 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmni-MMSI: Toward Identity-attributed Social Interaction Understanding
Mar 31, 2026We introduce Omni-MMSI, a new task that requires comprehensive social interaction understanding from raw audio, vision, and speech input. The task involves perceiving identity-attributed social cues (e.g., who is speaking what) and reasoning about the social interaction (e.g., whom the speaker refers to). This task is essential for developing AI assistants that can perceive and respond to human interactions. Unlike prior studies that operate on oracle-preprocessed social cues, Omni-MMSI reflects realistic scenarios where AI assistants must perceive and reason from raw data. However, existing pipelines and multi-modal LLMs perform poorly on Omni-MMSI because they lack reliable identity attribution capabilities, which leads to inaccurate social interaction understanding. To address this challenge, we propose Omni-MMSI-R, a reference-guided pipeline that produces identity-attributed social cues with tools and conducts chain-of-thought social reasoning. To facilitate this pipeline, we construct participant-level reference pairs and curate reasoning annotations on top of the existing datasets. Experiments demonstrate that Omni-MMSI-R outperforms advanced LLMs and counterparts on Omni-MMSI. Project page: https://sampson-lee.github.io/omni-mmsi-project-page.
ARGaze: Autoregressive Transformers for Online Egocentric Gaze Estimation
Feb 04, 2026Online egocentric gaze estimation predicts where a camera wearer is looking from first-person video using only past and current frames, a task essential for augmented reality and assistive technologies. Unlike third-person gaze estimation, this setting lacks explicit head or eye signals, requiring models to infer current visual attention from sparse, indirect cues such as hand-object interactions and salient scene content. We observe that gaze exhibits strong temporal continuity during goal-directed activities: knowing where a person looked recently provides a powerful prior for predicting where they look next. Inspired by vision-conditioned autoregressive decoding in vision-language models, we propose ARGaze, which reformulates gaze estimation as sequential prediction: at each timestep, a transformer decoder predicts current gaze by conditioning on (i) current visual features and (ii) a fixed-length Gaze Context Window of recent gaze target estimates. This design enforces causality and enables bounded-resource streaming inference. We achieve state-of-the-art performance across multiple egocentric benchmarks under online evaluation, with extensive ablations validating that autoregressive modeling with bounded gaze history is critical for robust prediction. We will release our source code and pre-trained models.
Incorporating Flexible Image Conditioning into Text-to-Video Diffusion Models without Training
May 27, 2025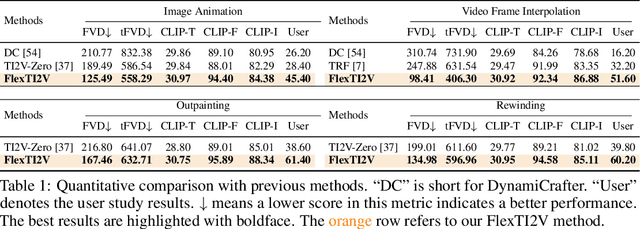
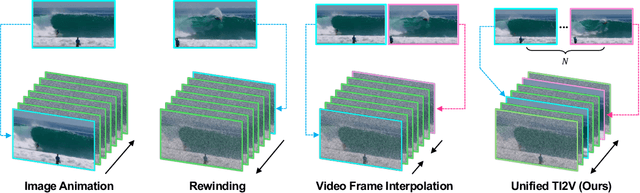
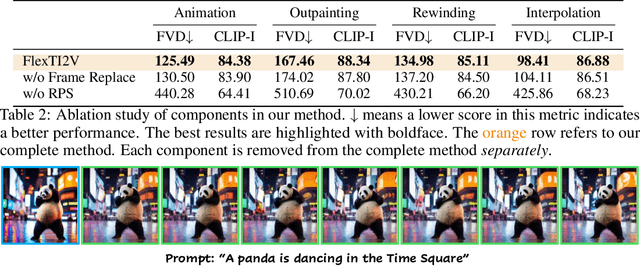
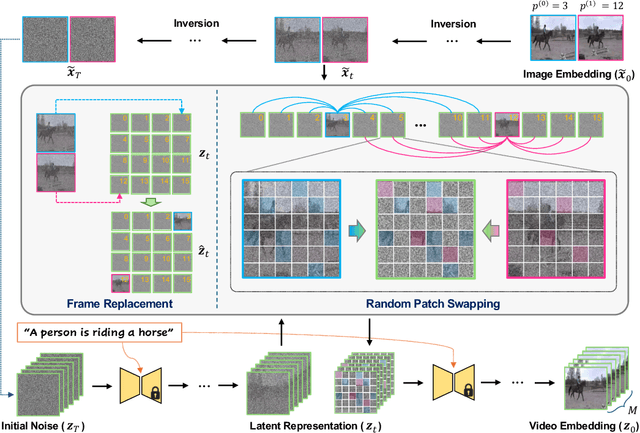
Text-image-to-video (TI2V) generation is a critical problem for controllable video generation using both semantic and visual conditions. Most existing methods typically add visual conditions to text-to-video (T2V) foundation models by finetuning, which is costly in resources and only limited to a few predefined conditioning settings. To tackle this issue, we introduce a unified formulation for TI2V generation with flexible visual conditioning. Furthermore, we propose an innovative training-free approach, dubbed FlexTI2V, that can condition T2V foundation models on an arbitrary amount of images at arbitrary positions. Specifically, we firstly invert the condition images to noisy representation in a latent space. Then, in the denoising process of T2V models, our method uses a novel random patch swapping strategy to incorporate visual features into video representations through local image patches. To balance creativity and fidelity, we use a dynamic control mechanism to adjust the strength of visual conditioning to each video frame. Extensive experiments validate that our method surpasses previous training-free image conditioning methods by a notable margin. We also show more insights of our method by detailed ablation study and analysis.
SocialGesture: Delving into Multi-person Gesture Understanding
Apr 03, 2025Previous research in human gesture recognition has largely overlooked multi-person interactions, which are crucial for understanding the social context of naturally occurring gestures. This limitation in existing datasets presents a significant challenge in aligning human gestures with other modalities like language and speech. To address this issue, we introduce SocialGesture, the first large-scale dataset specifically designed for multi-person gesture analysis. SocialGesture features a diverse range of natural scenarios and supports multiple gesture analysis tasks, including video-based recognition and temporal localization, providing a valuable resource for advancing the study of gesture during complex social interactions. Furthermore, we propose a novel visual question answering (VQA) task to benchmark vision language models'(VLMs) performance on social gesture understanding. Our findings highlight several limitations of current gesture recognition models, offering insights into future directions for improvement in this field. SocialGesture is available at huggingface.co/datasets/IrohXu/SocialGesture.
Learning Predictive Visuomotor Coordination
Mar 30, 2025Understanding and predicting human visuomotor coordination is crucial for applications in robotics, human-computer interaction, and assistive technologies. This work introduces a forecasting-based task for visuomotor modeling, where the goal is to predict head pose, gaze, and upper-body motion from egocentric visual and kinematic observations. We propose a \textit{Visuomotor Coordination Representation} (VCR) that learns structured temporal dependencies across these multimodal signals. We extend a diffusion-based motion modeling framework that integrates egocentric vision and kinematic sequences, enabling temporally coherent and accurate visuomotor predictions. Our approach is evaluated on the large-scale EgoExo4D dataset, demonstrating strong generalization across diverse real-world activities. Our results highlight the importance of multimodal integration in understanding visuomotor coordination, contributing to research in visuomotor learning and human behavior modeling.
Towards Online Multi-Modal Social Interaction Understanding
Mar 25, 2025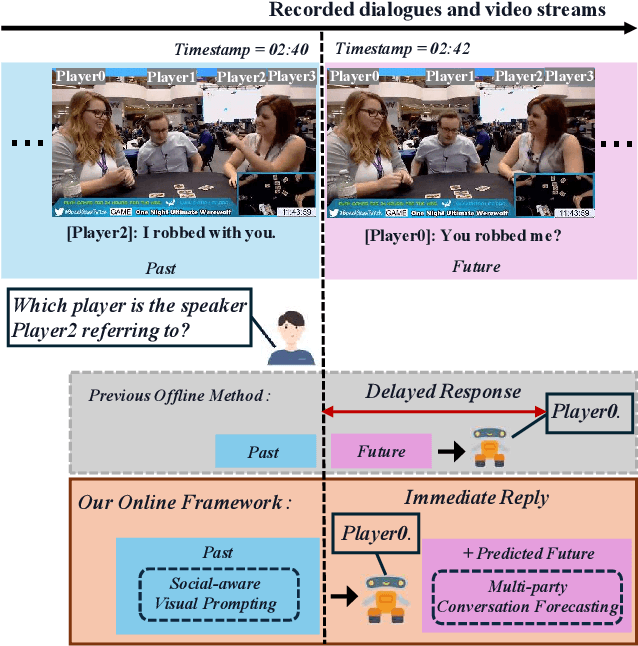
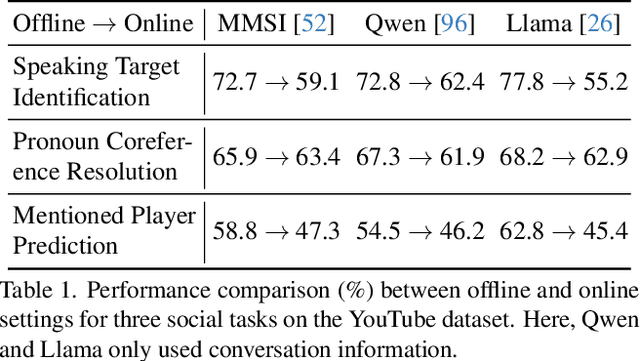
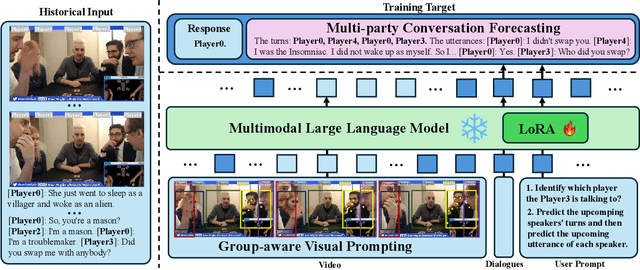
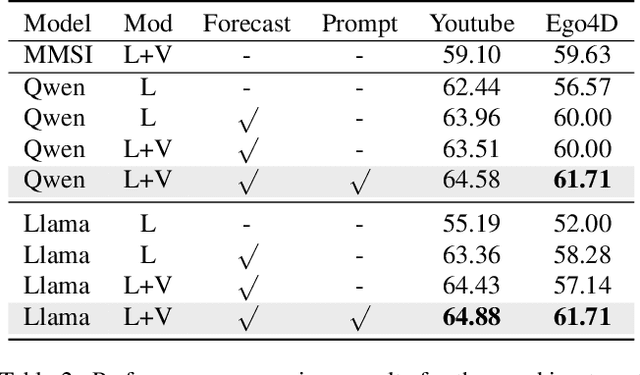
Multimodal social interaction understanding (MMSI) is critical in human-robot interaction systems. In real-world scenarios, AI agents are required to provide real-time feedback. However, existing models often depend on both past and future contexts, which hinders them from applying to real-world problems. To bridge this gap, we propose an online MMSI setting, where the model must resolve MMSI tasks using only historical information, such as recorded dialogues and video streams. To address the challenges of missing the useful future context, we develop a novel framework, named Online-MMSI-VLM, that leverages two complementary strategies: multi-party conversation forecasting and social-aware visual prompting with multi-modal large language models. First, to enrich linguistic context, the multi-party conversation forecasting simulates potential future utterances in a coarse-to-fine manner, anticipating upcoming speaker turns and then generating fine-grained conversational details. Second, to effectively incorporate visual social cues like gaze and gesture, social-aware visual prompting highlights the social dynamics in video with bounding boxes and body keypoints for each person and frame. Extensive experiments on three tasks and two datasets demonstrate that our method achieves state-of-the-art performance and significantly outperforms baseline models, indicating its effectiveness on Online-MMSI. The code and pre-trained models will be publicly released at: https://github.com/Sampson-Lee/OnlineMMSI.
Building a Mind Palace: Structuring Environment-Grounded Semantic Graphs for Effective Long Video Analysis with LLMs
Jan 08, 2025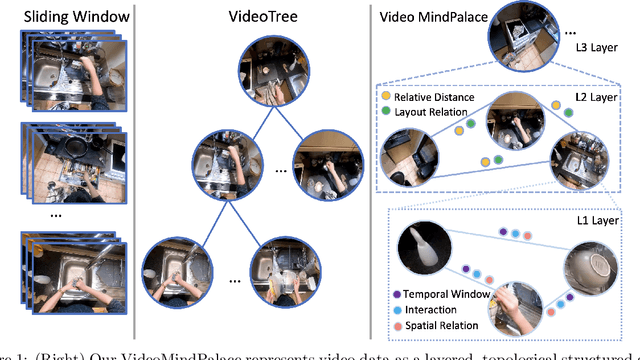
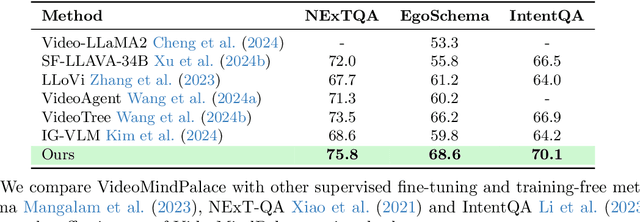
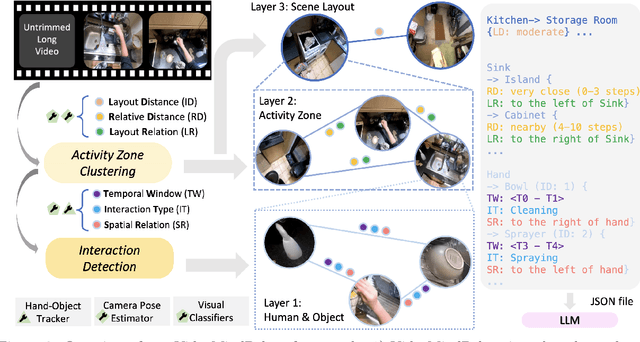
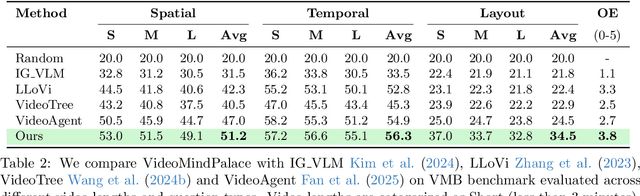
Long-form video understanding with Large Vision Language Models is challenged by the need to analyze temporally dispersed yet spatially concentrated key moments within limited context windows. In this work, we introduce VideoMindPalace, a new framework inspired by the "Mind Palace", which organizes critical video moments into a topologically structured semantic graph. VideoMindPalace organizes key information through (i) hand-object tracking and interaction, (ii) clustered activity zones representing specific areas of recurring activities, and (iii) environment layout mapping, allowing natural language parsing by LLMs to provide grounded insights on spatio-temporal and 3D context. In addition, we propose the Video MindPalace Benchmark (VMB), to assess human-like reasoning, including spatial localization, temporal reasoning, and layout-aware sequential understanding. Evaluated on VMB and established video QA datasets, including EgoSchema, NExT-QA, IntentQA, and the Active Memories Benchmark, VideoMindPalace demonstrates notable gains in spatio-temporal coherence and human-aligned reasoning, advancing long-form video analysis capabilities in VLMs.
Unleashing In-context Learning of Autoregressive Models for Few-shot Image Manipulation
Dec 03, 2024



Text-guided image manipulation has experienced notable advancement in recent years. In order to mitigate linguistic ambiguity, few-shot learning with visual examples has been applied for instructions that are underrepresented in the training set, or difficult to describe purely in language. However, learning from visual prompts requires strong reasoning capability, which diffusion models are struggling with. To address this issue, we introduce a novel multi-modal autoregressive model, dubbed $\textbf{InstaManip}$, that can $\textbf{insta}$ntly learn a new image $\textbf{manip}$ulation operation from textual and visual guidance via in-context learning, and apply it to new query images. Specifically, we propose an innovative group self-attention mechanism to break down the in-context learning process into two separate stages -- learning and applying, which simplifies the complex problem into two easier tasks. We also introduce a relation regularization method to further disentangle image transformation features from irrelevant contents in exemplar images. Extensive experiments suggest that our method surpasses previous few-shot image manipulation models by a notable margin ($\geq$19% in human evaluation). We also find our model can be further boosted by increasing the number or diversity of exemplar images.
Human Action Anticipation: A Survey
Oct 17, 2024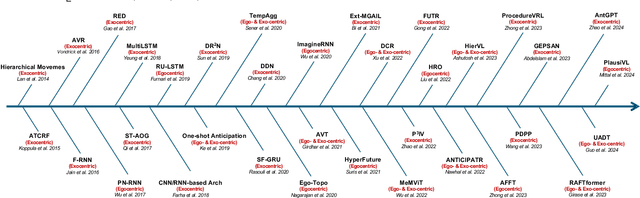

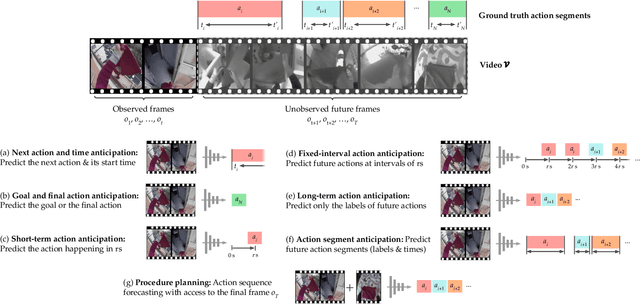
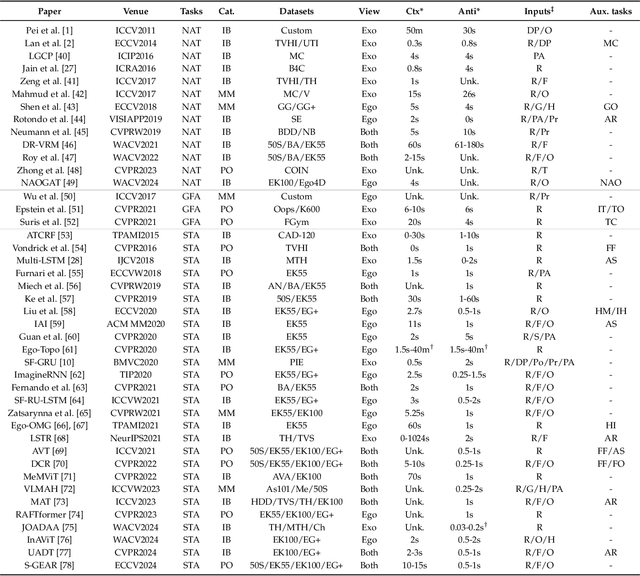
Predicting future human behavior is an increasingly popular topic in computer vision, driven by the interest in applications such as autonomous vehicles, digital assistants and human-robot interactions. The literature on behavior prediction spans various tasks, including action anticipation, activity forecasting, intent prediction, goal prediction, and so on. Our survey aims to tie together this fragmented literature, covering recent technical innovations as well as the development of new large-scale datasets for model training and evaluation. We also summarize the widely-used metrics for different tasks and provide a comprehensive performance comparison of existing approaches on eleven action anticipation datasets. This survey serves as not only a reference for contemporary methodologies in action anticipation, but also a guideline for future research direction of this evolving landscape.
MM-SpuBench: Towards Better Understanding of Spurious Biases in Multimodal LLMs
Jun 24, 2024



Spurious bias, a tendency to use spurious correlations between non-essential input attributes and target variables for predictions, has revealed a severe robustness pitfall in deep learning models trained on single modality data. Multimodal Large Language Models (MLLMs), which integrate both vision and language models, have demonstrated strong capability in joint vision-language understanding. However, whether spurious biases are prevalent in MLLMs remains under-explored. We mitigate this gap by analyzing the spurious biases in a multimodal setting, uncovering the specific test data patterns that can manifest this problem when biases in the vision model cascade into the alignment between visual and text tokens in MLLMs. To better understand this problem, we introduce MM-SpuBench, a comprehensive visual question-answering (VQA) benchmark designed to evaluate MLLMs' reliance on nine distinct categories of spurious correlations from five open-source image datasets. The VQA dataset is built from human-understandable concept information (attributes). Leveraging this benchmark, we conduct a thorough evaluation of current state-of-the-art MLLMs. Our findings illuminate the persistence of the reliance on spurious correlations from these models and underscore the urge for new methodologies to mitigate spurious biases. To support the MLLM robustness research, we release our VQA benchmark at https://huggingface.co/datasets/mmbench/MM-SpuBench.