 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLM$^2$otifs : An Explainable Framework for Machine-Generated Texts Detection
May 18, 2025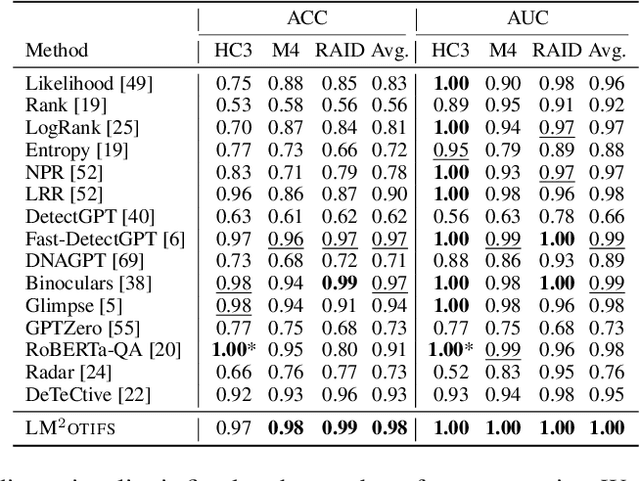
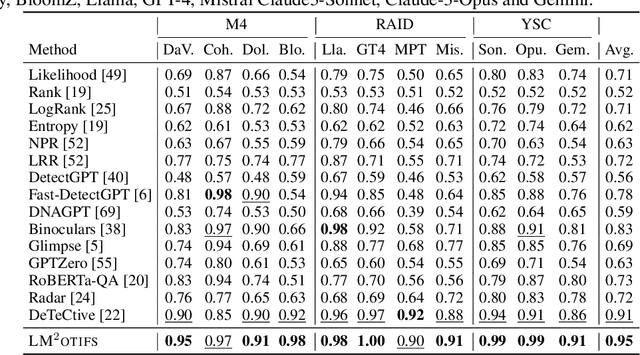
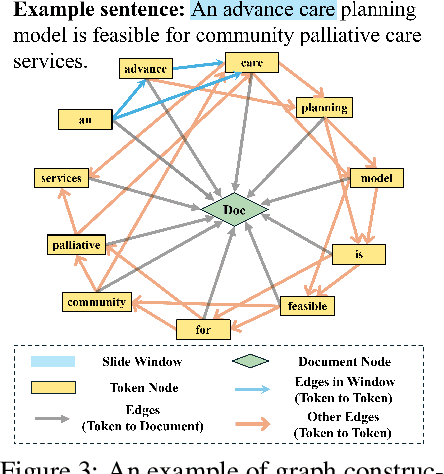
The impressive ability of large language models to generate natural text across various tasks has led to critical challenges in authorship authentication. Although numerous detection methods have been developed to differentiate between machine-generated texts (MGT) and human-generated texts (HGT), the explainability of these methods remains a significant gap. Traditional explainability techniques often fall short in capturing the complex word relationships that distinguish HGT from MGT. To address this limitation, we present LM$^2$otifs, a novel explainable framework for MGT detection. Inspired by probabilistic graphical models, we provide a theoretical rationale for the effectiveness. LM$^2$otifs utilizes eXplainable Graph Neural Networks to achieve both accurate detection and interpretability. The LM$^2$otifs pipeline operates in three key stages: first, it transforms text into graphs based on word co-occurrence to represent lexical dependencies; second, graph neural networks are used for prediction; and third, a post-hoc explainability method extracts interpretable motifs, offering multi-level explanations from individual words to sentence structures. Extensive experiments on multiple benchmark datasets demonstrate the comparable performance of LM$^2$otifs. The empirical evaluation of the extracted explainable motifs confirms their effectiveness in differentiating HGT and MGT. Furthermore, qualitative analysis reveals distinct and visible linguistic fingerprints characteristic of MGT.
In-Application Defense Against Evasive Web Scans through Behavioral Analysis
Dec 09, 2024



Web traffic has evolved to include both human users and automated agents, ranging from benign web crawlers to adversarial scanners such as those capable of credential stuffing, command injection, and account hijacking at the web scale. The estimated financial costs of these adversarial activities are estimated to exceed tens of billions of dollars in 2023. In this work, we introduce WebGuard, a low-overhead in-application forensics engine, to enable robust identification and monitoring of automated web scanners, and help mitigate the associated security risks. WebGuard focuses on the following design criteria: (i) integration into web applications without any changes to the underlying software components or infrastructure, (ii) minimal communication overhead, (iii) capability for real-time detection, e.g., within hundreds of milliseconds, and (iv) attribution capability to identify new behavioral patterns and detect emerging agent categories. To this end, we have equipped WebGuard with multi-modal behavioral monitoring mechanisms, such as monitoring spatio-temporal data and browser events. We also design supervised and unsupervised learning architectures for real-time detection and offline attribution of human and automated agents, respectively. Information theoretic analysis and empirical evaluations are provided to show that multi-modal data analysis, as opposed to uni-modal analysis which relies solely on mouse movement dynamics, significantly improves time-to-detection and attribution accuracy. Various numerical evaluations using real-world data collected via WebGuard are provided achieving high accuracy in hundreds of milliseconds, with a communication overhead below 10 KB per second.
Explanation-Preserving Augmentation for Semi-Supervised Graph Representation Learning
Oct 16, 2024Graph representation learning (GRL), enhanced by graph augmentation methods, has emerged as an effective technique achieving performance improvements in wide tasks such as node classification and graph classification. In self-supervised GRL, paired graph augmentations are generated from each graph. Its objective is to infer similar representations for augmentations of the same graph, but maximally distinguishable representations for augmentations of different graphs. Analogous to image and language domains, the desiderata of an ideal augmentation method include both (1) semantics-preservation; and (2) data-perturbation; i.e., an augmented graph should preserve the semantics of its original graph while carrying sufficient variance. However, most existing (un-)/self-supervised GRL methods focus on data perturbation but largely neglect semantics preservation. To address this challenge, in this paper, we propose a novel method, Explanation-Preserving Augmentation (EPA), that leverages graph explanation techniques for generating augmented graphs that can bridge the gap between semantics-preservation and data-perturbation. EPA first uses a small number of labels to train a graph explainer to infer the sub-structures (explanations) that are most relevant to a graph's semantics. These explanations are then used to generate semantics-preserving augmentations for self-supervised GRL, namely EPA-GRL. We demonstrate theoretically, using an analytical example, and through extensive experiments on a variety of benchmark datasets that EPA-GRL outperforms the state-of-the-art (SOTA) GRL methods, which are built upon semantics-agnostic data augmentations.