 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboMatch: A Mobile-Manipulation Teleoperation Platform with Auto-Matching Network Architecture for Long-Horizon Manipulation
Sep 10, 2025



This paper presents RoboMatch, a novel unified teleoperation platform for mobile manipulation with an auto-matching network architecture, designed to tackle long-horizon tasks in dynamic environments. Our system enhances teleoperation performance, data collection efficiency, task accuracy, and operational stability. The core of RoboMatch is a cockpit-style control interface that enables synchronous operation of the mobile base and dual arms, significantly improving control precision and data collection. Moreover, we introduce the Proprioceptive-Visual Enhanced Diffusion Policy (PVE-DP), which leverages Discrete Wavelet Transform (DWT) for multi-scale visual feature extraction and integrates high-precision IMUs at the end-effector to enrich proprioceptive feedback, substantially boosting fine manipulation performance. Furthermore, we propose an Auto-Matching Network (AMN) architecture that decomposes long-horizon tasks into logical sequences and dynamically assigns lightweight pre-trained models for distributed inference. Experimental results demonstrate that our approach improves data collection efficiency by over 20%, increases task success rates by 20-30% with PVE-DP, and enhances long-horizon inference performance by approximately 40% with AMN, offering a robust solution for complex manipulation tasks.
LTDA-Drive: LLMs-guided Generative Models based Long-tail Data Augmentation for Autonomous Driving
May 21, 2025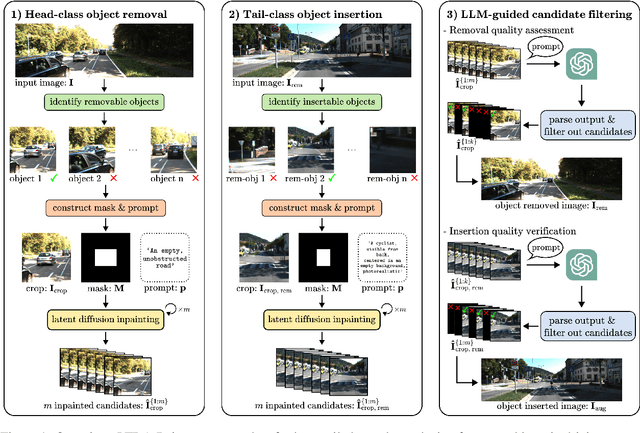
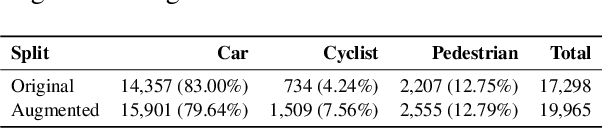

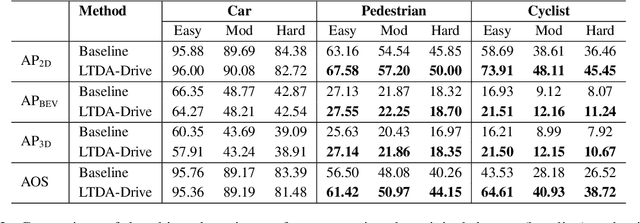
3D perception plays an essential role for improving the safety and performance of autonomous driving. Yet, existing models trained on real-world datasets, which naturally exhibit long-tail distributions, tend to underperform on rare and safety-critical, vulnerable classes, such as pedestrians and cyclists. Existing studies on reweighting and resampling techniques struggle with the scarcity and limited diversity within tail classes. To address these limitations, we introduce LTDA-Drive, a novel LLM-guided data augmentation framework designed to synthesize diverse, high-quality long-tail samples. LTDA-Drive replaces head-class objects in driving scenes with tail-class objects through a three-stage process: (1) text-guided diffusion models remove head-class objects, (2) generative models insert instances of the tail classes, and (3) an LLM agent filters out low-quality synthesized images. Experiments conducted on the KITTI dataset show that LTDA-Drive significantly improves tail-class detection, achieving 34.75\% improvement for rare classes over counterpart methods. These results further highlight the effectiveness of LTDA-Drive in tackling long-tail challenges by generating high-quality and diverse data.
ALN-P3: Unified Language Alignment for Perception, Prediction, and Planning in Autonomous Driving
May 21, 2025Recent advances have explored integrating large language models (LLMs) into end-to-end autonomous driving systems to enhance generalization and interpretability. However, most existing approaches are limited to either driving performance or vision-language reasoning, making it difficult to achieve both simultaneously. In this paper, we propose ALN-P3, a unified co-distillation framework that introduces cross-modal alignment between "fast" vision-based autonomous driving systems and "slow" language-driven reasoning modules. ALN-P3 incorporates three novel alignment mechanisms: Perception Alignment (P1A), Prediction Alignment (P2A), and Planning Alignment (P3A), which explicitly align visual tokens with corresponding linguistic outputs across the full perception, prediction, and planning stack. All alignment modules are applied only during training and incur no additional costs during inference. Extensive experiments on four challenging benchmarks-nuScenes, Nu-X, TOD3Cap, and nuScenes QA-demonstrate that ALN-P3 significantly improves both driving decisions and language reasoning, achieving state-of-the-art results.
NuPlanQA: A Large-Scale Dataset and Benchmark for Multi-View Driving Scene Understanding in Multi-Modal Large Language Models
Mar 17, 2025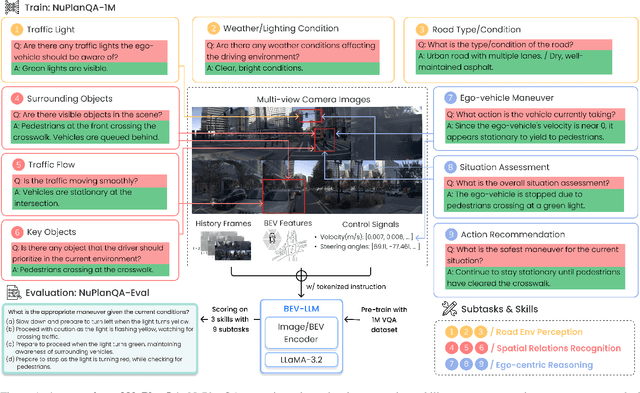
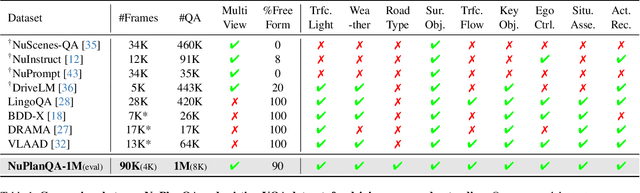
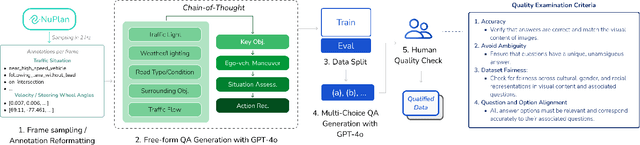
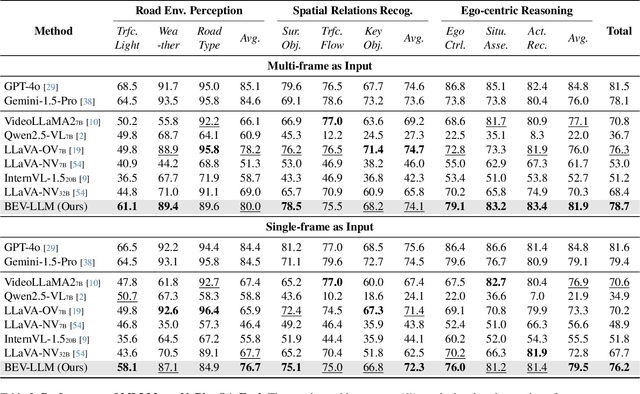
Recent advances in multi-modal large language models (MLLMs) have demonstrated strong performance across various domains; however, their ability to comprehend driving scenes remains less proven. The complexity of driving scenarios, which includes multi-view information, poses significant challenges for existing MLLMs. In this paper, we introduce NuPlanQA-Eval, a multi-view, multi-modal evaluation benchmark for driving scene understanding. To further support generalization to multi-view driving scenarios, we also propose NuPlanQA-1M, a large-scale dataset comprising 1M real-world visual question-answering (VQA) pairs. For context-aware analysis of traffic scenes, we categorize our dataset into nine subtasks across three core skills: Road Environment Perception, Spatial Relations Recognition, and Ego-Centric Reasoning. Furthermore, we present BEV-LLM, integrating Bird's-Eye-View (BEV) features from multi-view images into MLLMs. Our evaluation results reveal key challenges that existing MLLMs face in driving scene-specific perception and spatial reasoning from ego-centric perspectives. In contrast, BEV-LLM demonstrates remarkable adaptability to this domain, outperforming other models in six of the nine subtasks. These findings highlight how BEV integration enhances multi-view MLLMs while also identifying key areas that require further refinement for effective adaptation to driving scenes. To facilitate further research, we publicly release NuPlanQA at https://github.com/sungyeonparkk/NuPlanQA.
On-Board Vision-Language Models for Personalized Autonomous Vehicle Motion Control: System Design and Real-World Validation
Nov 17, 2024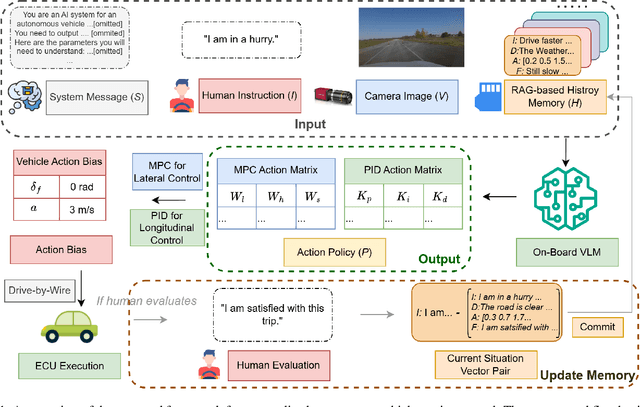
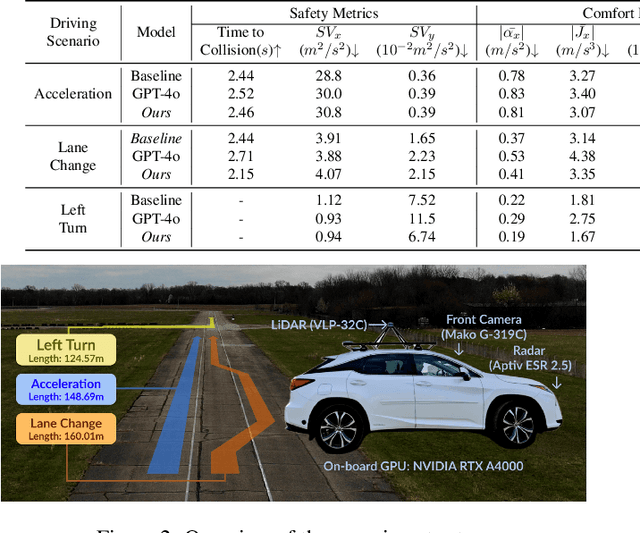

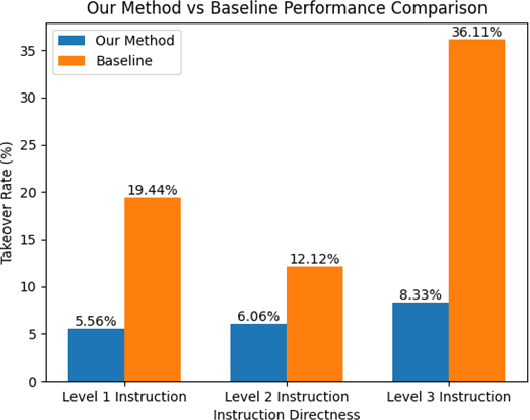
Personalized driving refers to an autonomous vehicle's ability to adapt its driving behavior or control strategies to match individual users' preferences and driving styles while maintaining safety and comfort standards. However, existing works either fail to capture every individual preference precisely or become computationally inefficient as the user base expands. Vision-Language Models (VLMs) offer promising solutions to this front through their natural language understanding and scene reasoning capabilities. In this work, we propose a lightweight yet effective on-board VLM framework that provides low-latency personalized driving performance while maintaining strong reasoning capabilities. Our solution incorporates a Retrieval-Augmented Generation (RAG)-based memory module that enables continuous learning of individual driving preferences through human feedback. Through comprehensive real-world vehicle deployment and experiments, our system has demonstrated the ability to provide safe, comfortable, and personalized driving experiences across various scenarios and significantly reduce takeover rates by up to 76.9%. To the best of our knowledge, this work represents the first end-to-end VLM-based motion control system in real-world autonomous vehicles.
MTA: Multimodal Task Alignment for BEV Perception and Captioning
Nov 16, 2024Bird's eye view (BEV)-based 3D perception plays a crucial role in autonomous driving applications. The rise of large language models has spurred interest in BEV-based captioning to understand object behavior in the surrounding environment. However, existing approaches treat perception and captioning as separate tasks, focusing on the performance of only one of the tasks and overlooking the potential benefits of multimodal alignment. To bridge this gap between modalities, we introduce MTA, a novel multimodal task alignment framework that boosts both BEV perception and captioning. MTA consists of two key components: (1) BEV-Language Alignment (BLA), a contextual learning mechanism that aligns the BEV scene representations with ground-truth language representations, and (2) Detection-Captioning Alignment (DCA), a cross-modal prompting mechanism that aligns detection and captioning outputs. MTA integrates into state-of-the-art baselines during training, adding no extra computational complexity at runtime. Extensive experiments on the nuScenes and TOD3Cap datasets show that MTA significantly outperforms state-of-the-art baselines, achieving a 4.9% improvement in perception and a 9.2% improvement in captioning. These results underscore the effectiveness of unified alignment in reconciling BEV-based perception and captioning.
Video Token Sparsification for Efficient Multimodal LLMs in Autonomous Driving
Sep 16, 2024



Multimodal large language models (MLLMs) have demonstrated remarkable potential for enhancing scene understanding in autonomous driving systems through powerful logical reasoning capabilities. However, the deployment of these models faces significant challenges due to their substantial parameter sizes and computational demands, which often exceed the constraints of onboard computation. One major limitation arises from the large number of visual tokens required to capture fine-grained and long-context visual information, leading to increased latency and memory consumption. To address this issue, we propose Video Token Sparsification (VTS), a novel approach that leverages the inherent redundancy in consecutive video frames to significantly reduce the total number of visual tokens while preserving the most salient information. VTS employs a lightweight CNN-based proposal model to adaptively identify key frames and prune less informative tokens, effectively mitigating hallucinations and increasing inference throughput without compromising performance. We conduct comprehensive experiments on the DRAMA and LingoQA benchmarks, demonstrating the effectiveness of VTS in achieving up to a 33\% improvement in inference throughput and a 28\% reduction in memory usage compared to the baseline without compromising performance.
MM-SpuBench: Towards Better Understanding of Spurious Biases in Multimodal LLMs
Jun 24, 2024



Spurious bias, a tendency to use spurious correlations between non-essential input attributes and target variables for predictions, has revealed a severe robustness pitfall in deep learning models trained on single modality data. Multimodal Large Language Models (MLLMs), which integrate both vision and language models, have demonstrated strong capability in joint vision-language understanding. However, whether spurious biases are prevalent in MLLMs remains under-explored. We mitigate this gap by analyzing the spurious biases in a multimodal setting, uncovering the specific test data patterns that can manifest this problem when biases in the vision model cascade into the alignment between visual and text tokens in MLLMs. To better understand this problem, we introduce MM-SpuBench, a comprehensive visual question-answering (VQA) benchmark designed to evaluate MLLMs' reliance on nine distinct categories of spurious correlations from five open-source image datasets. The VQA dataset is built from human-understandable concept information (attributes). Leveraging this benchmark, we conduct a thorough evaluation of current state-of-the-art MLLMs. Our findings illuminate the persistence of the reliance on spurious correlations from these models and underscore the urge for new methodologies to mitigate spurious biases. To support the MLLM robustness research, we release our VQA benchmark at https://huggingface.co/datasets/mmbench/MM-SpuBench.
What is the Visual Cognition Gap between Humans and Multimodal LLMs?
Jun 14, 2024Recently, Multimodal Large Language Models (MLLMs) have shown great promise in language-guided perceptual tasks such as recognition, segmentation, and object detection. However, their effectiveness in addressing visual cognition problems that require high-level reasoning is not well-established. One such challenge is abstract visual reasoning (AVR) -- the cognitive ability to discern relationships among patterns in a set of images and extrapolate to predict subsequent patterns. This skill is crucial during the early neurodevelopmental stages of children. Inspired by the AVR tasks in Raven's Progressive Matrices (RPM) and Wechsler Intelligence Scale for Children (WISC), we propose a new dataset MaRs-VQA and a new benchmark VCog-Bench containing three datasets to evaluate the zero-shot AVR capability of MLLMs and compare their performance with existing human intelligent investigation. Our comparative experiments with different open-source and closed-source MLLMs on the VCog-Bench revealed a gap between MLLMs and human intelligence, highlighting the visual cognitive limitations of current MLLMs. We believe that the public release of VCog-Bench, consisting of MaRs-VQA, and the inference pipeline will drive progress toward the next generation of MLLMs with human-like visual cognition abilities.
Quantifying Uncertainty in Motion Prediction with Variational Bayesian Mixture
Apr 04, 2024



Safety and robustness are crucial factors in developing trustworthy autonomous vehicles. One essential aspect of addressing these factors is to equip vehicles with the capability to predict future trajectories for all moving objects in the surroundings and quantify prediction uncertainties. In this paper, we propose the Sequential Neural Variational Agent (SeNeVA), a generative model that describes the distribution of future trajectories for a single moving object. Our approach can distinguish Out-of-Distribution data while quantifying uncertainty and achieving competitive performance compared to state-of-the-art methods on the Argoverse 2 and INTERACTION datasets. Specifically, a 0.446 meters minimum Final Displacement Error, a 0.203 meters minimum Average Displacement Error, and a 5.35% Miss Rate are achieved on the INTERACTION test set. Extensive qualitative and quantitative analysis is also provided to evaluate the proposed model. Our open-source code is available at https://github.com/PurdueDigitalTwin/seneva.