 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Improving Hyperparameter Optimization with Checkpointed Model Weights
Jun 26, 2024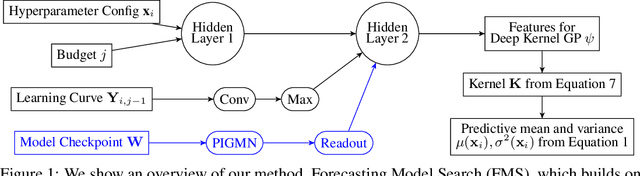
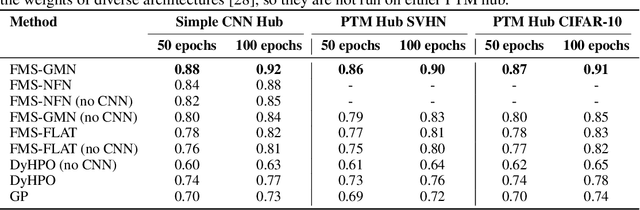
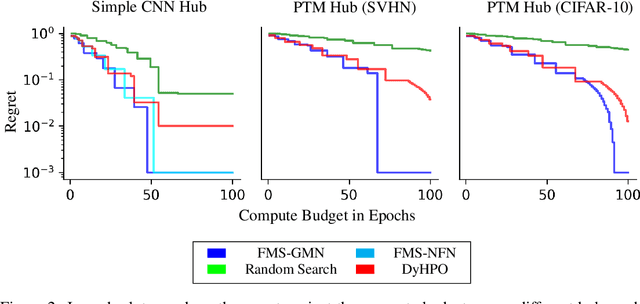

When training deep learning models, the performance depends largely on the selected hyperparameters. However, hyperparameter optimization (HPO) is often one of the most expensive parts of model design. Classical HPO methods treat this as a black-box optimization problem. However, gray-box HPO methods, which incorporate more information about the setup, have emerged as a promising direction for more efficient optimization. For example, using intermediate loss evaluations to terminate bad selections. In this work, we propose an HPO method for neural networks using logged checkpoints of the trained weights to guide future hyperparameter selections. Our method, Forecasting Model Search (FMS), embeds weights into a Gaussian process deep kernel surrogate model, using a permutation-invariant graph metanetwork to be data-efficient with the logged network weights. To facilitate reproducibility and further research, we open-source our code at https://github.com/NVlabs/forecasting-model-search.
Data-centric Artificial Intelligence: A Survey
Apr 02, 2023Artificial Intelligence (AI) is making a profound impact in almost every domain. A vital enabler of its great success is the availability of abundant and high-quality data for building machine learning models. Recently, the role of data in AI has been significantly magnified, giving rise to the emerging concept of data-centric AI. The attention of researchers and practitioners has gradually shifted from advancing model design to enhancing the quality and quantity of the data. In this survey, we discuss the necessity of data-centric AI, followed by a holistic view of three general data-centric goals (training data development, inference data development, and data maintenance) and the representative methods. We also organize the existing literature from automation and collaboration perspectives, discuss the challenges, and tabulate the benchmarks for various tasks. We believe this is the first comprehensive survey that provides a global view of a spectrum of tasks across various stages of the data lifecycle. We hope it can help the readers efficiently grasp a broad picture of this field, and equip them with the techniques and further research ideas to systematically engineer data for building AI systems. A companion list of data-centric AI resources will be regularly updated on https://github.com/daochenzha/data-centric-AI
Data-centric AI: Perspectives and Challenges
Jan 12, 2023The role of data in building AI systems has recently been significantly magnified by the emerging concept of data-centric AI (DCAI), which advocates a fundamental shift from model advancements to ensuring data quality and reliability. Although our community has continuously invested efforts into enhancing data in different aspects, they are often isolated initiatives on specific tasks. To facilitate the collective initiative in our community and push forward DCAI, we draw a big picture and bring together three general missions: training data development, evaluation data development, and data maintenance. We provide a top-level discussion on representative DCAI tasks and share perspectives. Finally, we list open challenges to motivate future exploration.
BED: A Real-Time Object Detection System for Edge Devices
Feb 14, 2022


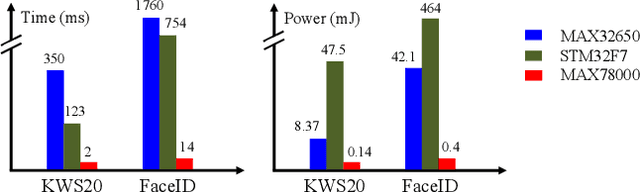
Deploying machine learning models to edge devices has many real-world applications, especially for the scenarios that demand low latency, low power, or data privacy. However, it requires substantial research and engineering efforts due to the limited computational resources and memory of edge devices. In this demo, we present BED, an object detection system for edge devices practiced on the MAX78000 DNN accelerator. BED integrates on-device DNN inference with a camera and a screen for image acquisition and output exhibition, respectively. Experiment results indicate BED can provide accurate detection with an only 300KB tiny DNN model.
AutoVideo: An Automated Video Action Recognition System
Aug 10, 2021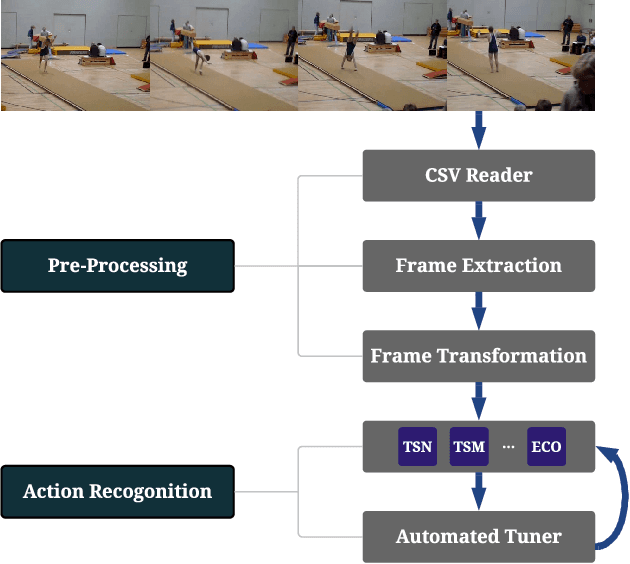

Action recognition is a crucial task for video understanding. In this paper, we present AutoVideo, a Python system for automated video action recognition. It currently supports seven action recognition algorithms and various pre-processing modules. Unlike the existing libraries that only provide model zoos, AutoVideo is built with the standard pipeline language. The basic building block is primitive, which wraps a pre-processing module or an algorithm with some hyperparameters. AutoVideo is highly modular and extendable. It can be easily combined with AutoML searchers. The pipeline language is quite general so that we can easily enrich AutoVideo with algorithms for various other video-related tasks in the future. AutoVideo is released under MIT license at https://github.com/datamllab/autovideo