 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeatures or Shape? Tackling the False Dichotomy of Time Series Classification
Paper and Code
Dec 20, 2019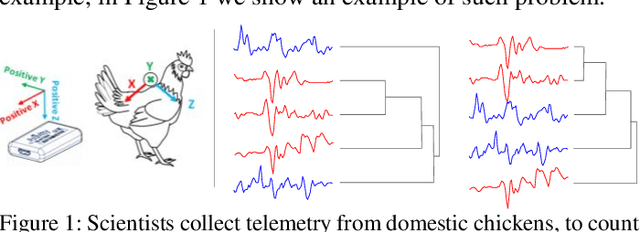
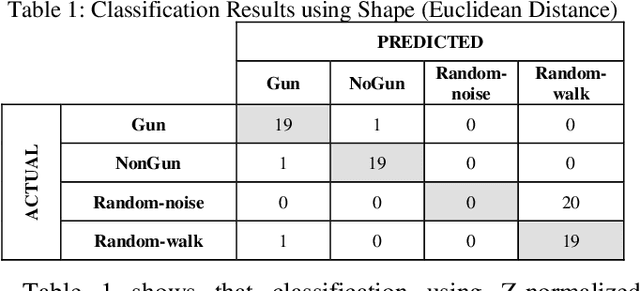
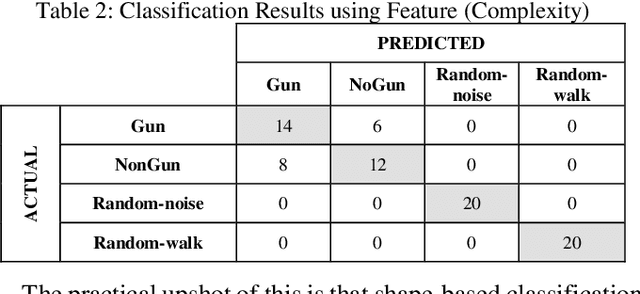
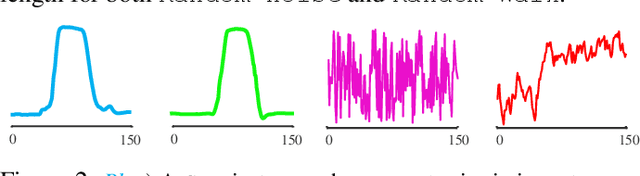
Time series classification is an important task in its own right, and it is often a precursor to further downstream analytics. To date, virtually all works in the literature have used either shape-based classification using a distance measure or feature-based classification after finding some suitable features for the domain. It seems to be underappreciated that in many datasets it is the case that some classes are best discriminated with features, while others are best discriminated with shape. Thus, making the shape vs. feature choice will condemn us to poor results, at least for some classes. In this work, we propose a new model for classifying time series that allows the use of both shape and feature-based measures, when warranted. Our algorithm automatically decides which approach is best for which class, and at query time chooses which classifier to trust the most. We evaluate our idea on real world datasets and demonstrate that our ideas produce statistically significant improvement in classification accuracy.