 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
Illuminating LLM Coding Agents: Visual Analytics for Deeper Understanding and Enhancement
Aug 18, 2025Coding agents powered by large language models (LLMs) have gained traction for automating code generation through iterative problem-solving with minimal human involvement. Despite the emergence of various frameworks, e.g., LangChain, AutoML, and AIDE, ML scientists still struggle to effectively review and adjust the agents' coding process. The current approach of manually inspecting individual outputs is inefficient, making it difficult to track code evolution, compare coding iterations, and identify improvement opportunities. To address this challenge, we introduce a visual analytics system designed to enhance the examination of coding agent behaviors. Focusing on the AIDE framework, our system supports comparative analysis across three levels: (1) Code-Level Analysis, which reveals how the agent debugs and refines its code over iterations; (2) Process-Level Analysis, which contrasts different solution-seeking processes explored by the agent; and (3) LLM-Level Analysis, which highlights variations in coding behavior across different LLMs. By integrating these perspectives, our system enables ML scientists to gain a structured understanding of agent behaviors, facilitating more effective debugging and prompt engineering. Through case studies using coding agents to tackle popular Kaggle competitions, we demonstrate how our system provides valuable insights into the iterative coding process.
MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation
Dec 31, 2024



Large Language Models (LLMs) are becoming essential tools for various natural language processing tasks but often suffer from generating outdated or incorrect information. Retrieval-Augmented Generation (RAG) addresses this issue by incorporating external, real-time information retrieval to ground LLM responses. However, the existing RAG systems frequently struggle with the quality of retrieval documents, as irrelevant or noisy documents degrade performance, increase computational overhead, and undermine response reliability. To tackle this problem, we propose Multi-Agent Filtering Retrieval-Augmented Generation (MAIN-RAG), a training-free RAG framework that leverages multiple LLM agents to collaboratively filter and score retrieved documents. Specifically, MAIN-RAG introduces an adaptive filtering mechanism that dynamically adjusts the relevance filtering threshold based on score distributions, effectively minimizing noise while maintaining high recall of relevant documents. The proposed approach leverages inter-agent consensus to ensure robust document selection without requiring additional training data or fine-tuning. Experimental results across four QA benchmarks demonstrate that MAIN-RAG consistently outperforms traditional RAG approaches, achieving a 2-11% improvement in answer accuracy while reducing the number of irrelevant retrieved documents. Quantitative analysis further reveals that our approach achieves superior response consistency and answer accuracy over baseline methods, offering a competitive and practical alternative to training-based solutions.
Discrete-state Continuous-time Diffusion for Graph Generation
May 19, 2024
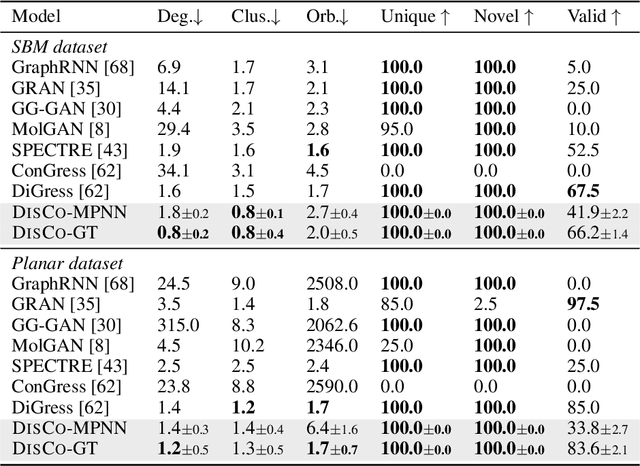

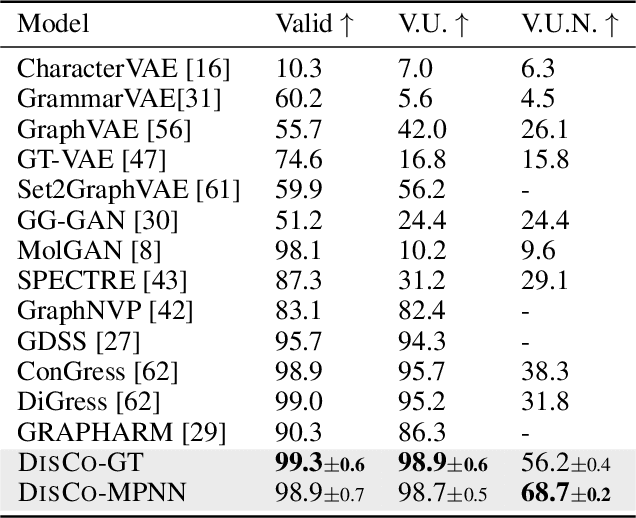
Graph is a prevalent discrete data structure, whose generation has wide applications such as drug discovery and circuit design. Diffusion generative models, as an emerging research focus, have been applied to graph generation tasks. Overall, according to the space of states and time steps, diffusion generative models can be categorized into discrete-/continuous-state discrete-/continuous-time fashions. In this paper, we formulate the graph diffusion generation in a discrete-state continuous-time setting, which has never been studied in previous graph diffusion models. The rationale of such a formulation is to preserve the discrete nature of graph-structured data and meanwhile provide flexible sampling trade-offs between sample quality and efficiency. Analysis shows that our training objective is closely related to generation quality, and our proposed generation framework enjoys ideal invariant/equivariant properties concerning the permutation of node ordering. Our proposed model shows competitive empirical performance against state-of-the-art graph generation solutions on various benchmarks and, at the same time, can flexibly trade off the generation quality and efficiency in the sampling phase.
Invariant Graph Transformer
Dec 15, 2023Rationale discovery is defined as finding a subset of the input data that maximally supports the prediction of downstream tasks. In graph machine learning context, graph rationale is defined to locate the critical subgraph in the given graph topology, which fundamentally determines the prediction results. In contrast to the rationale subgraph, the remaining subgraph is named the environment subgraph. Graph rationalization can enhance the model performance as the mapping between the graph rationale and prediction label is viewed as invariant, by assumption. To ensure the discriminative power of the extracted rationale subgraphs, a key technique named "intervention" is applied. The core idea of intervention is that given any changing environment subgraphs, the semantics from the rationale subgraph is invariant, which guarantees the correct prediction result. However, most, if not all, of the existing rationalization works on graph data develop their intervention strategies on the graph level, which is coarse-grained. In this paper, we propose well-tailored intervention strategies on graph data. Our idea is driven by the development of Transformer models, whose self-attention module provides rich interactions between input nodes. Based on the self-attention module, our proposed invariant graph Transformer (IGT) can achieve fine-grained, more specifically, node-level and virtual node-level intervention. Our comprehensive experiments involve 7 real-world datasets, and the proposed IGT shows significant performance advantages compared to 13 baseline methods.
Sketching Multidimensional Time Series for Fast Discord Mining
Nov 05, 2023



Time series discords are a useful primitive for time series anomaly detection, and the matrix profile is capable of capturing discord effectively. There exist many research efforts to improve the scalability of discord discovery with respect to the length of time series. However, there is surprisingly little work focused on reducing the time complexity of matrix profile computation associated with dimensionality of a multidimensional time series. In this work, we propose a sketch for discord mining among multi-dimensional time series. After an initial pre-processing of the sketch as fast as reading the data, the discord mining has runtime independent of the dimensionality of the original data. On several real world examples from water treatment and transportation, the proposed algorithm improves the throughput by at least an order of magnitude (50X) and only has minimal impact on the quality of the approximated solution. Additionally, the proposed method can handle the dynamic addition or deletion of dimensions inconsequential overhead. This allows a data analyst to consider "what-if" scenarios in real time while exploring the data.
Denoising Self-attentive Sequential Recommendation
Dec 08, 2022



Transformer-based sequential recommenders are very powerful for capturing both short-term and long-term sequential item dependencies. This is mainly attributed to their unique self-attention networks to exploit pairwise item-item interactions within the sequence. However, real-world item sequences are often noisy, which is particularly true for implicit feedback. For example, a large portion of clicks do not align well with user preferences, and many products end up with negative reviews or being returned. As such, the current user action only depends on a subset of items, not on the entire sequences. Many existing Transformer-based models use full attention distributions, which inevitably assign certain credits to irrelevant items. This may lead to sub-optimal performance if Transformers are not regularized properly.
Towards Generating Adversarial Examples on Mixed-type Data
Oct 17, 2022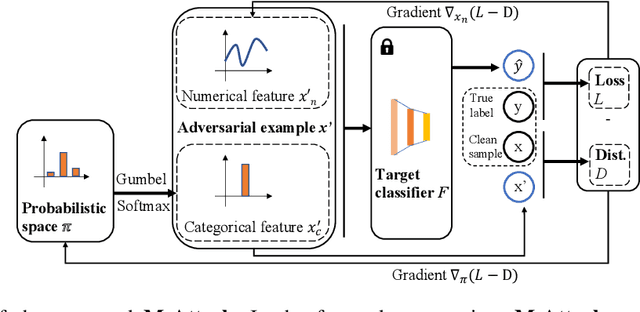
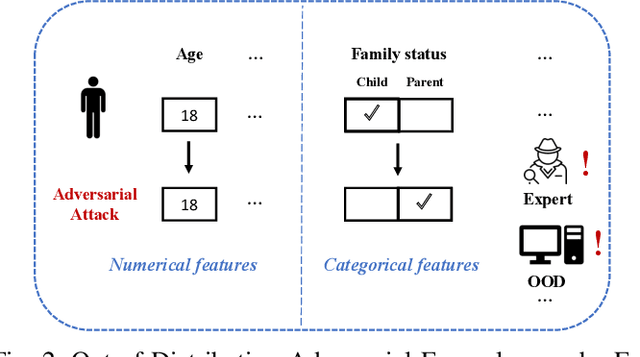
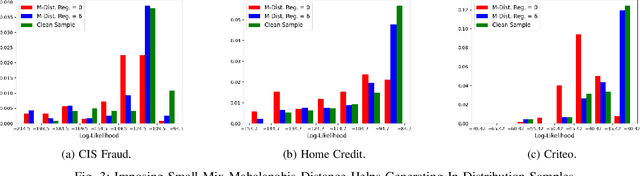
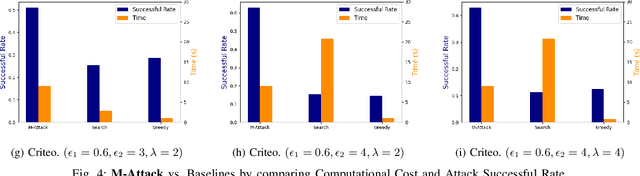
The existence of adversarial attacks (or adversarial examples) brings huge concern about the machine learning (ML) model's safety issues. For many safety-critical ML tasks, such as financial forecasting, fraudulent detection, and anomaly detection, the data samples are usually mixed-type, which contain plenty of numerical and categorical features at the same time. However, how to generate adversarial examples with mixed-type data is still seldom studied. In this paper, we propose a novel attack algorithm M-Attack, which can effectively generate adversarial examples in mixed-type data. Based on M-Attack, attackers can attempt to mislead the targeted classification model's prediction, by only slightly perturbing both the numerical and categorical features in the given data samples. More importantly, by adding designed regularizations, our generated adversarial examples can evade potential detection models, which makes the attack indeed insidious. Through extensive empirical studies, we validate the effectiveness and efficiency of our attack method and evaluate the robustness of existing classification models against our proposed attack. The experimental results highlight the feasibility of generating adversarial examples toward machine learning models in real-world applications.