 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Effective are Large Time Series Models in Hydrology? A Study on Water Level Forecasting in Everglades
May 02, 2025The Everglades play a crucial role in flood and drought regulation, water resource planning, and ecosystem management in the surrounding regions. However, traditional physics-based and statistical methods for predicting water levels often face significant challenges, including high computational costs and limited adaptability to diverse or unforeseen conditions. Recent advancements in large time series models have demonstrated the potential to address these limitations, with state-of-the-art deep learning and foundation models achieving remarkable success in time series forecasting across various domains. Despite this progress, their application to critical environmental systems, such as the Everglades, remains underexplored. In this study, we fill the gap by investigating twelve task-specific models and five time series foundation models across six categories for a real-world application focused on water level prediction in the Everglades. Our primary results show that the foundation model, Chronos, significantly outperforms all other models while the remaining foundation models exhibit relatively poor performance. Moreover, the performance of task-specific models varies with the model architectures. Lastly, we discuss the possible reasons for the varying performance of models.
Deep Learning and Foundation Models for Weather Prediction: A Survey
Jan 12, 2025Physics-based numerical models have been the bedrock of atmospheric sciences for decades, offering robust solutions but often at the cost of significant computational resources. Deep learning (DL) models have emerged as powerful tools in meteorology, capable of analyzing complex weather and climate data by learning intricate dependencies and providing rapid predictions once trained. While these models demonstrate promising performance in weather prediction, often surpassing traditional physics-based methods, they still face critical challenges. This paper presents a comprehensive survey of recent deep learning and foundation models for weather prediction. We propose a taxonomy to classify existing models based on their training paradigms: deterministic predictive learning, probabilistic generative learning, and pre-training and fine-tuning. For each paradigm, we delve into the underlying model architectures, address major challenges, offer key insights, and propose targeted directions for future research. Furthermore, we explore real-world applications of these methods and provide a curated summary of open-source code repositories and widely used datasets, aiming to bridge research advancements with practical implementations while fostering open and trustworthy scientific practices in adopting cutting-edge artificial intelligence for weather prediction. The related sources are available at https://github.com/JimengShi/ DL-Foundation-Models-Weather.
ReFine: Boosting Time Series Prediction of Extreme Events by Reweighting and Fine-tuning
Sep 21, 2024Extreme events are of great importance since they often represent impactive occurrences. For instance, in terms of climate and weather, extreme events might be major storms, floods, extreme heat or cold waves, and more. However, they are often located at the tail of the data distribution. Consequently, accurately predicting these extreme events is challenging due to their rarity and irregularity. Prior studies have also referred to this as the out-of-distribution (OOD) problem, which occurs when the distribution of the test data is substantially different from that used for training. In this work, we propose two strategies, reweighting and fine-tuning, to tackle the challenge. Reweighting is a strategy used to force machine learning models to focus on extreme events, which is achieved by a weighted loss function that assigns greater penalties to the prediction errors for the extreme samples relative to those on the remainder of the data. Unlike previous intuitive reweighting methods based on simple heuristics of data distribution, we employ meta-learning to dynamically optimize these penalty weights. To further boost the performance on extreme samples, we start from the reweighted models and fine-tune them using only rare extreme samples. Through extensive experiments on multiple data sets, we empirically validate that our meta-learning-based reweighting outperforms existing heuristic ones, and the fine-tuning strategy can further increase the model performance. More importantly, these two strategies are model-agnostic, which can be implemented on any type of neural network for time series forecasting. The open-sourced code is available at \url{https://github.com/JimengShi/ReFine}.
Explainable Parallel RCNN with Novel Feature Representation for Time Series Forecasting
May 08, 2023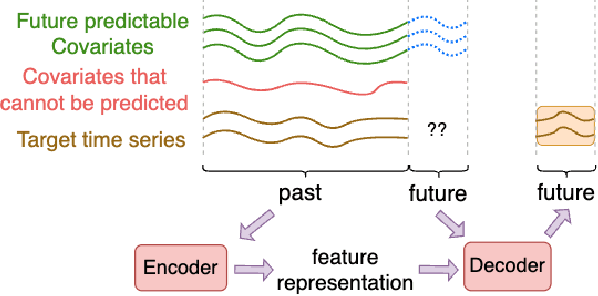
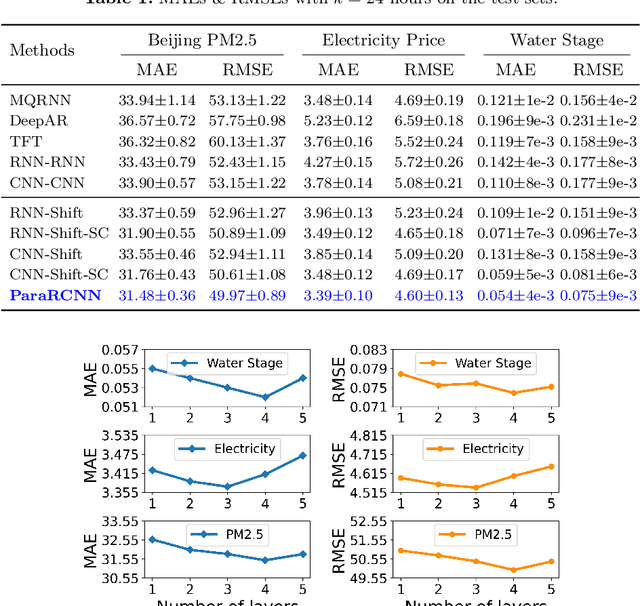
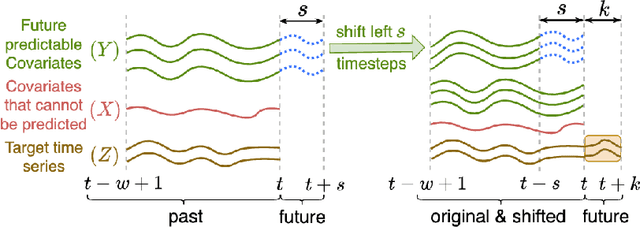
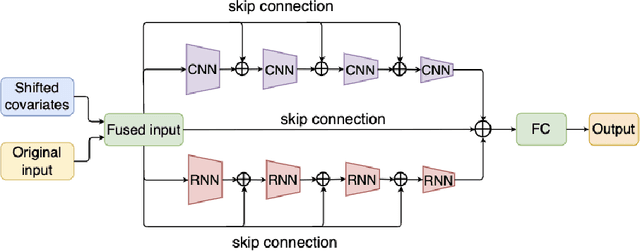
Accurate time series forecasting is a fundamental challenge in data science. It is often affected by external covariates such as weather or human intervention, which in many applications, may be predicted with reasonable accuracy. We refer to them as predicted future covariates. However, existing methods that attempt to predict time series in an iterative manner with autoregressive models end up with exponential error accumulations. Other strategies hat consider the past and future in the encoder and decoder respectively limit themselves by dealing with the historical and future data separately. To address these limitations, a novel feature representation strategy -- shifting -- is proposed to fuse the past data and future covariates such that their interactions can be considered. To extract complex dynamics in time series, we develop a parallel deep learning framework composed of RNN and CNN, both of which are used hierarchically. We also utilize the skip connection technique to improve the model's performance. Extensive experiments on three datasets reveal the effectiveness of our method. Finally, we demonstrate the model interpretability using the Grad-CAM algorithm.