 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Multimodal Social Interactions: New Challenges and Baselines with Densely Aligned Representations
Paper and Code



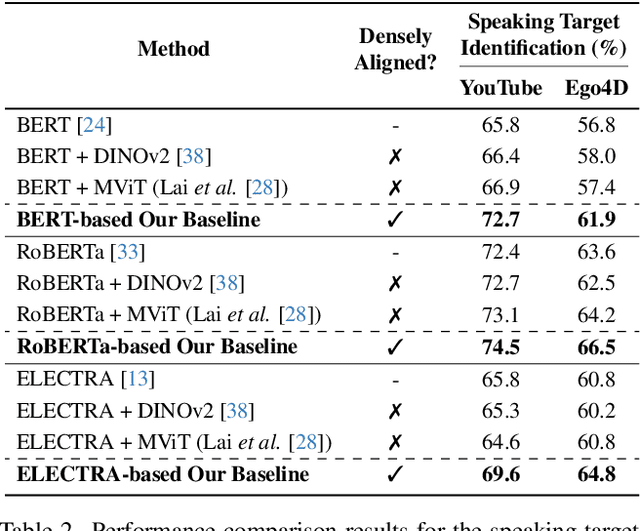
Understanding social interactions involving both verbal and non-verbal cues is essential to effectively interpret social situations. However, most prior works on multimodal social cues focus predominantly on single-person behaviors or rely on holistic visual representations that are not densely aligned to utterances in multi-party environments. They are limited in modeling the intricate dynamics of multi-party interactions. In this paper, we introduce three new challenging tasks to model the fine-grained dynamics between multiple people: speaking target identification, pronoun coreference resolution, and mentioned player prediction. We contribute extensive data annotations to curate these new challenges in social deduction game settings. Furthermore, we propose a novel multimodal baseline that leverages densely aligned language-visual representations by synchronizing visual features with their corresponding utterances. This facilitates concurrently capturing verbal and non-verbal cues pertinent to social reasoning. Experiments demonstrate the effectiveness of the proposed approach with densely aligned multimodal representations in modeling social interactions. We will release our benchmarks and source code to facilitate further research.