 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Transformer Encoders for Mask2Former-style models
Apr 23, 2024



Vision transformer based models bring significant improvements for image segmentation tasks. Although these architectures offer powerful capabilities irrespective of specific segmentation tasks, their use of computational resources can be taxing on deployed devices. One way to overcome this challenge is by adapting the computation level to the specific needs of the input image rather than the current one-size-fits-all approach. To this end, we introduce ECO-M2F or EffiCient TransfOrmer Encoders for Mask2Former-style models. Noting that the encoder module of M2F-style models incur high resource-intensive computations, ECO-M2F provides a strategy to self-select the number of hidden layers in the encoder, conditioned on the input image. To enable this self-selection ability for providing a balance between performance and computational efficiency, we present a three step recipe. The first step is to train the parent architecture to enable early exiting from the encoder. The second step is to create an derived dataset of the ideal number of encoder layers required for each training example. The third step is to use the aforementioned derived dataset to train a gating network that predicts the number of encoder layers to be used, conditioned on the input image. Additionally, to change the computational-accuracy tradeoff, only steps two and three need to be repeated which significantly reduces retraining time. Experiments on the public datasets show that the proposed approach reduces expected encoder computational cost while maintaining performance, adapts to various user compute resources, is flexible in architecture configurations, and can be extended beyond the segmentation task to object detection.
Features or Shape? Tackling the False Dichotomy of Time Series Classification
Dec 20, 2019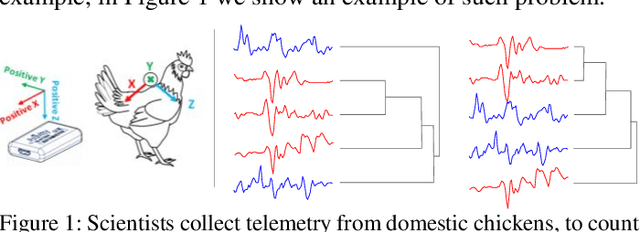
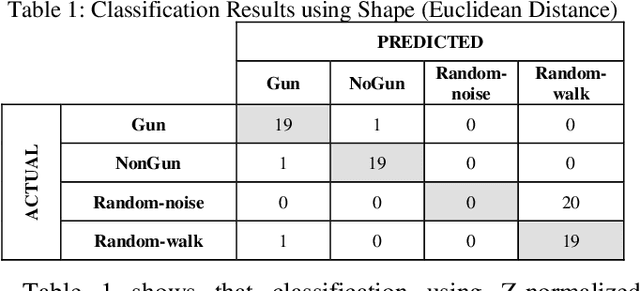
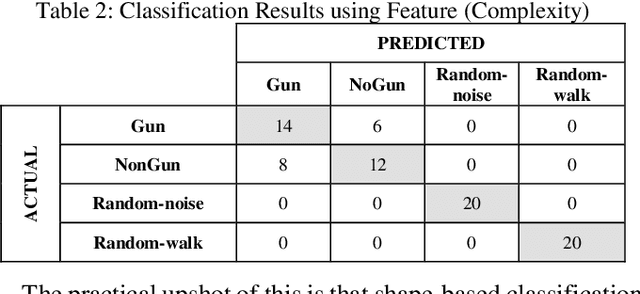
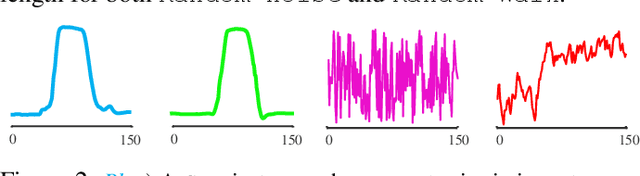
Time series classification is an important task in its own right, and it is often a precursor to further downstream analytics. To date, virtually all works in the literature have used either shape-based classification using a distance measure or feature-based classification after finding some suitable features for the domain. It seems to be underappreciated that in many datasets it is the case that some classes are best discriminated with features, while others are best discriminated with shape. Thus, making the shape vs. feature choice will condemn us to poor results, at least for some classes. In this work, we propose a new model for classifying time series that allows the use of both shape and feature-based measures, when warranted. Our algorithm automatically decides which approach is best for which class, and at query time chooses which classifier to trust the most. We evaluate our idea on real world datasets and demonstrate that our ideas produce statistically significant improvement in classification accuracy.