 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime Series Reasoning via Process-Verifiable Thinking Data Synthesis and Scheduling for Tailored LLM Reasoning
Feb 08, 2026Time series is a pervasive data type across various application domains, rendering the reasonable solving of diverse time series tasks a long-standing goal. Recent advances in large language models (LLMs), especially their reasoning abilities unlocked through reinforcement learning (RL), have opened new opportunities for tackling tasks with long Chain-of-Thought (CoT) reasoning. However, leveraging LLM reasoning for time series remains in its infancy, hindered by the absence of carefully curated time series CoT data for training, limited data efficiency caused by underexplored data scheduling, and the lack of RL algorithms tailored for exploiting such time series CoT data. In this paper, we introduce VeriTime, a framework that tailors LLMs for time series reasoning through data synthesis, data scheduling, and RL training. First, we propose a data synthesis pipeline that constructs a TS-text multimodal dataset with process-verifiable annotations. Second, we design a data scheduling mechanism that arranges training samples according to a principled hierarchy of difficulty and task taxonomy. Third, we develop a two-stage reinforcement finetuning featuring fine-grained, multi-objective rewards that leverage verifiable process-level CoT data. Extensive experiments show that VeriTime substantially boosts LLM performance across diverse time series reasoning tasks. Notably, it enables compact 3B, 4B models to achieve reasoning capabilities on par with or exceeding those of larger proprietary LLMs.
LM$^2$otifs : An Explainable Framework for Machine-Generated Texts Detection
May 18, 2025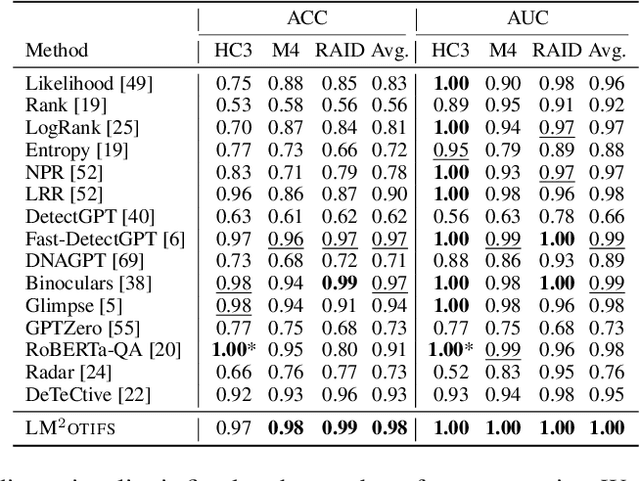
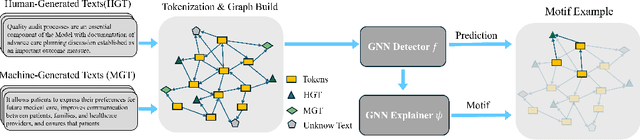
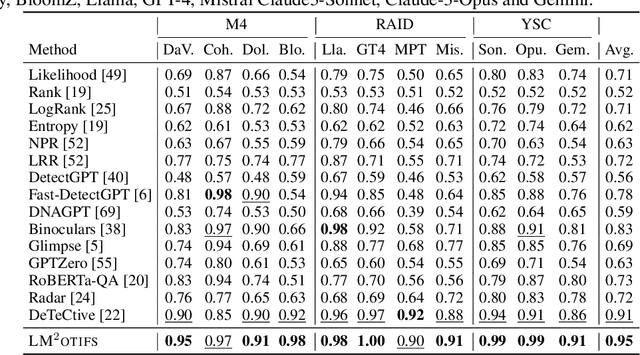
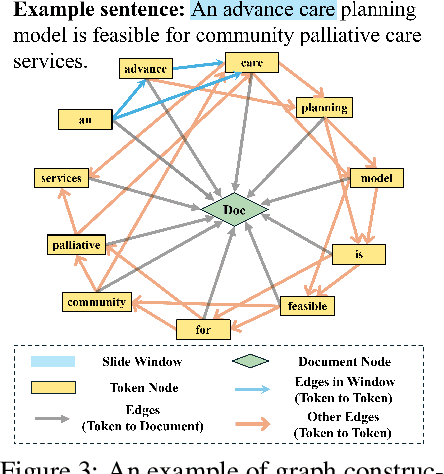
The impressive ability of large language models to generate natural text across various tasks has led to critical challenges in authorship authentication. Although numerous detection methods have been developed to differentiate between machine-generated texts (MGT) and human-generated texts (HGT), the explainability of these methods remains a significant gap. Traditional explainability techniques often fall short in capturing the complex word relationships that distinguish HGT from MGT. To address this limitation, we present LM$^2$otifs, a novel explainable framework for MGT detection. Inspired by probabilistic graphical models, we provide a theoretical rationale for the effectiveness. LM$^2$otifs utilizes eXplainable Graph Neural Networks to achieve both accurate detection and interpretability. The LM$^2$otifs pipeline operates in three key stages: first, it transforms text into graphs based on word co-occurrence to represent lexical dependencies; second, graph neural networks are used for prediction; and third, a post-hoc explainability method extracts interpretable motifs, offering multi-level explanations from individual words to sentence structures. Extensive experiments on multiple benchmark datasets demonstrate the comparable performance of LM$^2$otifs. The empirical evaluation of the extracted explainable motifs confirms their effectiveness in differentiating HGT and MGT. Furthermore, qualitative analysis reveals distinct and visible linguistic fingerprints characteristic of MGT.
Explanation-Preserving Augmentation for Semi-Supervised Graph Representation Learning
Oct 16, 2024



Graph representation learning (GRL), enhanced by graph augmentation methods, has emerged as an effective technique achieving performance improvements in wide tasks such as node classification and graph classification. In self-supervised GRL, paired graph augmentations are generated from each graph. Its objective is to infer similar representations for augmentations of the same graph, but maximally distinguishable representations for augmentations of different graphs. Analogous to image and language domains, the desiderata of an ideal augmentation method include both (1) semantics-preservation; and (2) data-perturbation; i.e., an augmented graph should preserve the semantics of its original graph while carrying sufficient variance. However, most existing (un-)/self-supervised GRL methods focus on data perturbation but largely neglect semantics preservation. To address this challenge, in this paper, we propose a novel method, Explanation-Preserving Augmentation (EPA), that leverages graph explanation techniques for generating augmented graphs that can bridge the gap between semantics-preservation and data-perturbation. EPA first uses a small number of labels to train a graph explainer to infer the sub-structures (explanations) that are most relevant to a graph's semantics. These explanations are then used to generate semantics-preserving augmentations for self-supervised GRL, namely EPA-GRL. We demonstrate theoretically, using an analytical example, and through extensive experiments on a variety of benchmark datasets that EPA-GRL outperforms the state-of-the-art (SOTA) GRL methods, which are built upon semantics-agnostic data augmentations.
F-Fidelity: A Robust Framework for Faithfulness Evaluation of Explainable AI
Oct 03, 2024



Recent research has developed a number of eXplainable AI (XAI) techniques. Although extracting meaningful insights from deep learning models, how to properly evaluate these XAI methods remains an open problem. The most widely used approach is to perturb or even remove what the XAI method considers to be the most important features in an input and observe the changes in the output prediction. This approach although efficient suffers the Out-of-Distribution (OOD) problem as the perturbed samples may no longer follow the original data distribution. A recent method RemOve And Retrain (ROAR) solves the OOD issue by retraining the model with perturbed samples guided by explanations. However, the training may not always converge given the distribution difference. Furthermore, using the model retrained based on XAI methods to evaluate these explainers may cause information leakage and thus lead to unfair comparisons. We propose Fine-tuned Fidelity F-Fidelity, a robust evaluation framework for XAI, which utilizes i) an explanation-agnostic fine-tuning strategy, thus mitigating the information leakage issue and ii) a random masking operation that ensures that the removal step does not generate an OOD input. We designed controlled experiments with state-of-the-art (SOTA) explainers and their degraded version to verify the correctness of our framework. We conducted experiments on multiple data structures, such as images, time series, and natural language. The results demonstrate that F-Fidelity significantly improves upon prior evaluation metrics in recovering the ground-truth ranking of the explainers. Furthermore, we show both theoretically and empirically that, given a faithful explainer, F-Fidelity metric can be used to compute the sparsity of influential input components, i.e., to extract the true explanation size.
TimeX++: Learning Time-Series Explanations with Information Bottleneck
May 15, 2024Explaining deep learning models operating on time series data is crucial in various applications of interest which require interpretable and transparent insights from time series signals. In this work, we investigate this problem from an information theoretic perspective and show that most existing measures of explainability may suffer from trivial solutions and distributional shift issues. To address these issues, we introduce a simple yet practical objective function for time series explainable learning. The design of the objective function builds upon the principle of information bottleneck (IB), and modifies the IB objective function to avoid trivial solutions and distributional shift issues. We further present TimeX++, a novel explanation framework that leverages a parametric network to produce explanation-embedded instances that are both in-distributed and label-preserving. We evaluate TimeX++ on both synthetic and real-world datasets comparing its performance against leading baselines, and validate its practical efficacy through case studies in a real-world environmental application. Quantitative and qualitative evaluations show that TimeX++ outperforms baselines across all datasets, demonstrating a substantial improvement in explanation quality for time series data. The source code is available at \url{https://github.com/zichuan-liu/TimeXplusplus}.
Interpreting Graph Neural Networks with In-Distributed Proxies
Feb 03, 2024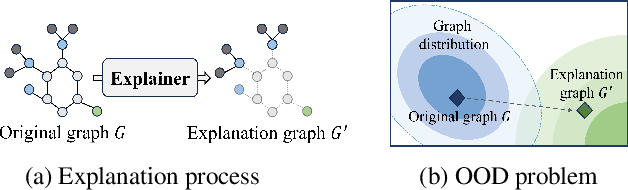
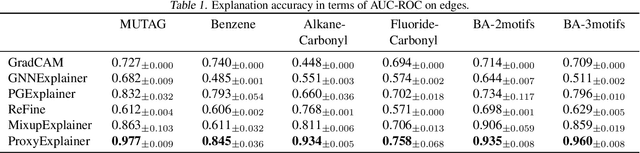
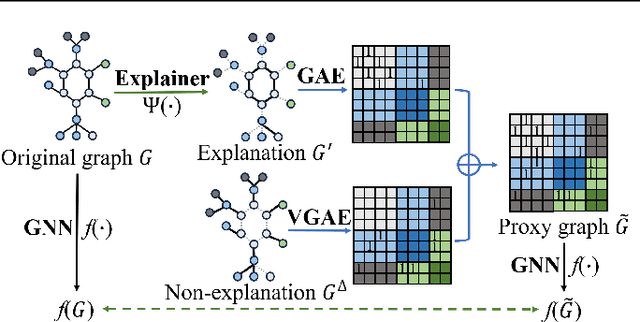

Graph Neural Networks (GNNs) have become a building block in graph data processing, with wide applications in critical domains. The growing needs to deploy GNNs in high-stakes applications necessitate explainability for users in the decision-making processes. A popular paradigm for the explainability of GNNs is to identify explainable subgraphs by comparing their labels with the ones of original graphs. This task is challenging due to the substantial distributional shift from the original graphs in the training set to the set of explainable subgraphs, which prevents accurate prediction of labels with the subgraphs. To address it, in this paper, we propose a novel method that generates proxy graphs for explainable subgraphs that are in the distribution of training data. We introduce a parametric method that employs graph generators to produce proxy graphs. A new training objective based on information theory is designed to ensure that proxy graphs not only adhere to the distribution of training data but also preserve essential explanatory factors. Such generated proxy graphs can be reliably used for approximating the predictions of the true labels of explainable subgraphs. Empirical evaluations across various datasets demonstrate our method achieves more accurate explanations for GNNs.
Towards Robust Fidelity for Evaluating Explainability of Graph Neural Networks
Oct 03, 2023Graph Neural Networks (GNNs) are neural models that leverage the dependency structure in graphical data via message passing among the graph nodes. GNNs have emerged as pivotal architectures in analyzing graph-structured data, and their expansive application in sensitive domains requires a comprehensive understanding of their decision-making processes -- necessitating a framework for GNN explainability. An explanation function for GNNs takes a pre-trained GNN along with a graph as input, to produce a `sufficient statistic' subgraph with respect to the graph label. A main challenge in studying GNN explainability is to provide fidelity measures that evaluate the performance of these explanation functions. This paper studies this foundational challenge, spotlighting the inherent limitations of prevailing fidelity metrics, including $Fid_+$, $Fid_-$, and $Fid_\Delta$. Specifically, a formal, information-theoretic definition of explainability is introduced and it is shown that existing metrics often fail to align with this definition across various statistical scenarios. The reason is due to potential distribution shifts when subgraphs are removed in computing these fidelity measures. Subsequently, a robust class of fidelity measures are introduced, and it is shown analytically that they are resilient to distribution shift issues and are applicable in a wide range of scenarios. Extensive empirical analysis on both synthetic and real datasets are provided to illustrate that the proposed metrics are more coherent with gold standard metrics.
RegExplainer: Generating Explanations for Graph Neural Networks in Regression Task
Jul 25, 2023Graph regression is a fundamental task and has received increasing attention in a wide range of graph learning tasks. However, the inference process is often not interpretable. Most existing explanation techniques are limited to understanding GNN behaviors in classification tasks. In this work, we seek an explanation to interpret the graph regression models (XAIG-R). We show that existing methods overlook the distribution shifting and continuously ordered decision boundary, which hinders them away from being applied in the regression tasks. To address these challenges, we propose a novel objective based on the information bottleneck theory and introduce a new mix-up framework, which could support various GNNs in a model-agnostic manner. We further present a contrastive learning strategy to tackle the continuously ordered labels in regression task. To empirically verify the effectiveness of the proposed method, we introduce three benchmark datasets and a real-life dataset for evaluation. Extensive experiments show the effectiveness of the proposed method in interpreting GNN models in regression tasks.