 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaSR-RAG: Taxonomy-guided Structured Reasoning for Retrieval-Augmented Generation
Mar 10, 2026Retrieval-Augmented Generation (RAG) helps large language models (LLMs) answer knowledge-intensive and time-sensitive questions by conditioning generation on external evidence. However, most RAG systems still retrieve unstructured chunks and rely on one-shot generation, which often yields redundant context, low information density, and brittle multi-hop reasoning. While structured RAG pipelines can improve grounding, they typically require costly and error-prone graph construction or impose rigid entity-centric structures that do not align with the query's reasoning chain. We propose \textsc{TaSR-RAG}, a taxonomy-guided structured reasoning framework for evidence selection. We represent both queries and documents as relational triples, and constrain entity semantics with a lightweight two-level taxonomy to balance generalization and precision. Given a complex question, \textsc{TaSR-RAG} decomposes it into an ordered sequence of triple sub-queries with explicit latent variables, then performs step-wise evidence selection via hybrid triple matching that combines semantic similarity over raw triples with structural consistency over typed triples. By maintaining an explicit entity binding table across steps, \textsc{TaSR-RAG} resolves intermediate variables and reduces entity conflation without explicit graph construction or exhaustive search. Experiments on multiple multi-hop question answering benchmarks show that \textsc{TaSR-RAG} consistently outperforms strong RAG and structured-RAG baselines by up to 14\%, while producing clearer evidence attribution and more faithful reasoning traces.
Any Model, Any Place, Any Time: Get Remote Sensing Foundation Model Embeddings On Demand
Feb 27, 2026The remote sensing community is witnessing a rapid growth of foundation models, which provide powerful embeddings for a wide range of downstream tasks. However, practical adoption and fair comparison remain challenging due to substantial heterogeneity in model release formats, platforms and interfaces, and input data specifications. These inconsistencies significantly increase the cost of obtaining, using, and benchmarking embeddings across models. To address this issue, we propose rs-embed, a Python library that offers a unified, region of interst (ROI) centric interface: with a single line of code, users can retrieve embeddings from any supported model for any location and any time range. The library also provides efficient batch processing to enable large-scale embedding generation and evaluation. The code is available at: https://github.com/cybergis/rs-embed
Retrieval-Augmented Water Level Forecasting for Everglades
Aug 06, 2025Accurate water level forecasting is crucial for managing ecosystems such as the Everglades, a subtropical wetland vital for flood mitigation, drought management, water resource planning, and biodiversity conservation. While recent advances in deep learning, particularly time series foundation models, have demonstrated success in general-domain forecasting, their application in hydrology remains underexplored. Furthermore, they often struggle to generalize across diverse unseen datasets and domains, due to the lack of effective mechanisms for adaptation. To address this gap, we introduce Retrieval-Augmented Forecasting (RAF) into the hydrology domain, proposing a framework that retrieves historically analogous multivariate hydrological episodes to enrich the model input before forecasting. By maintaining an external archive of past observations, RAF identifies and incorporates relevant patterns from historical data, thereby enhancing contextual awareness and predictive accuracy without requiring the model for task-specific retraining or fine-tuning. Furthermore, we explore and compare both similarity-based and mutual information-based RAF methods. We conduct a comprehensive evaluation on real-world data from the Everglades, demonstrating that the RAF framework yields substantial improvements in water level forecasting accuracy. This study highlights the potential of RAF approaches in environmental hydrology and paves the way for broader adoption of adaptive AI methods by domain experts in ecosystem management. The code and data are available at https://github.com/rahuul2992000/WaterRAF.
Hypercube-RAG: Hypercube-Based Retrieval-Augmented Generation for In-domain Scientific Question-Answering
May 25, 2025

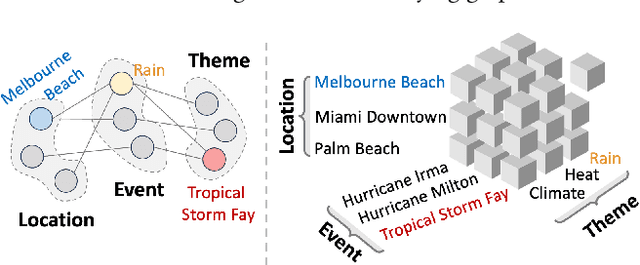
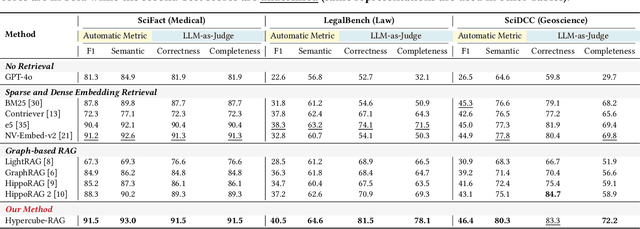
Large language models (LLMs) often need to incorporate external knowledge to solve theme-specific problems. Retrieval-augmented generation (RAG), which empowers LLMs to generate more qualified responses with retrieved external data and knowledge, has shown its high promise. However, traditional semantic similarity-based RAGs struggle to return concise yet highly relevant information for domain knowledge-intensive tasks, such as scientific question-answering (QA). Built on a multi-dimensional (cube) structure called Hypercube, which can index documents in an application-driven, human-defined, multi-dimensional space, we introduce the Hypercube-RAG, a novel RAG framework for precise and efficient retrieval. Given a query, Hypercube-RAG first decomposes it based on its entities and topics and then retrieves relevant documents from cubes by aligning these decomposed components with hypercube dimensions. Experiments on three in-domain scientific QA datasets demonstrate that our method improves accuracy by 3.7% and boosts retrieval efficiency by 81.2%, measured as relative gains over the strongest RAG baseline. More importantly, our Hypercube-RAG inherently offers explainability by revealing the underlying predefined hypercube dimensions used for retrieval. The code and data sets are available at https://github.com/JimengShi/Hypercube-RAG.
How Effective are Large Time Series Models in Hydrology? A Study on Water Level Forecasting in Everglades
May 02, 2025The Everglades play a crucial role in flood and drought regulation, water resource planning, and ecosystem management in the surrounding regions. However, traditional physics-based and statistical methods for predicting water levels often face significant challenges, including high computational costs and limited adaptability to diverse or unforeseen conditions. Recent advancements in large time series models have demonstrated the potential to address these limitations, with state-of-the-art deep learning and foundation models achieving remarkable success in time series forecasting across various domains. Despite this progress, their application to critical environmental systems, such as the Everglades, remains underexplored. In this study, we fill the gap by investigating twelve task-specific models and five time series foundation models across six categories for a real-world application focused on water level prediction in the Everglades. Our primary results show that the foundation model, Chronos, significantly outperforms all other models while the remaining foundation models exhibit relatively poor performance. Moreover, the performance of task-specific models varies with the model architectures. Lastly, we discuss the possible reasons for the varying performance of models.
Deep Learning and Foundation Models for Weather Prediction: A Survey
Jan 12, 2025Physics-based numerical models have been the bedrock of atmospheric sciences for decades, offering robust solutions but often at the cost of significant computational resources. Deep learning (DL) models have emerged as powerful tools in meteorology, capable of analyzing complex weather and climate data by learning intricate dependencies and providing rapid predictions once trained. While these models demonstrate promising performance in weather prediction, often surpassing traditional physics-based methods, they still face critical challenges. This paper presents a comprehensive survey of recent deep learning and foundation models for weather prediction. We propose a taxonomy to classify existing models based on their training paradigms: deterministic predictive learning, probabilistic generative learning, and pre-training and fine-tuning. For each paradigm, we delve into the underlying model architectures, address major challenges, offer key insights, and propose targeted directions for future research. Furthermore, we explore real-world applications of these methods and provide a curated summary of open-source code repositories and widely used datasets, aiming to bridge research advancements with practical implementations while fostering open and trustworthy scientific practices in adopting cutting-edge artificial intelligence for weather prediction. The related sources are available at https://github.com/JimengShi/ DL-Foundation-Models-Weather.
ReFine: Boosting Time Series Prediction of Extreme Events by Reweighting and Fine-tuning
Sep 21, 2024Extreme events are of great importance since they often represent impactive occurrences. For instance, in terms of climate and weather, extreme events might be major storms, floods, extreme heat or cold waves, and more. However, they are often located at the tail of the data distribution. Consequently, accurately predicting these extreme events is challenging due to their rarity and irregularity. Prior studies have also referred to this as the out-of-distribution (OOD) problem, which occurs when the distribution of the test data is substantially different from that used for training. In this work, we propose two strategies, reweighting and fine-tuning, to tackle the challenge. Reweighting is a strategy used to force machine learning models to focus on extreme events, which is achieved by a weighted loss function that assigns greater penalties to the prediction errors for the extreme samples relative to those on the remainder of the data. Unlike previous intuitive reweighting methods based on simple heuristics of data distribution, we employ meta-learning to dynamically optimize these penalty weights. To further boost the performance on extreme samples, we start from the reweighted models and fine-tune them using only rare extreme samples. Through extensive experiments on multiple data sets, we empirically validate that our meta-learning-based reweighting outperforms existing heuristic ones, and the fine-tuning strategy can further increase the model performance. More importantly, these two strategies are model-agnostic, which can be implemented on any type of neural network for time series forecasting. The open-sourced code is available at \url{https://github.com/JimengShi/ReFine}.
CoDiCast: Conditional Diffusion Model for Weather Prediction with Uncertainty Quantification
Sep 09, 2024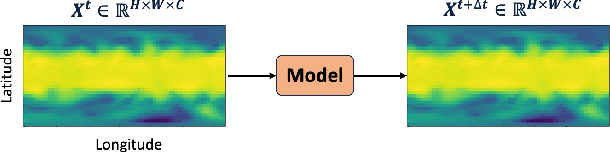
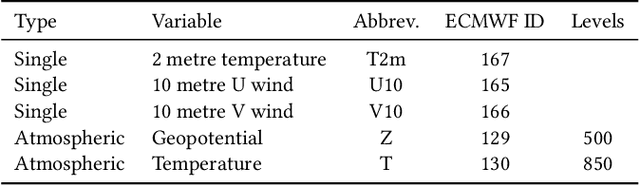
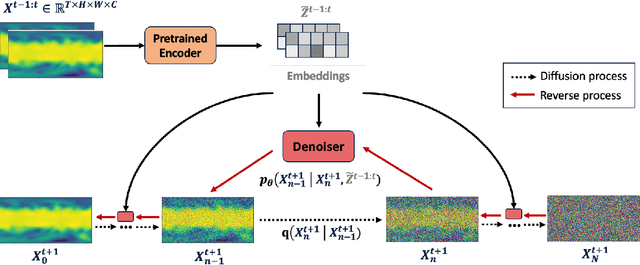
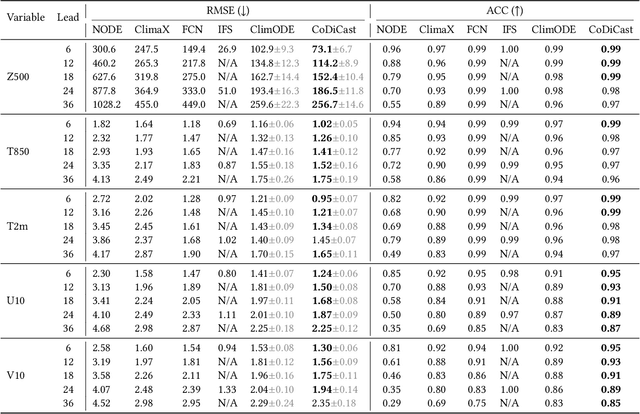
Accurate weather forecasting is critical for science and society. Yet, existing methods have not managed to simultaneously have the properties of high accuracy, low uncertainty, and high computational efficiency. On one hand, to quantify the uncertainty in weather predictions, the strategy of ensemble forecast (i.e., generating a set of diverse predictions) is often employed. However, traditional ensemble numerical weather prediction (NWP) is computationally intensive. On the other hand, most existing machine learning-based weather prediction (MLWP) approaches are efficient and accurate. Nevertheless, they are deterministic and cannot capture the uncertainty of weather forecasting. In this work, we propose CoDiCast, a conditional diffusion model to generate accurate global weather prediction, while achieving uncertainty quantification with ensemble forecasts and modest computational cost. The key idea is to simulate a conditional version of the reverse denoising process in diffusion models, which starts from pure Gaussian noise to generate realistic weather scenarios for a future time point. Each denoising step is conditioned on observations from the recent past. Ensemble forecasts are achieved by repeatedly sampling from stochastic Gaussian noise to represent uncertainty quantification. CoDiCast is trained on a decade of ERA5 reanalysis data from the European Centre for Medium-Range Weather Forecasts (ECMWF). Experimental results demonstrate that our approach outperforms several existing data-driven methods in accuracy. Our conditional diffusion model, CoDiCast, can generate 3-day global weather forecasts, at 6-hour steps and $5.625^\circ$ latitude-longitude resolution, for over 5 variables, in about 12 minutes on a commodity A100 GPU machine with 80GB memory. The open-souced code is provided at \url{https://github.com/JimengShi/CoDiCast}.
TimeX++: Learning Time-Series Explanations with Information Bottleneck
May 15, 2024Explaining deep learning models operating on time series data is crucial in various applications of interest which require interpretable and transparent insights from time series signals. In this work, we investigate this problem from an information theoretic perspective and show that most existing measures of explainability may suffer from trivial solutions and distributional shift issues. To address these issues, we introduce a simple yet practical objective function for time series explainable learning. The design of the objective function builds upon the principle of information bottleneck (IB), and modifies the IB objective function to avoid trivial solutions and distributional shift issues. We further present TimeX++, a novel explanation framework that leverages a parametric network to produce explanation-embedded instances that are both in-distributed and label-preserving. We evaluate TimeX++ on both synthetic and real-world datasets comparing its performance against leading baselines, and validate its practical efficacy through case studies in a real-world environmental application. Quantitative and qualitative evaluations show that TimeX++ outperforms baselines across all datasets, demonstrating a substantial improvement in explanation quality for time series data. The source code is available at \url{https://github.com/zichuan-liu/TimeXplusplus}.
FIDLAR: Forecast-Informed Deep Learning Architecture for Flood Mitigation
Feb 20, 2024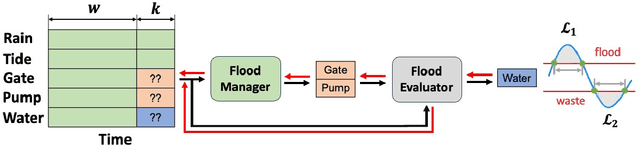

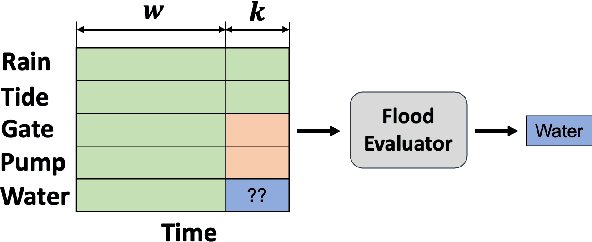
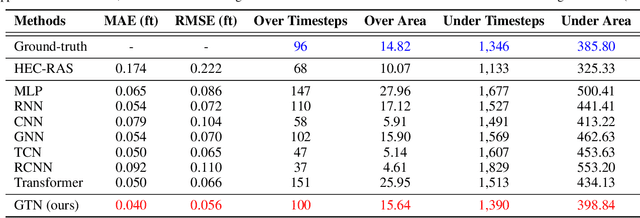
In coastal river systems, frequent floods, often occurring during major storms or king tides, pose a severe threat to lives and property. However, these floods can be mitigated or even prevented by strategically releasing water before extreme weather events with hydraulic structures such as dams, gates, pumps, and reservoirs. A standard approach used by local water management agencies is the "rule-based" method, which specifies predetermined pre-releases of water based on historical and time-tested human experience, but which tends to result in excess or inadequate water release. The model predictive control (MPC), a physics-based model for prediction, is an alternative approach, albeit involving computationally intensive calculations. In this paper, we propose a Forecast Informed Deep Learning Architecture, FIDLAR, to achieve rapid and optimal flood management with precise water pre-releases. FIDLAR seamlessly integrates two neural network modules: one called the Flood Manager, which is responsible for generating water pre-release schedules, and another called the Flood Evaluator, which assesses these generated schedules. The Evaluator module is pre-trained separately, and its gradient-based feedback is used to train the Manager model, ensuring optimal water pre-releases. We have conducted experiments using FIDLAR with data from a flood-prone coastal area in South Florida, particularly susceptible to frequent storms. Results show that FIDLAR is several orders of magnitude faster than currently used physics-based approaches while outperforming baseline methods with improved water pre-release schedules. Our code is at https://github.com/JimengShi/FIDLAR/.