policy Framework to Reduce Fragmentation, Improve Quality, and Incentivize Sharing in Indian Healthcare in the era of Artificial Intelligence and Digital Health
Apr 13, 2026India generates vast biomedical data through postgraduate research, government hospital services and audits, government schemes, private hospitals and their electronic medical record (EMR) systems, insurance programs and standalone clinics. Unfortunately, these resources remain fragmented across institutional silos and vendor-locked EMR systems. The fundamental bottleneck is not technological but economic and academic. There is a systemic misalignment of incentives that renders data sharing a high-risk, low-reward activity for individual researchers and institutions. Until India's academic promotion criteria, institutional rankings, and funding mechanisms explicitly recognize and reward data curation as professional work, the nation's AI ambitions will remain constrained by fragmented, non-interoperable datasets. We propose a multi-layered incentive architecture integrating recognition of data papers in National Medical Commission (NMC) promotion criteria, incorporation of open data metrics into the National Institutional Ranking Framework (NIRF), adoption of Shapley Value-based revenue sharing in federated learning consortia, and establishment of institutional data stewardship as a mainstream professional role. Critical barriers to data sharing, including fear of data quality scrutiny, concerns about misinterpretation, and selective reporting bias, are addressed through mandatory data quality assessment, structured peer review, and academic credit for auditing roles. The proposed framework directly addresses regulatory constraints introduced by the Digital Personal Data Protection Act 2023 (DPDPA), while constructively engaging with the National Data Sharing and Accessibility Policy (NDSAP), Biotech-PRIDE Guidelines, and the Anusandhan National Research Foundation (ANRF) guidelines.
The Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
PLUM: Adapting Pre-trained Language Models for Industrial-scale Generative Recommendations
Oct 09, 2025Large Language Models (LLMs) pose a new paradigm of modeling and computation for information tasks. Recommendation systems are a critical application domain poised to benefit significantly from the sequence modeling capabilities and world knowledge inherent in these large models. In this paper, we introduce PLUM, a framework designed to adapt pre-trained LLMs for industry-scale recommendation tasks. PLUM consists of item tokenization using Semantic IDs, continued pre-training (CPT) on domain-specific data, and task-specific fine-tuning for recommendation objectives. For fine-tuning, we focus particularly on generative retrieval, where the model is directly trained to generate Semantic IDs of recommended items based on user context. We conduct comprehensive experiments on large-scale internal video recommendation datasets. Our results demonstrate that PLUM achieves substantial improvements for retrieval compared to a heavily-optimized production model built with large embedding tables. We also present a scaling study for the model's retrieval performance, our learnings about CPT, a few enhancements to Semantic IDs, along with an overview of the training and inference methods that enable launching this framework to billions of users in YouTube.
Talking Point based Ideological Discourse Analysis in News Events
Apr 10, 2025Analyzing ideological discourse even in the age of LLMs remains a challenge, as these models often struggle to capture the key elements that shape real-world narratives. Specifically, LLMs fail to focus on characteristic elements driving dominant discourses and lack the ability to integrate contextual information required for understanding abstract ideological views. To address these limitations, we propose a framework motivated by the theory of ideological discourse analysis to analyze news articles related to real-world events. Our framework represents the news articles using a relational structure - talking points, which captures the interaction between entities, their roles, and media frames along with a topic of discussion. It then constructs a vocabulary of repeating themes - prominent talking points, that are used to generate ideology-specific viewpoints (or partisan perspectives). We evaluate our framework's ability to generate these perspectives through automated tasks - ideology and partisan classification tasks, supplemented by human validation. Additionally, we demonstrate straightforward applicability of our framework in creating event snapshots, a visual way of interpreting event discourse. We release resulting dataset and model to the community to support further research.
Toward Holistic Evaluation of Recommender Systems Powered by Generative Models
Apr 09, 2025Recommender systems powered by generative models (Gen-RecSys) extend beyond classical item ranking by producing open-ended content, which simultaneously unlocks richer user experiences and introduces new risks. On one hand, these systems can enhance personalization and appeal through dynamic explanations and multi-turn dialogues. On the other hand, they might venture into unknown territory-hallucinating nonexistent items, amplifying bias, or leaking private information. Traditional accuracy metrics cannot fully capture these challenges, as they fail to measure factual correctness, content safety, or alignment with user intent. This paper makes two main contributions. First, we categorize the evaluation challenges of Gen-RecSys into two groups: (i) existing concerns that are exacerbated by generative outputs (e.g., bias, privacy) and (ii) entirely new risks (e.g., item hallucinations, contradictory explanations). Second, we propose a holistic evaluation approach that includes scenario-based assessments and multi-metric checks-incorporating relevance, factual grounding, bias detection, and policy compliance. Our goal is to provide a guiding framework so researchers and practitioners can thoroughly assess Gen-RecSys, ensuring effective personalization and responsible deployment.
Building a Mind Palace: Structuring Environment-Grounded Semantic Graphs for Effective Long Video Analysis with LLMs
Jan 08, 2025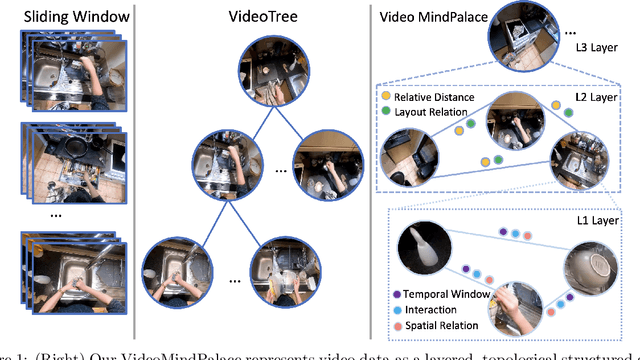
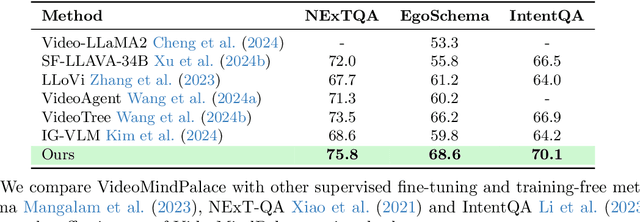
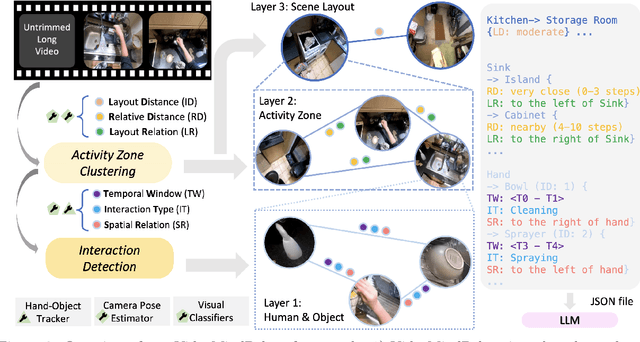
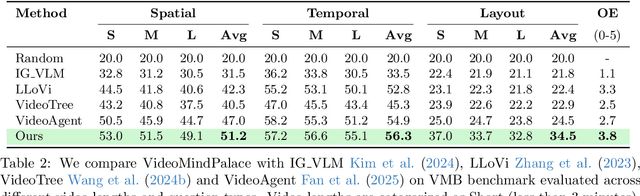
Long-form video understanding with Large Vision Language Models is challenged by the need to analyze temporally dispersed yet spatially concentrated key moments within limited context windows. In this work, we introduce VideoMindPalace, a new framework inspired by the "Mind Palace", which organizes critical video moments into a topologically structured semantic graph. VideoMindPalace organizes key information through (i) hand-object tracking and interaction, (ii) clustered activity zones representing specific areas of recurring activities, and (iii) environment layout mapping, allowing natural language parsing by LLMs to provide grounded insights on spatio-temporal and 3D context. In addition, we propose the Video MindPalace Benchmark (VMB), to assess human-like reasoning, including spatial localization, temporal reasoning, and layout-aware sequential understanding. Evaluated on VMB and established video QA datasets, including EgoSchema, NExT-QA, IntentQA, and the Active Memories Benchmark, VideoMindPalace demonstrates notable gains in spatio-temporal coherence and human-aligned reasoning, advancing long-form video analysis capabilities in VLMs.
Apollo: An Exploration of Video Understanding in Large Multimodal Models
Dec 13, 2024



Despite the rapid integration of video perception capabilities into Large Multimodal Models (LMMs), the underlying mechanisms driving their video understanding remain poorly understood. Consequently, many design decisions in this domain are made without proper justification or analysis. The high computational cost of training and evaluating such models, coupled with limited open research, hinders the development of video-LMMs. To address this, we present a comprehensive study that helps uncover what effectively drives video understanding in LMMs. We begin by critically examining the primary contributors to the high computational requirements associated with video-LMM research and discover Scaling Consistency, wherein design and training decisions made on smaller models and datasets (up to a critical size) effectively transfer to larger models. Leveraging these insights, we explored many video-specific aspects of video-LMMs, including video sampling, architectures, data composition, training schedules, and more. For example, we demonstrated that fps sampling during training is vastly preferable to uniform frame sampling and which vision encoders are the best for video representation. Guided by these findings, we introduce Apollo, a state-of-the-art family of LMMs that achieve superior performance across different model sizes. Our models can perceive hour-long videos efficiently, with Apollo-3B outperforming most existing $7$B models with an impressive 55.1 on LongVideoBench. Apollo-7B is state-of-the-art compared to 7B LMMs with a 70.9 on MLVU, and 63.3 on Video-MME.
Performance of a large language model-Artificial Intelligence based chatbot for counseling patients with sexually transmitted infections and genital diseases
Dec 11, 2024Introduction: Global burden of sexually transmitted infections (STIs) is rising out of proportion to specialists. Current chatbots like ChatGPT are not tailored for handling STI-related concerns out of the box. We developed Otiz, an Artificial Intelligence-based (AI-based) chatbot platform designed specifically for STI detection and counseling, and assessed its performance. Methods: Otiz employs a multi-agent system architecture based on GPT4-0613, leveraging large language model (LLM) and Deterministic Finite Automaton principles to provide contextually relevant, medically accurate, and empathetic responses. Its components include modules for general STI information, emotional recognition, Acute Stress Disorder detection, and psychotherapy. A question suggestion agent operates in parallel. Four STIs (anogenital warts, herpes, syphilis, urethritis/cervicitis) and 2 non-STIs (candidiasis, penile cancer) were evaluated using prompts mimicking patient language. Each prompt was independently graded by two venereologists conversing with Otiz as patient actors on 6 criteria using Numerical Rating Scale ranging from 0 (poor) to 5 (excellent). Results: Twenty-three venereologists did 60 evaluations of 30 prompts. Across STIs, Otiz scored highly on diagnostic accuracy (4.1-4.7), overall accuracy (4.3-4.6), correctness of information (5.0), comprehensibility (4.2-4.4), and empathy (4.5-4.8). However, relevance scores were lower (2.9-3.6), suggesting some redundancy. Diagnostic scores for non-STIs were lower (p=0.038). Inter-observer agreement was strong, with differences greater than 1 point occurring in only 12.7% of paired evaluations. Conclusions: AI conversational agents like Otiz can provide accurate, correct, discrete, non-judgmental, readily accessible and easily understandable STI-related information in an empathetic manner, and can alleviate the burden on healthcare systems.
Unleashing In-context Learning of Autoregressive Models for Few-shot Image Manipulation
Dec 03, 2024



Text-guided image manipulation has experienced notable advancement in recent years. In order to mitigate linguistic ambiguity, few-shot learning with visual examples has been applied for instructions that are underrepresented in the training set, or difficult to describe purely in language. However, learning from visual prompts requires strong reasoning capability, which diffusion models are struggling with. To address this issue, we introduce a novel multi-modal autoregressive model, dubbed $\textbf{InstaManip}$, that can $\textbf{insta}$ntly learn a new image $\textbf{manip}$ulation operation from textual and visual guidance via in-context learning, and apply it to new query images. Specifically, we propose an innovative group self-attention mechanism to break down the in-context learning process into two separate stages -- learning and applying, which simplifies the complex problem into two easier tasks. We also introduce a relation regularization method to further disentangle image transformation features from irrelevant contents in exemplar images. Extensive experiments suggest that our method surpasses previous few-shot image manipulation models by a notable margin ($\geq$19% in human evaluation). We also find our model can be further boosted by increasing the number or diversity of exemplar images.