 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeb2Code: A Large-scale Webpage-to-Code Dataset and Evaluation Framework for Multimodal LLMs
Jun 28, 2024



Multimodal large language models (MLLMs) have shown impressive success across modalities such as image, video, and audio in a variety of understanding and generation tasks. However, current MLLMs are surprisingly poor at understanding webpage screenshots and generating their corresponding HTML code. To address this problem, we propose Web2Code, a benchmark consisting of a new large-scale webpage-to-code dataset for instruction tuning and an evaluation framework for the webpage understanding and HTML code translation abilities of MLLMs. For dataset construction, we leverage pretrained LLMs to enhance existing webpage-to-code datasets as well as generate a diverse pool of new webpages rendered into images. Specifically, the inputs are webpage images and instructions, while the responses are the webpage's HTML code. We further include diverse natural language QA pairs about the webpage content in the responses to enable a more comprehensive understanding of the web content. To evaluate model performance in these tasks, we develop an evaluation framework for testing MLLMs' abilities in webpage understanding and web-to-code generation. Extensive experiments show that our proposed dataset is beneficial not only to our proposed tasks but also in the general visual domain, while previous datasets result in worse performance. We hope our work will contribute to the development of general MLLMs suitable for web-based content generation and task automation. Our data and code will be available at https://github.com/MBZUAI-LLM/web2code.
AutoVideo: An Automated Video Action Recognition System
Aug 10, 2021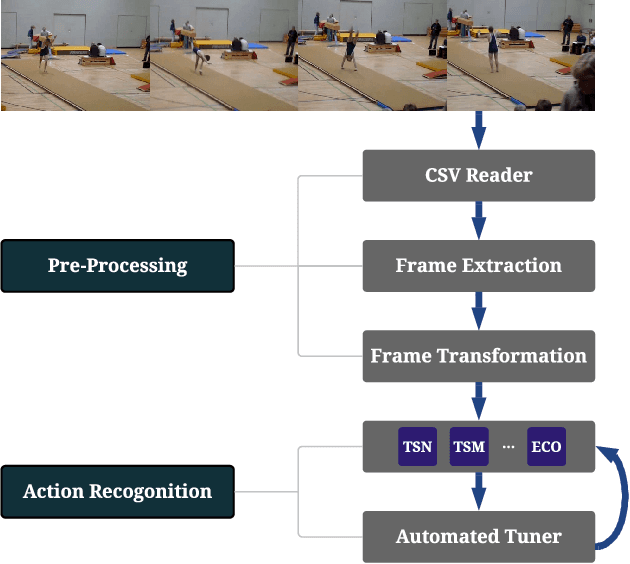

Action recognition is a crucial task for video understanding. In this paper, we present AutoVideo, a Python system for automated video action recognition. It currently supports seven action recognition algorithms and various pre-processing modules. Unlike the existing libraries that only provide model zoos, AutoVideo is built with the standard pipeline language. The basic building block is primitive, which wraps a pre-processing module or an algorithm with some hyperparameters. AutoVideo is highly modular and extendable. It can be easily combined with AutoML searchers. The pipeline language is quite general so that we can easily enrich AutoVideo with algorithms for various other video-related tasks in the future. AutoVideo is released under MIT license at https://github.com/datamllab/autovideo