 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRASFT: Rollout-Adaptive Supervised Fine-Tuning for Reasoning
Jun 05, 2026Supervised fine-tuning (SFT) is a prevailing method for adapting large language models to reasoning tasks by imitating offline expert demonstrations, often treating a single expert trajectory as the target behavior. However, reasoning is not simple path imitation: rigidly following one demonstrated solution may overfit to surface forms and suppress the model's own reasoning distribution. We propose Rollout-Adaptive Supervised Fine-Tuning (RASFT), a policy-aware SFT framework that calibrates expert supervision according to problem-level solvability estimated from verified on-policy rollouts. For each problem, RASFT strengthens expert guidance when the current policy struggles, while relaxing rigid imitation and incorporating correct self-generated trajectories when the model already exhibits reliable reasoning behavior. To preserve useful reasoning priors, RASFT further introduces a clipped inverse ratio between the frozen reference model and the current policy to constrain excessive policy drift. Experiments across multiple models on six mathematical reasoning benchmarks and two code reasoning benchmarks show that RASFT achieves better overall performance than SFT, SFT variants, and representative RL methods. The code is available at https://github.com/zjd1sq/RASFT.
PrivacyPeek: Auditing What LLM-Based Agents Acquire, Not Just What They Say
May 29, 2026LLM-based agents are rapidly advancing, autonomously invoking external tools to complete multi-step tasks for users. However, agents often acquire more sensitive information than the task requires. Existing privacy benchmarks audit what the agent's response or outgoing actions disclose, but overlook the acquisition stage where data first enters the agent's context. The over-acquired information is then one careless action or one attack away from an outright leak. To assess its prevalence, we introduce \emph{PrivacyPeek}, a benchmark for evaluating acquisition-stage privacy leakage of LLM-based agents, with $1{,}182$ cases across $7$ acquisition behaviours and $16$ application domains. Specifically, \emph{Acquisition Inspection} examines the agent's tool-call trajectory, both the tools it invokes and the data it receives, to detect when it acquires sensitive information beyond the task scope. \emph{Probe Elicitation} then issues a follow-up probe and measures how readily an attacker could elicit sensitive information the agent acquired but did not disclose. Our experiments on 10 LLM-based agents across 4 model families show that the unnecessary acquisition of sensitive information is widespread. In addition, we observe a correlation between the task-completion capability and acquisition-stage leakage. Prompt-level defences reduce only a small fraction of acquisition-stage leakage, leaving the majority unmitigated. These results make auditing acquisition-stage privacy both urgent and necessary. Our dataset and code are available at https://github.com/Xuan269/PrivacyPeek-Resource.
SkillsInjector: Dynamic Skill Context Construction for LLM Agents
May 28, 2026LLM agents now draw on growing skill libraries to handle complex tasks. However, injecting more skills does not always improve task completion and can even degrade it. Existing methods still treat skill injection as a static step, selecting skills with fixed criteria, fixing the budget in advance, and leaving descriptions unchanged. We argue that this static treatment can undermine the utility of skills, because which skills are exposed, how many are included, and how they are presented all affect downstream performance. We propose SkillsInjector, a two-stage adaptive method that jointly addresses these decisions. First, a context planner learns execution-grounded skill preferences and admits an adaptive number of skills for each task. A set-aware renderer then tailors how selected descriptions are presented relative to their co-injected neighbors. Across tau2-bench, SkillsBench, and ALFWorld, SkillsInjector achieves the highest score, improving over the strongest baseline by 3.9, 6.1, and 7.3 percentage points, respectively. Ablation studies show that skill selection, adaptive budgeting, and set-aware rendering each contribute to the gain. These results show that skill-augmented agents benefit from optimizing the injected context itself. Code will be released upon publication
The LLM Data Auditor: A Metric-oriented Survey on Quality and Trustworthiness in Evaluating Synthetic Data
Jan 27, 2026Large Language Models (LLMs) have emerged as powerful tools for generating data across various modalities. By transforming data from a scarce resource into a controllable asset, LLMs mitigate the bottlenecks imposed by the acquisition costs of real-world data for model training, evaluation, and system iteration. However, ensuring the high quality of LLM-generated synthetic data remains a critical challenge. Existing research primarily focuses on generation methodologies, with limited direct attention to the quality of the resulting data. Furthermore, most studies are restricted to single modalities, lacking a unified perspective across different data types. To bridge this gap, we propose the \textbf{LLM Data Auditor framework}. In this framework, we first describe how LLMs are utilized to generate data across six distinct modalities. More importantly, we systematically categorize intrinsic metrics for evaluating synthetic data from two dimensions: quality and trustworthiness. This approach shifts the focus from extrinsic evaluation, which relies on downstream task performance, to the inherent properties of the data itself. Using this evaluation system, we analyze the experimental evaluations of representative generation methods for each modality and identify substantial deficiencies in current evaluation practices. Based on these findings, we offer concrete recommendations for the community to improve the evaluation of data generation. Finally, the framework outlines methodologies for the practical application of synthetic data across different modalities.
Cleansing the Artificial Mind: A Self-Reflective Detoxification Framework for Large Language Models
Jan 16, 2026Recent breakthroughs in Large Language Models (LLMs) have revealed remarkable generative capabilities and emerging self-regulatory mechanisms, including self-correction and self-rewarding. However, current detoxification techniques rarely exploit these built-in abilities; instead, they rely on external modules, labor-intensive data annotation, or human intervention --factors that hinder scalability and consistency. In this paper, we introduce a fully self-reflective detoxification framework that harnesses the inherent capacities of LLMs to detect, correct toxic content, and refine LLMs without external modules and data annotation. Specifically, we propose a Toxic Signal Detector --an internal self-identification mechanism, coupled with a systematic intervention process to transform toxic text into its non-toxic counterpart. This iterative procedure yields a contrastive detoxification dataset used to fine-tune the model, enhancing its ability for safe and coherent text generation. Experiments on benchmark datasets such as DetoxLLM and ParaDetox show that our method achieves better detoxification performance than state-of-the-art methods while preserving semantic fidelity. By obviating the need for human intervention or external components, this paper reveals the intrinsic self-detoxification ability of LLMs, offering a consistent and effective approach for mitigating harmful content generation. Ultimately, our findings underscore the potential for truly self-regulated language models, paving the way for more responsible and ethically guided text generation systems.
Rethinking the Understanding Ability across LLMs through Mutual Information
May 25, 2025Recent advances in large language models (LLMs) have revolutionized natural language processing, yet evaluating their intrinsic linguistic understanding remains challenging. Moving beyond specialized evaluation tasks, we propose an information-theoretic framework grounded in mutual information (MI) to achieve this. We formalize the understanding as MI between an input sentence and its latent representation (sentence-level MI), measuring how effectively input information is preserved in latent representation. Given that LLMs learn embeddings for individual tokens, we decompose sentence-level MI into token-level MI between tokens and sentence embeddings, establishing theoretical bounds connecting these measures. Based on this foundation, we theoretically derive a computable lower bound for token-level MI using Fano's inequality, which directly relates to token-level recoverability-the ability to predict original tokens from sentence embedding. We implement this recoverability task to comparatively measure MI across different LLMs, revealing that encoder-only models consistently maintain higher information fidelity than their decoder-only counterparts, with the latter exhibiting a distinctive late-layer "forgetting" pattern where mutual information is first enhanced and then discarded. Moreover, fine-tuning to maximize token-level recoverability consistently improves understanding ability of LLMs on tasks without task-specific supervision, demonstrating that mutual information can serve as a foundation for understanding and improving language model capabilities.
MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation
Dec 31, 2024



Large Language Models (LLMs) are becoming essential tools for various natural language processing tasks but often suffer from generating outdated or incorrect information. Retrieval-Augmented Generation (RAG) addresses this issue by incorporating external, real-time information retrieval to ground LLM responses. However, the existing RAG systems frequently struggle with the quality of retrieval documents, as irrelevant or noisy documents degrade performance, increase computational overhead, and undermine response reliability. To tackle this problem, we propose Multi-Agent Filtering Retrieval-Augmented Generation (MAIN-RAG), a training-free RAG framework that leverages multiple LLM agents to collaboratively filter and score retrieved documents. Specifically, MAIN-RAG introduces an adaptive filtering mechanism that dynamically adjusts the relevance filtering threshold based on score distributions, effectively minimizing noise while maintaining high recall of relevant documents. The proposed approach leverages inter-agent consensus to ensure robust document selection without requiring additional training data or fine-tuning. Experimental results across four QA benchmarks demonstrate that MAIN-RAG consistently outperforms traditional RAG approaches, achieving a 2-11% improvement in answer accuracy while reducing the number of irrelevant retrieved documents. Quantitative analysis further reveals that our approach achieves superior response consistency and answer accuracy over baseline methods, offering a competitive and practical alternative to training-based solutions.
Gradient Rewiring for Editable Graph Neural Network Training
Oct 21, 2024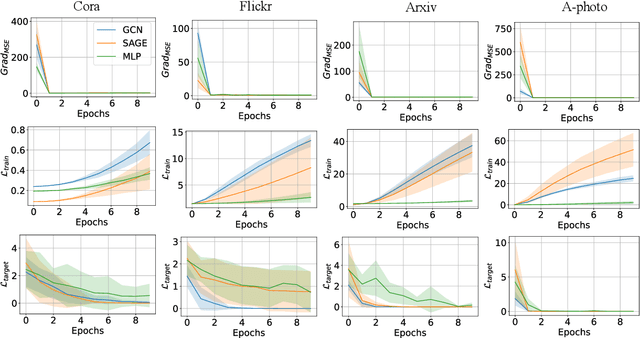
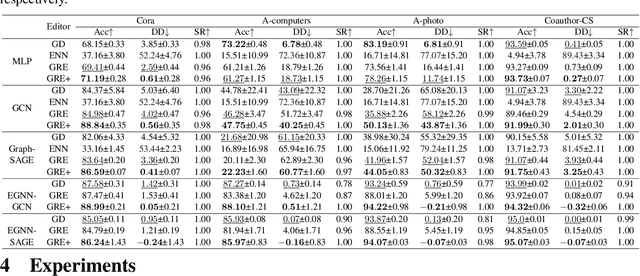
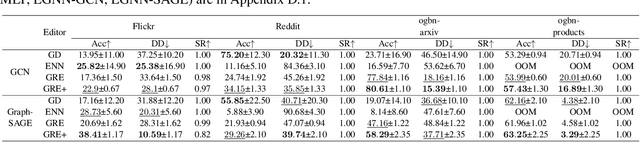
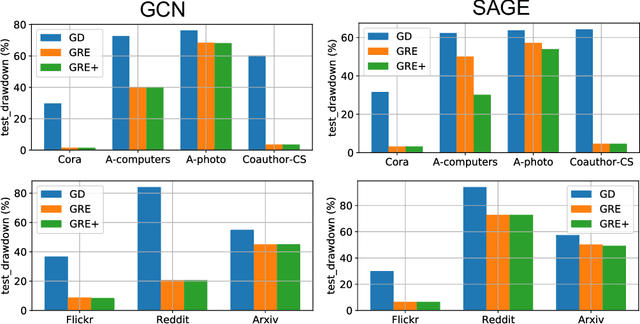
Deep neural networks are ubiquitously adopted in many applications, such as computer vision, natural language processing, and graph analytics. However, well-trained neural networks can make prediction errors after deployment as the world changes. \textit{Model editing} involves updating the base model to correct prediction errors with less accessible training data and computational resources. Despite recent advances in model editors in computer vision and natural language processing, editable training in graph neural networks (GNNs) is rarely explored. The challenge with editable GNN training lies in the inherent information aggregation across neighbors, which can lead model editors to affect the predictions of other nodes unintentionally. In this paper, we first observe the gradient of cross-entropy loss for the target node and training nodes with significant inconsistency, which indicates that directly fine-tuning the base model using the loss on the target node deteriorates the performance on training nodes. Motivated by the gradient inconsistency observation, we propose a simple yet effective \underline{G}radient \underline{R}ewiring method for \underline{E}ditable graph neural network training, named \textbf{GRE}. Specifically, we first store the anchor gradient of the loss on training nodes to preserve the locality. Subsequently, we rewire the gradient of the loss on the target node to preserve performance on the training node using anchor gradient. Experiments demonstrate the effectiveness of GRE on various model architectures and graph datasets in terms of multiple editing situations. The source code is available at \url{https://github.com/zhimengj0326/Gradient_rewiring_editing}
IDEA: A Flexible Framework of Certified Unlearning for Graph Neural Networks
Jul 28, 2024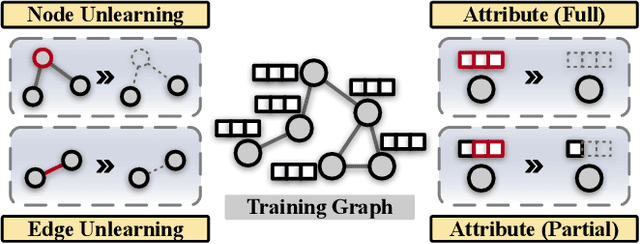
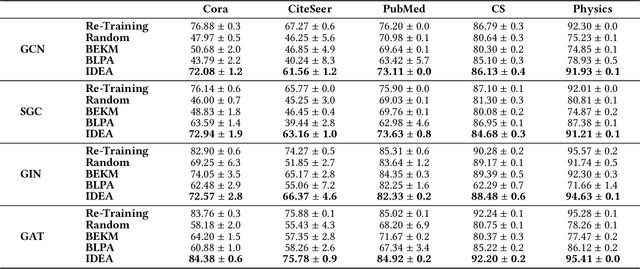
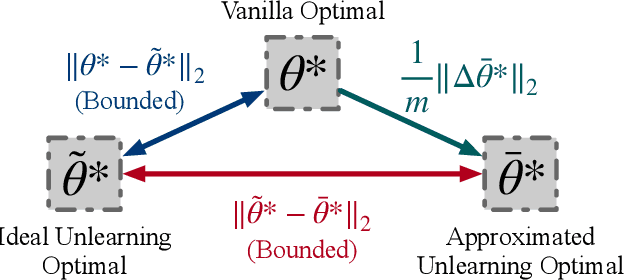
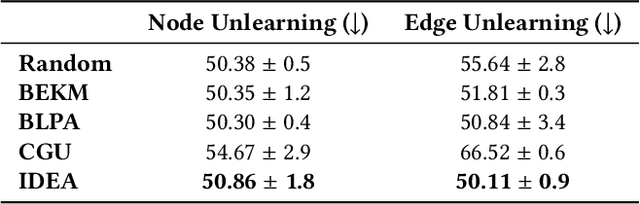
Graph Neural Networks (GNNs) have been increasingly deployed in a plethora of applications. However, the graph data used for training may contain sensitive personal information of the involved individuals. Once trained, GNNs typically encode such information in their learnable parameters. As a consequence, privacy leakage may happen when the trained GNNs are deployed and exposed to potential attackers. Facing such a threat, machine unlearning for GNNs has become an emerging technique that aims to remove certain personal information from a trained GNN. Among these techniques, certified unlearning stands out, as it provides a solid theoretical guarantee of the information removal effectiveness. Nevertheless, most of the existing certified unlearning methods for GNNs are only designed to handle node and edge unlearning requests. Meanwhile, these approaches are usually tailored for either a specific design of GNN or a specially designed training objective. These disadvantages significantly jeopardize their flexibility. In this paper, we propose a principled framework named IDEA to achieve flexible and certified unlearning for GNNs. Specifically, we first instantiate four types of unlearning requests on graphs, and then we propose an approximation approach to flexibly handle these unlearning requests over diverse GNNs. We further provide theoretical guarantee of the effectiveness for the proposed approach as a certification. Different from existing alternatives, IDEA is not designed for any specific GNNs or optimization objectives to perform certified unlearning, and thus can be easily generalized. Extensive experiments on real-world datasets demonstrate the superiority of IDEA in multiple key perspectives.
Chasing Fairness in Graphs: A GNN Architecture Perspective
Dec 19, 2023
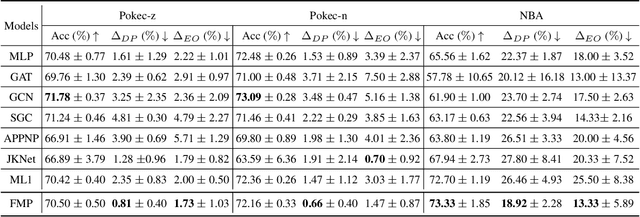
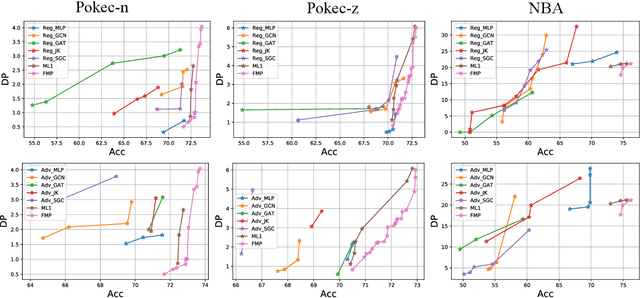

There has been significant progress in improving the performance of graph neural networks (GNNs) through enhancements in graph data, model architecture design, and training strategies. For fairness in graphs, recent studies achieve fair representations and predictions through either graph data pre-processing (e.g., node feature masking, and topology rewiring) or fair training strategies (e.g., regularization, adversarial debiasing, and fair contrastive learning). How to achieve fairness in graphs from the model architecture perspective is less explored. More importantly, GNNs exhibit worse fairness performance compared to multilayer perception since their model architecture (i.e., neighbor aggregation) amplifies biases. To this end, we aim to achieve fairness via a new GNN architecture. We propose \textsf{F}air \textsf{M}essage \textsf{P}assing (FMP) designed within a unified optimization framework for GNNs. Notably, FMP \textit{explicitly} renders sensitive attribute usage in \textit{forward propagation} for node classification task using cross-entropy loss without data pre-processing. In FMP, the aggregation is first adopted to utilize neighbors' information and then the bias mitigation step explicitly pushes demographic group node presentation centers together. In this way, FMP scheme can aggregate useful information from neighbors and mitigate bias to achieve better fairness and prediction tradeoff performance. Experiments on node classification tasks demonstrate that the proposed FMP outperforms several baselines in terms of fairness and accuracy on three real-world datasets. The code is available in {\url{https://github.com/zhimengj0326/FMP}}.