 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkin-R1: Toward Trustworthy Clinical Reasoning for Dermatological Diagnosis
Nov 18, 2025The emergence of vision-language models (VLMs) has opened new possibilities for clinical reasoning and has shown promising performance in dermatological diagnosis. However, their trustworthiness and clinical utility are often limited by three major factors: (1) Data heterogeneity, where diverse datasets lack consistent diagnostic labels and clinical concept annotations; (2) Absence of grounded diagnostic rationales, leading to a scarcity of reliable reasoning supervision; and (3) Limited scalability and generalization, as models trained on small, densely annotated datasets struggle to transfer nuanced reasoning to large, sparsely-annotated ones. To address these limitations, we propose SkinR1, a novel dermatological VLM that combines deep, textbook-based reasoning with the broad generalization capabilities of reinforcement learning (RL). SkinR1 systematically resolves the key challenges through a unified, end-to-end framework. First, we design a textbook-based reasoning generator that synthesizes high-fidelity, hierarchy-aware, and differential-diagnosis (DDx)-informed trajectories, providing reliable expert-level supervision. Second, we leverage the constructed trajectories for supervised fine-tuning (SFT) empowering the model with grounded reasoning ability. Third, we develop a novel RL paradigm that, by incorporating the hierarchical structure of diseases, effectively transfers these grounded reasoning patterns to large-scale, sparse data. Extensive experiments on multiple dermatology datasets demonstrate that SkinR1 achieves superior diagnostic accuracy. The ablation study demonstrates the importance of the reasoning foundation instilled by SFT.
TransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
THeGCN: Temporal Heterophilic Graph Convolutional Network
Dec 21, 2024Graph Neural Networks (GNNs) have exhibited remarkable efficacy in diverse graph learning tasks, particularly on static homophilic graphs. Recent attention has pivoted towards more intricate structures, encompassing (1) static heterophilic graphs encountering the edge heterophily issue in the spatial domain and (2) event-based continuous graphs in the temporal domain. State-of-the-art (SOTA) has been concurrently addressing these two lines of work but tends to overlook the presence of heterophily in the temporal domain, constituting the temporal heterophily issue. Furthermore, we highlight that the edge heterophily issue and the temporal heterophily issue often co-exist in event-based continuous graphs, giving rise to the temporal edge heterophily challenge. To tackle this challenge, this paper first introduces the temporal edge heterophily measurement. Subsequently, we propose the Temporal Heterophilic Graph Convolutional Network (THeGCN), an innovative model that incorporates the low/high-pass graph signal filtering technique to accurately capture both edge (spatial) heterophily and temporal heterophily. Specifically, the THeGCN model consists of two key components: a sampler and an aggregator. The sampler selects events relevant to a node at a given moment. Then, the aggregator executes message-passing, encoding temporal information, node attributes, and edge attributes into node embeddings. Extensive experiments conducted on 5 real-world datasets validate the efficacy of THeGCN.
GAIM: Attacking Graph Neural Networks via Adversarial Influence Maximization
Aug 20, 2024Recent studies show that well-devised perturbations on graph structures or node features can mislead trained Graph Neural Network (GNN) models. However, these methods often overlook practical assumptions, over-rely on heuristics, or separate vital attack components. In response, we present GAIM, an integrated adversarial attack method conducted on a node feature basis while considering the strict black-box setting. Specifically, we define an adversarial influence function to theoretically assess the adversarial impact of node perturbations, thereby reframing the GNN attack problem into the adversarial influence maximization problem. In our approach, we unify the selection of the target node and the construction of feature perturbations into a single optimization problem, ensuring a unique and consistent feature perturbation for each target node. We leverage a surrogate model to transform this problem into a solvable linear programming task, streamlining the optimization process. Moreover, we extend our method to accommodate label-oriented attacks, broadening its applicability. Thorough evaluations on five benchmark datasets across three popular models underscore the effectiveness of our method in both untargeted and label-oriented targeted attacks. Through comprehensive analysis and ablation studies, we demonstrate the practical value and efficacy inherent to our design choices.
Interpreting Graph Neural Networks with In-Distributed Proxies
Feb 03, 2024
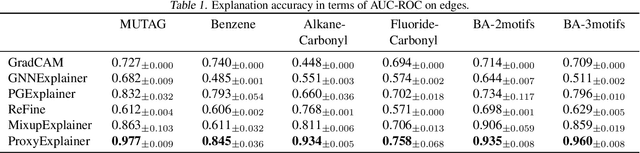
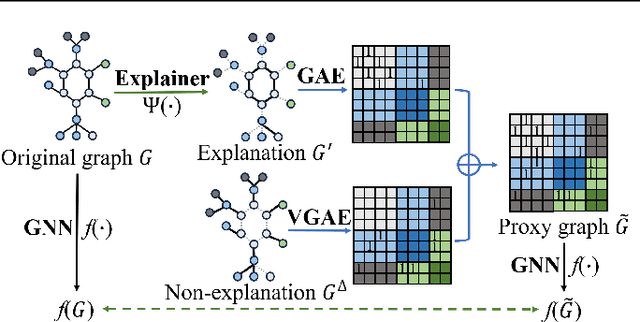

Graph Neural Networks (GNNs) have become a building block in graph data processing, with wide applications in critical domains. The growing needs to deploy GNNs in high-stakes applications necessitate explainability for users in the decision-making processes. A popular paradigm for the explainability of GNNs is to identify explainable subgraphs by comparing their labels with the ones of original graphs. This task is challenging due to the substantial distributional shift from the original graphs in the training set to the set of explainable subgraphs, which prevents accurate prediction of labels with the subgraphs. To address it, in this paper, we propose a novel method that generates proxy graphs for explainable subgraphs that are in the distribution of training data. We introduce a parametric method that employs graph generators to produce proxy graphs. A new training objective based on information theory is designed to ensure that proxy graphs not only adhere to the distribution of training data but also preserve essential explanatory factors. Such generated proxy graphs can be reliably used for approximating the predictions of the true labels of explainable subgraphs. Empirical evaluations across various datasets demonstrate our method achieves more accurate explanations for GNNs.
Adversarial Collaborative Filtering for Free
Aug 20, 2023



Collaborative Filtering (CF) has been successfully used to help users discover the items of interest. Nevertheless, existing CF methods suffer from noisy data issue, which negatively impacts the quality of recommendation. To tackle this problem, many prior studies leverage adversarial learning to regularize the representations of users/items, which improves both generalizability and robustness. Those methods often learn adversarial perturbations and model parameters under min-max optimization framework. However, there still have two major drawbacks: 1) Existing methods lack theoretical guarantees of why adding perturbations improve the model generalizability and robustness; 2) Solving min-max optimization is time-consuming. In addition to updating the model parameters, each iteration requires additional computations to update the perturbations, making them not scalable for industry-scale datasets. In this paper, we present Sharpness-aware Collaborative Filtering (SharpCF), a simple yet effective method that conducts adversarial training without extra computational cost over the base optimizer. To achieve this goal, we first revisit the existing adversarial collaborative filtering and discuss its connection with recent Sharpness-aware Minimization. This analysis shows that adversarial training actually seeks model parameters that lie in neighborhoods around the optimal model parameters having uniformly low loss values, resulting in better generalizability. To reduce the computational overhead, SharpCF introduces a novel trajectory loss to measure the alignment between current weights and past weights. Experimental results on real-world datasets demonstrate that our SharpCF achieves superior performance with almost zero additional computational cost comparing to adversarial training.
Adversary for Social Good: Leveraging Adversarial Attacks to Protect Personal Attribute Privacy
Jun 04, 2023



Social media has drastically reshaped the world that allows billions of people to engage in such interactive environments to conveniently create and share content with the public. Among them, text data (e.g., tweets, blogs) maintains the basic yet important social activities and generates a rich source of user-oriented information. While those explicit sensitive user data like credentials has been significantly protected by all means, personal private attribute (e.g., age, gender, location) disclosure due to inference attacks is somehow challenging to avoid, especially when powerful natural language processing (NLP) techniques have been effectively deployed to automate attribute inferences from implicit text data. This puts users' attribute privacy at risk. To address this challenge, in this paper, we leverage the inherent vulnerability of machine learning to adversarial attacks, and design a novel text-space Adversarial attack for Social Good, called Adv4SG. In other words, we cast the problem of protecting personal attribute privacy as an adversarial attack formulation problem over the social media text data to defend against NLP-based attribute inference attacks. More specifically, Adv4SG proceeds with a sequence of word perturbations under given constraints such that the probed attribute cannot be identified correctly. Different from the prior works, we advance Adv4SG by considering social media property, and introducing cost-effective mechanisms to expedite attribute obfuscation over text data under the black-box setting. Extensive experiments on real-world social media datasets have demonstrated that our method can effectively degrade the inference accuracy with less computational cost over different attribute settings, which substantially helps mitigate the impacts of inference attacks and thus achieve high performance in user attribute privacy protection.
TinyKG: Memory-Efficient Training Framework for Knowledge Graph Neural Recommender Systems
Dec 08, 2022



There has been an explosion of interest in designing various Knowledge Graph Neural Networks (KGNNs), which achieve state-of-the-art performance and provide great explainability for recommendation. The promising performance is mainly resulting from their capability of capturing high-order proximity messages over the knowledge graphs. However, training KGNNs at scale is challenging due to the high memory usage. In the forward pass, the automatic differentiation engines (\textsl{e.g.}, TensorFlow/PyTorch) generally need to cache all intermediate activation maps in order to compute gradients in the backward pass, which leads to a large GPU memory footprint. Existing work solves this problem by utilizing multi-GPU distributed frameworks. Nonetheless, this poses a practical challenge when seeking to deploy KGNNs in memory-constrained environments, especially for industry-scale graphs. Here we present TinyKG, a memory-efficient GPU-based training framework for KGNNs for the tasks of recommendation. Specifically, TinyKG uses exact activations in the forward pass while storing a quantized version of activations in the GPU buffers. During the backward pass, these low-precision activations are dequantized back to full-precision tensors, in order to compute gradients. To reduce the quantization errors, TinyKG applies a simple yet effective quantization algorithm to compress the activations, which ensures unbiasedness with low variance. As such, the training memory footprint of KGNNs is largely reduced with negligible accuracy loss. To evaluate the performance of our TinyKG, we conduct comprehensive experiments on real-world datasets. We found that our TinyKG with INT2 quantization aggressively reduces the memory footprint of activation maps with $7 \times$, only with $2\%$ loss in accuracy, allowing us to deploy KGNNs on memory-constrained devices.
Denoising Self-attentive Sequential Recommendation
Dec 08, 2022



Transformer-based sequential recommenders are very powerful for capturing both short-term and long-term sequential item dependencies. This is mainly attributed to their unique self-attention networks to exploit pairwise item-item interactions within the sequence. However, real-world item sequences are often noisy, which is particularly true for implicit feedback. For example, a large portion of clicks do not align well with user preferences, and many products end up with negative reviews or being returned. As such, the current user action only depends on a subset of items, not on the entire sequences. Many existing Transformer-based models use full attention distributions, which inevitably assign certain credits to irrelevant items. This may lead to sub-optimal performance if Transformers are not regularized properly.
SMARTQUERY: An Active Learning Framework for Graph Neural Networks through Hybrid Uncertainty Reduction
Dec 02, 2022



Graph neural networks have achieved significant success in representation learning. However, the performance gains come at a cost; acquiring comprehensive labeled data for training can be prohibitively expensive. Active learning mitigates this issue by searching the unexplored data space and prioritizing the selection of data to maximize model's performance gain. In this paper, we propose a novel method SMARTQUERY, a framework to learn a graph neural network with very few labeled nodes using a hybrid uncertainty reduction function. This is achieved using two key steps: (a) design a multi-stage active graph learning framework by exploiting diverse explicit graph information and (b) introduce label propagation to efficiently exploit known labels to assess the implicit embedding information. Using a comprehensive set of experiments on three network datasets, we demonstrate the competitive performance of our method against state-of-the-arts on very few labeled data (up to 5 labeled nodes per class).