 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix Profile for Anomaly Detection on Multidimensional Time Series
Sep 14, 2024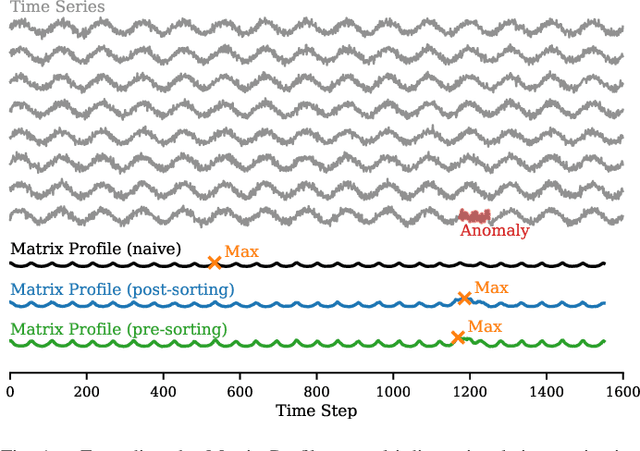
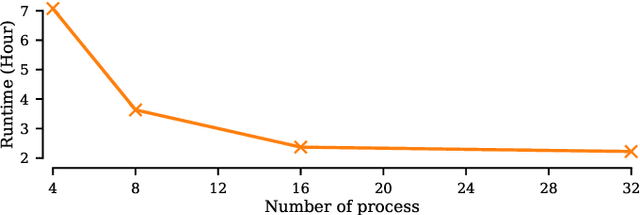
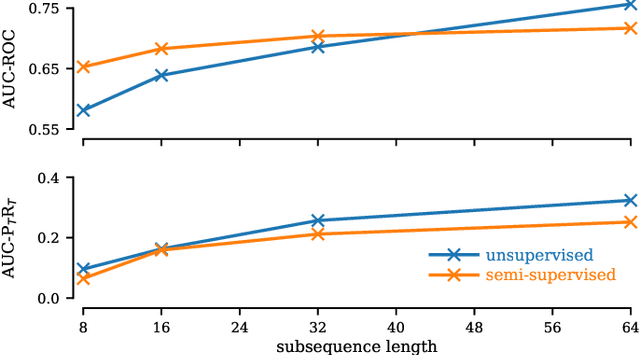
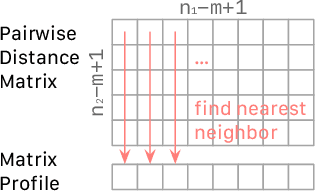
The Matrix Profile (MP), a versatile tool for time series data mining, has been shown effective in time series anomaly detection (TSAD). This paper delves into the problem of anomaly detection in multidimensional time series, a common occurrence in real-world applications. For instance, in a manufacturing factory, multiple sensors installed across the site collect time-varying data for analysis. The Matrix Profile, named for its role in profiling the matrix storing pairwise distance between subsequences of univariate time series, becomes complex in multidimensional scenarios. If the input univariate time series has n subsequences, the pairwise distance matrix is a n x n matrix. In a multidimensional time series with d dimensions, the pairwise distance information must be stored in a n x n x d tensor. In this paper, we first analyze different strategies for condensing this tensor into a profile vector. We then investigate the potential of extending the MP to efficiently find k-nearest neighbors for anomaly detection. Finally, we benchmark the multidimensional MP against 19 baseline methods on 119 multidimensional TSAD datasets. The experiments covers three learning setups: unsupervised, supervised, and semi-supervised. MP is the only method that consistently delivers high performance across all setups.
A Systematic Evaluation of Generated Time Series and Their Effects in Self-Supervised Pretraining
Aug 15, 2024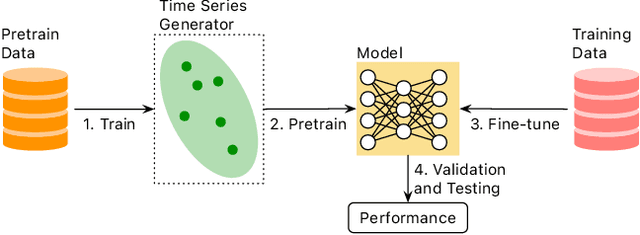



Self-supervised Pretrained Models (PTMs) have demonstrated remarkable performance in computer vision and natural language processing tasks. These successes have prompted researchers to design PTMs for time series data. In our experiments, most self-supervised time series PTMs were surpassed by simple supervised models. We hypothesize this undesired phenomenon may be caused by data scarcity. In response, we test six time series generation methods, use the generated data in pretraining in lieu of the real data, and examine the effects on classification performance. Our results indicate that replacing a real-data pretraining set with a greater volume of only generated samples produces noticeable improvement.
Sketching Multidimensional Time Series for Fast Discord Mining
Nov 05, 2023



Time series discords are a useful primitive for time series anomaly detection, and the matrix profile is capable of capturing discord effectively. There exist many research efforts to improve the scalability of discord discovery with respect to the length of time series. However, there is surprisingly little work focused on reducing the time complexity of matrix profile computation associated with dimensionality of a multidimensional time series. In this work, we propose a sketch for discord mining among multi-dimensional time series. After an initial pre-processing of the sketch as fast as reading the data, the discord mining has runtime independent of the dimensionality of the original data. On several real world examples from water treatment and transportation, the proposed algorithm improves the throughput by at least an order of magnitude (50X) and only has minimal impact on the quality of the approximated solution. Additionally, the proposed method can handle the dynamic addition or deletion of dimensions inconsequential overhead. This allows a data analyst to consider "what-if" scenarios in real time while exploring the data.
Ego-Network Transformer for Subsequence Classification in Time Series Data
Nov 05, 2023


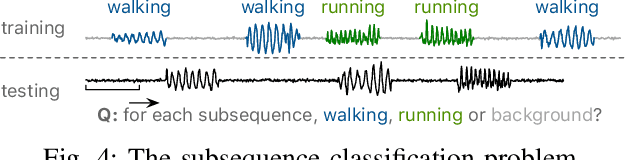
Time series classification is a widely studied problem in the field of time series data mining. Previous research has predominantly focused on scenarios where relevant or foreground subsequences have already been extracted, with each subsequence corresponding to a single label. However, real-world time series data often contain foreground subsequences that are intertwined with background subsequences. Successfully classifying these relevant subsequences requires not only distinguishing between different classes but also accurately identifying the foreground subsequences amidst the background. To address this challenge, we propose a novel subsequence classification method that represents each subsequence as an ego-network, providing crucial nearest neighbor information to the model. The ego-networks of all subsequences collectively form a time series subsequence graph, and we introduce an algorithm to efficiently construct this graph. Furthermore, we have demonstrated the significance of enforcing temporal consistency in the prediction of adjacent subsequences for the subsequence classification problem. To evaluate the effectiveness of our approach, we conducted experiments using 128 univariate and 30 multivariate time series datasets. The experimental results demonstrate the superior performance of our method compared to alternative approaches. Specifically, our method outperforms the baseline on 104 out of 158 datasets.
Time Series Synthesis Using the Matrix Profile for Anonymization
Nov 05, 2023



Publishing and sharing data is crucial for the data mining community, allowing collaboration and driving open innovation. However, many researchers cannot release their data due to privacy regulations or fear of leaking confidential business information. To alleviate such issues, we propose the Time Series Synthesis Using the Matrix Profile (TSSUMP) method, where synthesized time series can be released in lieu of the original data. The TSSUMP method synthesizes time series by preserving similarity join information (i.e., Matrix Profile) while reducing the correlation between the synthesized and the original time series. As a result, neither the values for the individual time steps nor the local patterns (or shapes) from the original data can be recovered, yet the resulting data can be used for downstream tasks that data analysts are interested in. We concentrate on similarity joins because they are one of the most widely applied time series data mining routines across different data mining tasks. We test our method on a case study of ECG and gender masking prediction. In this case study, the gender information is not only removed from the synthesized time series, but the synthesized time series also preserves enough information from the original time series. As a result, unmodified data mining tools can obtain near-identical performance on the synthesized time series as on the original time series.
Matrix Profile XXVII: A Novel Distance Measure for Comparing Long Time Series
Dec 09, 2022



The most useful data mining primitives are distance measures. With an effective distance measure, it is possible to perform classification, clustering, anomaly detection, segmentation, etc. For single-event time series Euclidean Distance and Dynamic Time Warping distance are known to be extremely effective. However, for time series containing cyclical behaviors, the semantic meaningfulness of such comparisons is less clear. For example, on two separate days the telemetry from an athlete workout routine might be very similar. The second day may change the order in of performing push-ups and squats, adding repetitions of pull-ups, or completely omitting dumbbell curls. Any of these minor changes would defeat existing time series distance measures. Some bag-of-features methods have been proposed to address this problem, but we argue that in many cases, similarity is intimately tied to the shapes of subsequences within these longer time series. In such cases, summative features will lack discrimination ability. In this work we introduce PRCIS, which stands for Pattern Representation Comparison in Series. PRCIS is a distance measure for long time series, which exploits recent progress in our ability to summarize time series with dictionaries. We will demonstrate the utility of our ideas on diverse tasks and datasets.
Error-bounded Approximate Time Series Joins using Compact Dictionary Representations of Time Series
Dec 24, 2021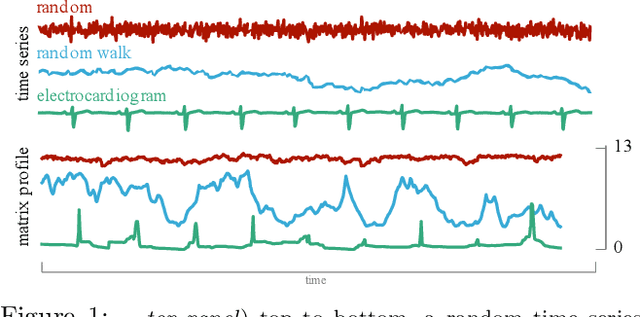
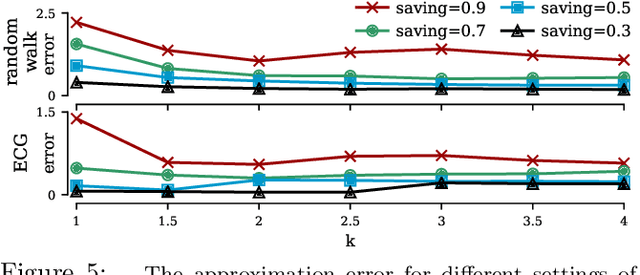
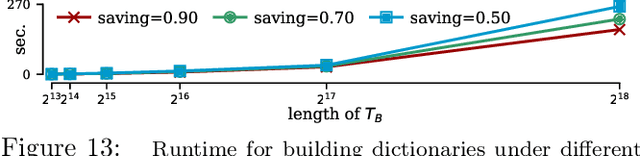

The matrix profile is an effective data mining tool that provides similarity join functionality for time series data. Users of the matrix profile can either join a time series with itself using intra-similarity join (i.e., self-join) or join a time series with another time series using inter-similarity join. By invoking either or both types of joins, the matrix profile can help users discover both conserved and anomalous structures in the data. Since the introduction of the matrix profile five years ago, multiple efforts have been made to speed up the computation with approximate joins; however, the majority of these efforts only focus on self-joins. In this work, we show that it is possible to efficiently perform approximate inter-time series similarity joins with error bounded guarantees by creating a compact "dictionary" representation of time series. Using the dictionary representation instead of the original time series, we are able to improve the throughput of an anomaly mining system by at least 20X, with essentially no decrease in accuracy. As a side effect, the dictionaries also summarize the time series in a semantically meaningful way and can provide intuitive and actionable insights. We demonstrate the utility of our dictionary-based inter-time series similarity joins on domains as diverse as medicine and transportation.
Matrix Profile XXII: Exact Discovery of Time Series Motifs under DTW
Sep 16, 2020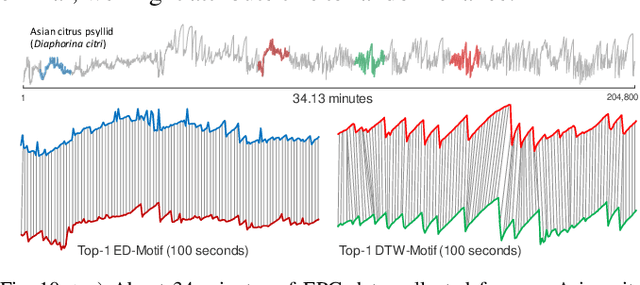
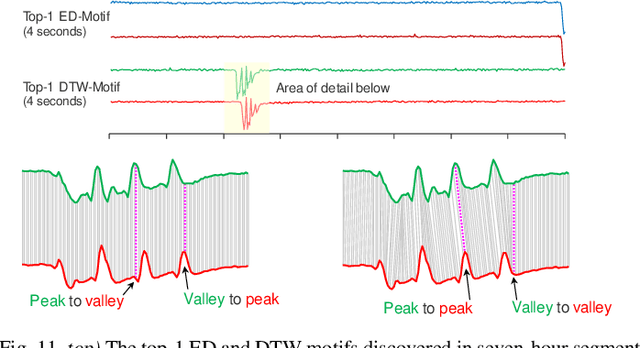
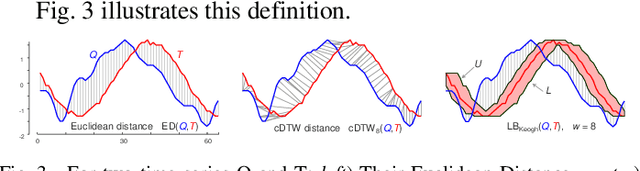
Over the last decade, time series motif discovery has emerged as a useful primitive for many downstream analytical tasks, including clustering, classification, rule discovery, segmentation, and summarization. In parallel, there has been an increased understanding that Dynamic Time Warping (DTW) is the best time series similarity measure in a host of settings. Surprisingly however, there has been virtually no work on using DTW to discover motifs. The most obvious explanation of this is the fact that both motif discovery and the use of DTW can be computationally challenging, and the current best mechanisms to address their lethargy are mutually incompatible. In this work, we present the first scalable exact method to discover time series motifs under DTW. Our method automatically performs the best trade-off between time-to-compute and tightness-of-lower-bounds for a novel hierarchy of lower bounds representation we introduce. We show that under realistic settings, our algorithm can admissibly prune up to 99.99% of the DTW computations.
Features or Shape? Tackling the False Dichotomy of Time Series Classification
Dec 20, 2019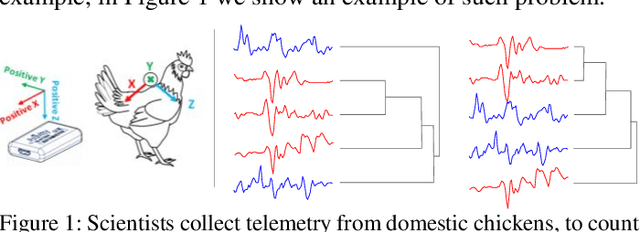
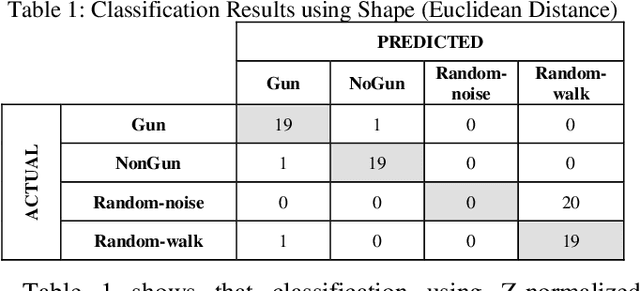
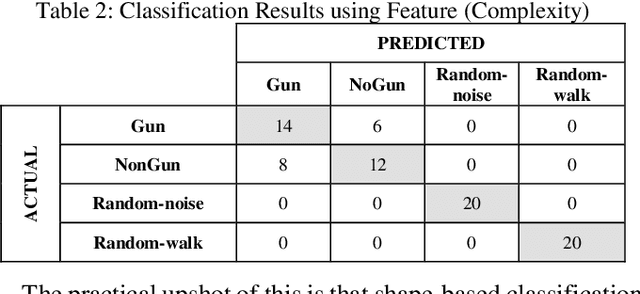
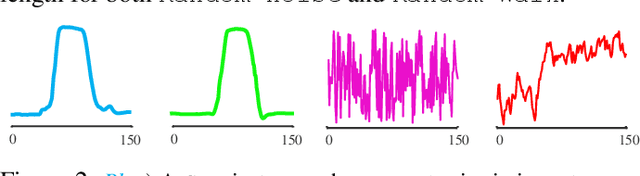
Time series classification is an important task in its own right, and it is often a precursor to further downstream analytics. To date, virtually all works in the literature have used either shape-based classification using a distance measure or feature-based classification after finding some suitable features for the domain. It seems to be underappreciated that in many datasets it is the case that some classes are best discriminated with features, while others are best discriminated with shape. Thus, making the shape vs. feature choice will condemn us to poor results, at least for some classes. In this work, we propose a new model for classifying time series that allows the use of both shape and feature-based measures, when warranted. Our algorithm automatically decides which approach is best for which class, and at query time chooses which classifier to trust the most. We evaluate our idea on real world datasets and demonstrate that our ideas produce statistically significant improvement in classification accuracy.
Time series classification for varying length series
Oct 10, 2019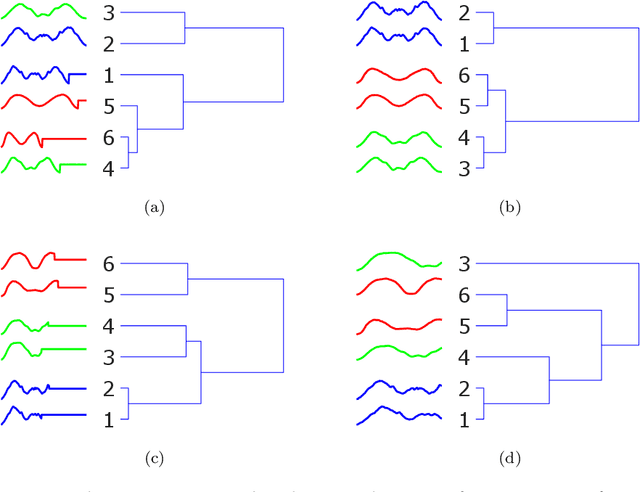
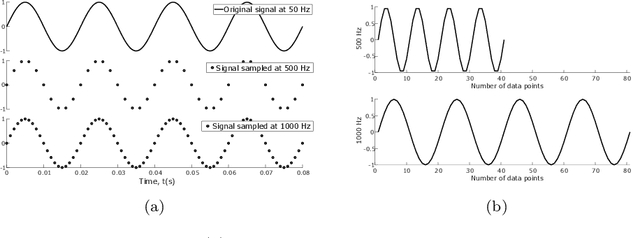
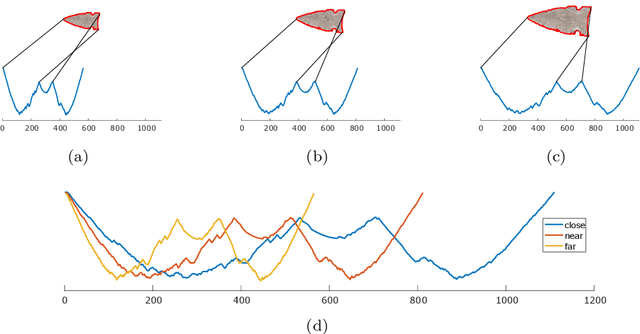
Research into time series classification has tended to focus on the case of series of uniform length. However, it is common for real-world time series data to have unequal lengths. Differing time series lengths may arise from a number of fundamentally different mechanisms. In this work, we identify and evaluate two classes of such mechanisms -- variations in sampling rate relative to the relevant signal and variations between the start and end points of one time series relative to one another. We investigate how time series generated by each of these classes of mechanism are best addressed for time series classification. We perform extensive experiments and provide practical recommendations on how variations in length should be handled in time series classification.