 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALN-P3: Unified Language Alignment for Perception, Prediction, and Planning in Autonomous Driving
May 21, 2025Recent advances have explored integrating large language models (LLMs) into end-to-end autonomous driving systems to enhance generalization and interpretability. However, most existing approaches are limited to either driving performance or vision-language reasoning, making it difficult to achieve both simultaneously. In this paper, we propose ALN-P3, a unified co-distillation framework that introduces cross-modal alignment between "fast" vision-based autonomous driving systems and "slow" language-driven reasoning modules. ALN-P3 incorporates three novel alignment mechanisms: Perception Alignment (P1A), Prediction Alignment (P2A), and Planning Alignment (P3A), which explicitly align visual tokens with corresponding linguistic outputs across the full perception, prediction, and planning stack. All alignment modules are applied only during training and incur no additional costs during inference. Extensive experiments on four challenging benchmarks-nuScenes, Nu-X, TOD3Cap, and nuScenes QA-demonstrate that ALN-P3 significantly improves both driving decisions and language reasoning, achieving state-of-the-art results.
LTDA-Drive: LLMs-guided Generative Models based Long-tail Data Augmentation for Autonomous Driving
May 21, 2025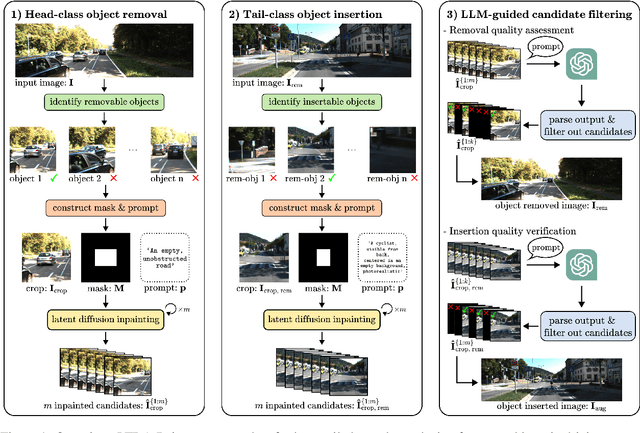
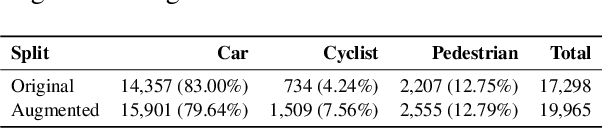

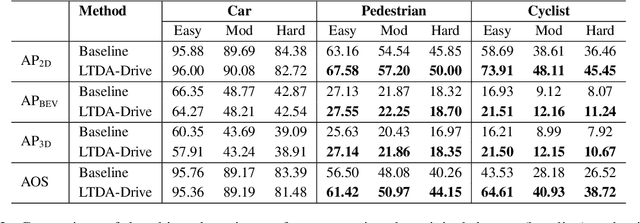
3D perception plays an essential role for improving the safety and performance of autonomous driving. Yet, existing models trained on real-world datasets, which naturally exhibit long-tail distributions, tend to underperform on rare and safety-critical, vulnerable classes, such as pedestrians and cyclists. Existing studies on reweighting and resampling techniques struggle with the scarcity and limited diversity within tail classes. To address these limitations, we introduce LTDA-Drive, a novel LLM-guided data augmentation framework designed to synthesize diverse, high-quality long-tail samples. LTDA-Drive replaces head-class objects in driving scenes with tail-class objects through a three-stage process: (1) text-guided diffusion models remove head-class objects, (2) generative models insert instances of the tail classes, and (3) an LLM agent filters out low-quality synthesized images. Experiments conducted on the KITTI dataset show that LTDA-Drive significantly improves tail-class detection, achieving 34.75\% improvement for rare classes over counterpart methods. These results further highlight the effectiveness of LTDA-Drive in tackling long-tail challenges by generating high-quality and diverse data.
BEVDiffuser: Plug-and-Play Diffusion Model for BEV Denoising with Ground-Truth Guidance
Feb 27, 2025Bird's-eye-view (BEV) representations play a crucial role in autonomous driving tasks. Despite recent advancements in BEV generation, inherent noise, stemming from sensor limitations and the learning process, remains largely unaddressed, resulting in suboptimal BEV representations that adversely impact the performance of downstream tasks. To address this, we propose BEVDiffuser, a novel diffusion model that effectively denoises BEV feature maps using the ground-truth object layout as guidance. BEVDiffuser can be operated in a plug-and-play manner during training time to enhance existing BEV models without requiring any architectural modifications. Extensive experiments on the challenging nuScenes dataset demonstrate BEVDiffuser's exceptional denoising and generation capabilities, which enable significant enhancement to existing BEV models, as evidenced by notable improvements of 12.3\% in mAP and 10.1\% in NDS achieved for 3D object detection without introducing additional computational complexity. Moreover, substantial improvements in long-tail object detection and under challenging weather and lighting conditions further validate BEVDiffuser's effectiveness in denoising and enhancing BEV representations.
MTA: Multimodal Task Alignment for BEV Perception and Captioning
Nov 16, 2024Bird's eye view (BEV)-based 3D perception plays a crucial role in autonomous driving applications. The rise of large language models has spurred interest in BEV-based captioning to understand object behavior in the surrounding environment. However, existing approaches treat perception and captioning as separate tasks, focusing on the performance of only one of the tasks and overlooking the potential benefits of multimodal alignment. To bridge this gap between modalities, we introduce MTA, a novel multimodal task alignment framework that boosts both BEV perception and captioning. MTA consists of two key components: (1) BEV-Language Alignment (BLA), a contextual learning mechanism that aligns the BEV scene representations with ground-truth language representations, and (2) Detection-Captioning Alignment (DCA), a cross-modal prompting mechanism that aligns detection and captioning outputs. MTA integrates into state-of-the-art baselines during training, adding no extra computational complexity at runtime. Extensive experiments on the nuScenes and TOD3Cap datasets show that MTA significantly outperforms state-of-the-art baselines, achieving a 4.9% improvement in perception and a 9.2% improvement in captioning. These results underscore the effectiveness of unified alignment in reconciling BEV-based perception and captioning.
LORD: Large Models based Opposite Reward Design for Autonomous Driving
Mar 27, 2024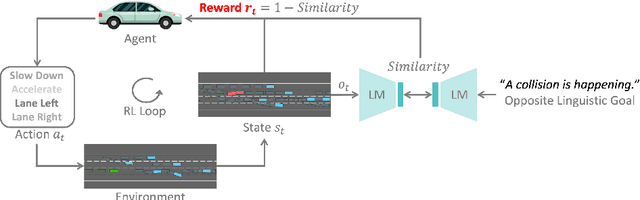



Reinforcement learning (RL) based autonomous driving has emerged as a promising alternative to data-driven imitation learning approaches. However, crafting effective reward functions for RL poses challenges due to the complexity of defining and quantifying good driving behaviors across diverse scenarios. Recently, large pretrained models have gained significant attention as zero-shot reward models for tasks specified with desired linguistic goals. However, the desired linguistic goals for autonomous driving such as "drive safely" are ambiguous and incomprehensible by pretrained models. On the other hand, undesired linguistic goals like "collision" are more concrete and tractable. In this work, we introduce LORD, a novel large models based opposite reward design through undesired linguistic goals to enable the efficient use of large pretrained models as zero-shot reward models. Through extensive experiments, our proposed framework shows its efficiency in leveraging the power of large pretrained models for achieving safe and enhanced autonomous driving. Moreover, the proposed approach shows improved generalization capabilities as it outperforms counterpart methods across diverse and challenging driving scenarios.
PaPr: Training-Free One-Step Patch Pruning with Lightweight ConvNets for Faster Inference
Mar 24, 2024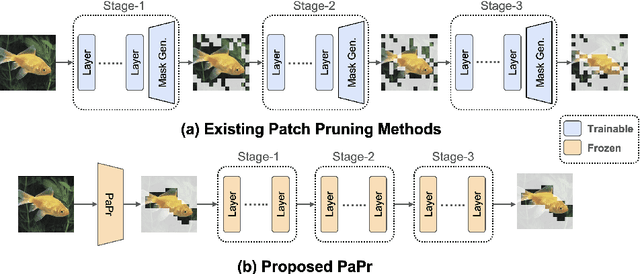
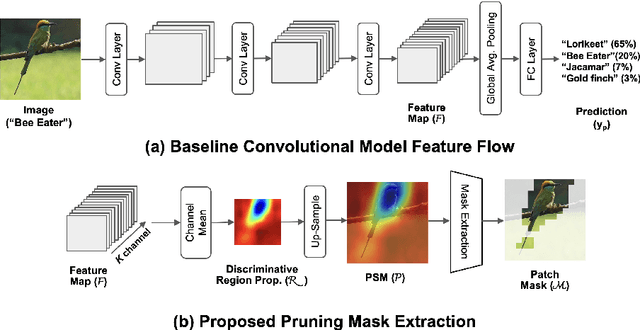
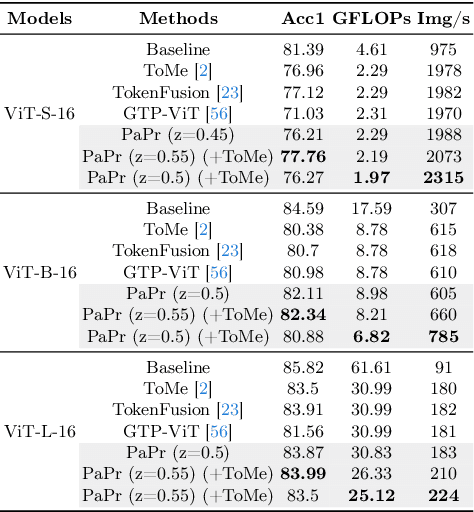
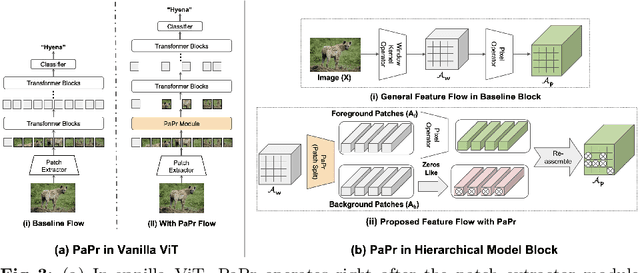
As deep neural networks evolve from convolutional neural networks (ConvNets) to advanced vision transformers (ViTs), there is an increased need to eliminate redundant data for faster processing without compromising accuracy. Previous methods are often architecture-specific or necessitate re-training, restricting their applicability with frequent model updates. To solve this, we first introduce a novel property of lightweight ConvNets: their ability to identify key discriminative patch regions in images, irrespective of model's final accuracy or size. We demonstrate that fully-connected layers are the primary bottleneck for ConvNets performance, and their suppression with simple weight recalibration markedly enhances discriminative patch localization performance. Using this insight, we introduce PaPr, a method for substantially pruning redundant patches with minimal accuracy loss using lightweight ConvNets across a variety of deep learning architectures, including ViTs, ConvNets, and hybrid transformers, without any re-training. Moreover, the simple early-stage one-step patch pruning with PaPr enhances existing patch reduction methods. Through extensive testing on diverse architectures, PaPr achieves significantly higher accuracy over state-of-the-art patch reduction methods with similar FLOP count reduction. More specifically, PaPr reduces about 70% of redundant patches in videos with less than 0.8% drop in accuracy, and up to 3.7x FLOPs reduction, which is a 15% more reduction with 2.5% higher accuracy.
CLIP-BEVFormer: Enhancing Multi-View Image-Based BEV Detector with Ground Truth Flow
Mar 13, 2024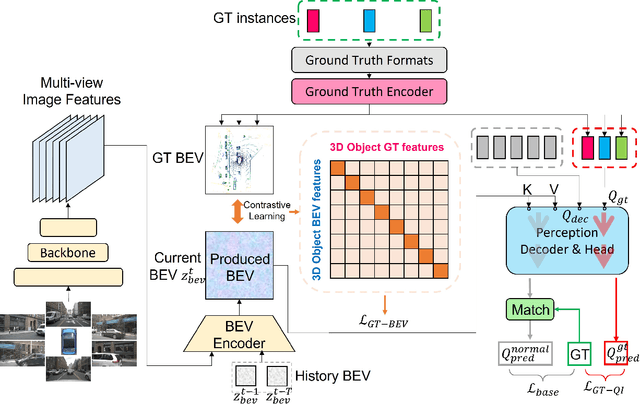
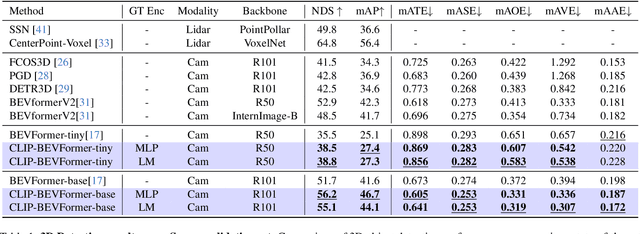
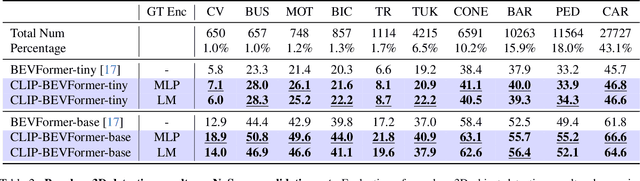

Autonomous driving stands as a pivotal domain in computer vision, shaping the future of transportation. Within this paradigm, the backbone of the system plays a crucial role in interpreting the complex environment. However, a notable challenge has been the loss of clear supervision when it comes to Bird's Eye View elements. To address this limitation, we introduce CLIP-BEVFormer, a novel approach that leverages the power of contrastive learning techniques to enhance the multi-view image-derived BEV backbones with ground truth information flow. We conduct extensive experiments on the challenging nuScenes dataset and showcase significant and consistent improvements over the SOTA. Specifically, CLIP-BEVFormer achieves an impressive 8.5\% and 9.2\% enhancement in terms of NDS and mAP, respectively, over the previous best BEV model on the 3D object detection task.
* CVPR 2024
VLP: Vision Language Planning for Autonomous Driving
Jan 14, 2024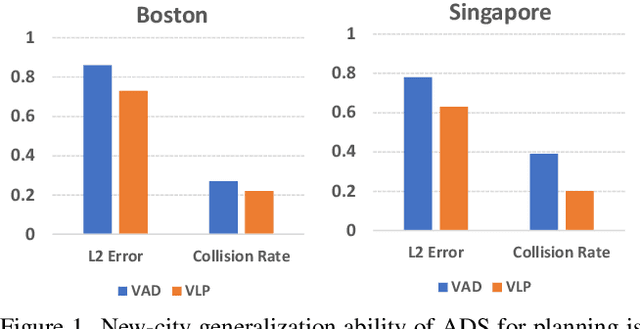
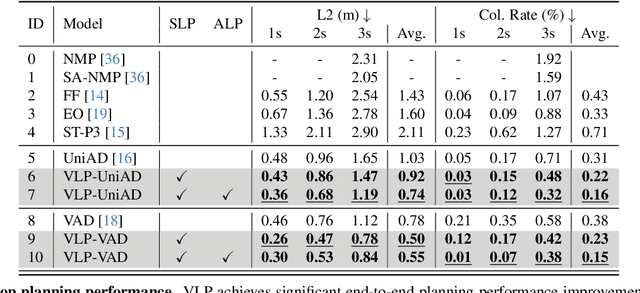


Autonomous driving is a complex and challenging task that aims at safe motion planning through scene understanding and reasoning. While vision-only autonomous driving methods have recently achieved notable performance, through enhanced scene understanding, several key issues, including lack of reasoning, low generalization performance and long-tail scenarios, still need to be addressed. In this paper, we present VLP, a novel Vision-Language-Planning framework that exploits language models to bridge the gap between linguistic understanding and autonomous driving. VLP enhances autonomous driving systems by strengthening both the source memory foundation and the self-driving car's contextual understanding. VLP achieves state-of-the-art end-to-end planning performance on the challenging NuScenes dataset by achieving 35.9\% and 60.5\% reduction in terms of average L2 error and collision rates, respectively, compared to the previous best method. Moreover, VLP shows improved performance in challenging long-tail scenarios and strong generalization capabilities when faced with new urban environments.
Deep Double Descent for Time Series Forecasting: Avoiding Undertrained Models
Nov 07, 2023Deep learning models, particularly Transformers, have achieved impressive results in various domains, including time series forecasting. While existing time series literature primarily focuses on model architecture modifications and data augmentation techniques, this paper explores the training schema of deep learning models for time series; how models are trained regardless of their architecture. We perform extensive experiments to investigate the occurrence of deep double descent in several Transformer models trained on public time series data sets. We demonstrate epoch-wise deep double descent and that overfitting can be reverted using more epochs. Leveraging these findings, we achieve state-of-the-art results for long sequence time series forecasting in nearly 70% of the 72 benchmarks tested. This suggests that many models in the literature may possess untapped potential. Additionally, we introduce a taxonomy for classifying training schema modifications, covering data augmentation, model inputs, model targets, time series per model, and computational budget.
SSVOD: Semi-Supervised Video Object Detection with Sparse Annotations
Sep 04, 2023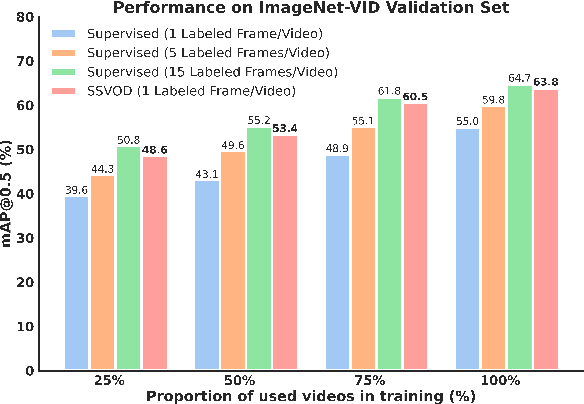
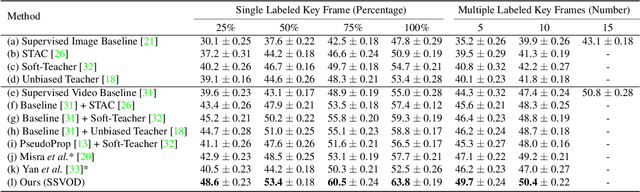
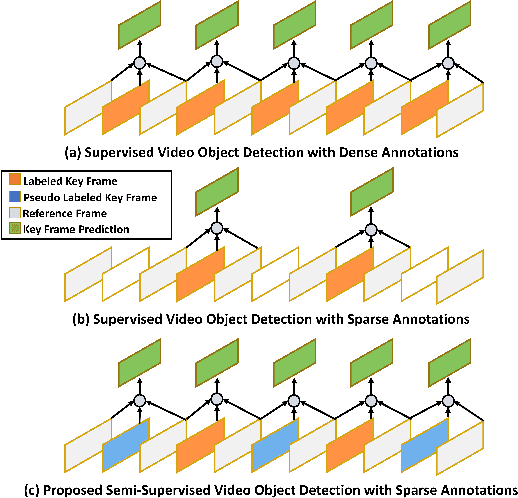
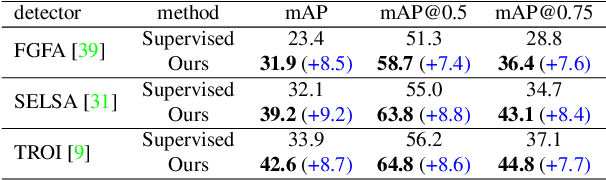
Despite significant progress in semi-supervised learning for image object detection, several key issues are yet to be addressed for video object detection: (1) Achieving good performance for supervised video object detection greatly depends on the availability of annotated frames. (2) Despite having large inter-frame correlations in a video, collecting annotations for a large number of frames per video is expensive, time-consuming, and often redundant. (3) Existing semi-supervised techniques on static images can hardly exploit the temporal motion dynamics inherently present in videos. In this paper, we introduce SSVOD, an end-to-end semi-supervised video object detection framework that exploits motion dynamics of videos to utilize large-scale unlabeled frames with sparse annotations. To selectively assemble robust pseudo-labels across groups of frames, we introduce \textit{flow-warped predictions} from nearby frames for temporal-consistency estimation. In particular, we introduce cross-IoU and cross-divergence based selection methods over a set of estimated predictions to include robust pseudo-labels for bounding boxes and class labels, respectively. To strike a balance between confirmation bias and uncertainty noise in pseudo-labels, we propose confidence threshold based combination of hard and soft pseudo-labels. Our method achieves significant performance improvements over existing methods on ImageNet-VID, Epic-KITCHENS, and YouTube-VIS datasets. Code and pre-trained models will be released.