 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDINO-R1: Incentivizing Reasoning Capability in Vision Foundation Models
May 29, 2025



The recent explosive interest in the reasoning capabilities of large language models, such as DeepSeek-R1, has demonstrated remarkable success through reinforcement learning-based fine-tuning frameworks, exemplified by methods like Group Relative Policy Optimization (GRPO). However, such reasoning abilities remain underexplored and notably absent in vision foundation models, including representation models like the DINO series. In this work, we propose \textbf{DINO-R1}, the first such attempt to incentivize visual in-context reasoning capabilities of vision foundation models using reinforcement learning. Specifically, DINO-R1 introduces \textbf{Group Relative Query Optimization (GRQO)}, a novel reinforcement-style training strategy explicitly designed for query-based representation models, which computes query-level rewards based on group-normalized alignment quality. We also apply KL-regularization to stabilize the objectness distribution to reduce the training instability. This joint optimization enables dense and expressive supervision across queries while mitigating overfitting and distributional drift. Building upon Grounding-DINO, we train a series of DINO-R1 family models that integrate a visual prompt encoder and a visual-guided query selection mechanism. Extensive experiments on COCO, LVIS, and ODinW demonstrate that DINO-R1 significantly outperforms supervised fine-tuning baselines, achieving strong generalization in both open-vocabulary and closed-set visual prompting scenarios.
CLIP-BEVFormer: Enhancing Multi-View Image-Based BEV Detector with Ground Truth Flow
Mar 13, 2024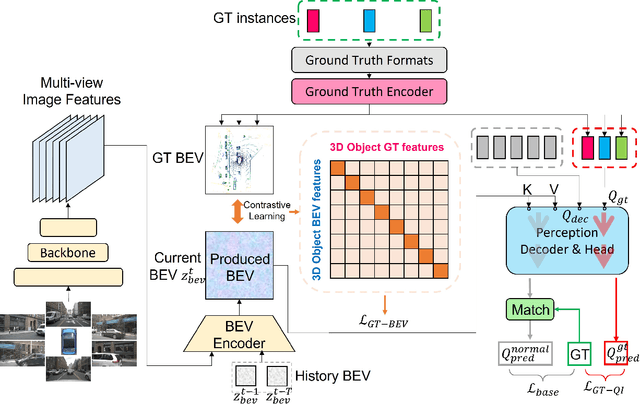
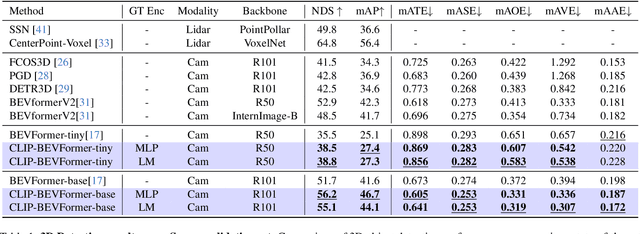
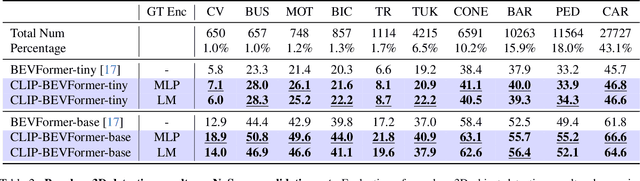

Autonomous driving stands as a pivotal domain in computer vision, shaping the future of transportation. Within this paradigm, the backbone of the system plays a crucial role in interpreting the complex environment. However, a notable challenge has been the loss of clear supervision when it comes to Bird's Eye View elements. To address this limitation, we introduce CLIP-BEVFormer, a novel approach that leverages the power of contrastive learning techniques to enhance the multi-view image-derived BEV backbones with ground truth information flow. We conduct extensive experiments on the challenging nuScenes dataset and showcase significant and consistent improvements over the SOTA. Specifically, CLIP-BEVFormer achieves an impressive 8.5\% and 9.2\% enhancement in terms of NDS and mAP, respectively, over the previous best BEV model on the 3D object detection task.
* CVPR 2024
VLP: Vision Language Planning for Autonomous Driving
Jan 14, 2024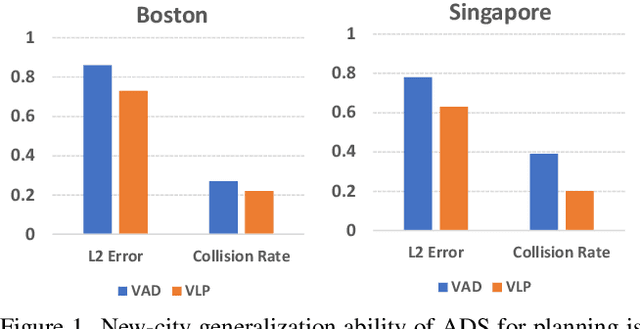
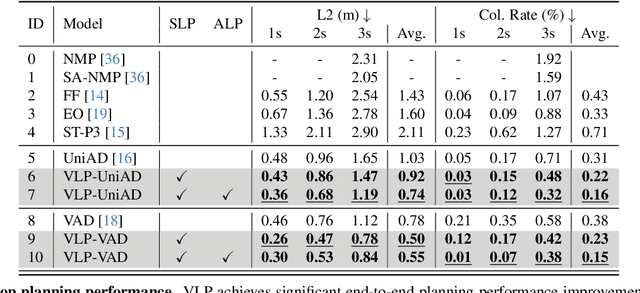


Autonomous driving is a complex and challenging task that aims at safe motion planning through scene understanding and reasoning. While vision-only autonomous driving methods have recently achieved notable performance, through enhanced scene understanding, several key issues, including lack of reasoning, low generalization performance and long-tail scenarios, still need to be addressed. In this paper, we present VLP, a novel Vision-Language-Planning framework that exploits language models to bridge the gap between linguistic understanding and autonomous driving. VLP enhances autonomous driving systems by strengthening both the source memory foundation and the self-driving car's contextual understanding. VLP achieves state-of-the-art end-to-end planning performance on the challenging NuScenes dataset by achieving 35.9\% and 60.5\% reduction in terms of average L2 error and collision rates, respectively, compared to the previous best method. Moreover, VLP shows improved performance in challenging long-tail scenarios and strong generalization capabilities when faced with new urban environments.
SVT: Supertoken Video Transformer for Efficient Video Understanding
Apr 23, 2023



Whether by processing videos with fixed resolution from start to end or incorporating pooling and down-scaling strategies, existing video transformers process the whole video content throughout the network without specially handling the large portions of redundant information. In this paper, we present a Supertoken Video Transformer (SVT) that incorporates a Semantic Pooling Module (SPM) to aggregate latent representations along the depth of visual transformer based on their semantics, and thus, reduces redundancy inherent in video inputs.~Qualitative results show that our method can effectively reduce redundancy by merging latent representations with similar semantics and thus increase the proportion of salient information for downstream tasks.~Quantitatively, our method improves the performance of both ViT and MViT while requiring significantly less computations on the Kinectics and Something-Something-V2 benchmarks.~More specifically, with our SPM, we improve the accuracy of MAE-pretrained ViT-B and ViT-L by 1.5% with 33% less GFLOPs and by 0.2% with 55% less FLOPs, respectively, on the Kinectics-400 benchmark, and improve the accuracy of MViTv2-B by 0.2% and 0.3% with 22% less GFLOPs on Kinectics-400 and Something-Something-V2, respectively.
EgoViT: Pyramid Video Transformer for Egocentric Action Recognition
Mar 15, 2023



Capturing interaction of hands with objects is important to autonomously detect human actions from egocentric videos. In this work, we present a pyramid video transformer with a dynamic class token generator for egocentric action recognition. Different from previous video transformers, which use the same static embedding as the class token for diverse inputs, we propose a dynamic class token generator that produces a class token for each input video by analyzing the hand-object interaction and the related motion information. The dynamic class token can diffuse such information to the entire model by communicating with other informative tokens in the subsequent transformer layers. With the dynamic class token, dissimilarity between videos can be more prominent, which helps the model distinguish various inputs. In addition, traditional video transformers explore temporal features globally, which requires large amounts of computation. However, egocentric videos often have a large amount of background scene transition, which causes discontinuities across distant frames. In this case, blindly reducing the temporal sampling rate will risk losing crucial information. Hence, we also propose a pyramid architecture to hierarchically process the video from short-term high rate to long-term low rate. With the proposed architecture, we significantly reduce the computational cost as well as the memory requirement without sacrificing from the model performance. We perform comparisons with different baseline video transformers on the EPIC-KITCHENS-100 and EGTEA Gaze+ datasets. Both quantitative and qualitative results show that the proposed model can efficiently improve the performance for egocentric action recognition.