 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLTDA-Drive: LLMs-guided Generative Models based Long-tail Data Augmentation for Autonomous Driving
May 21, 2025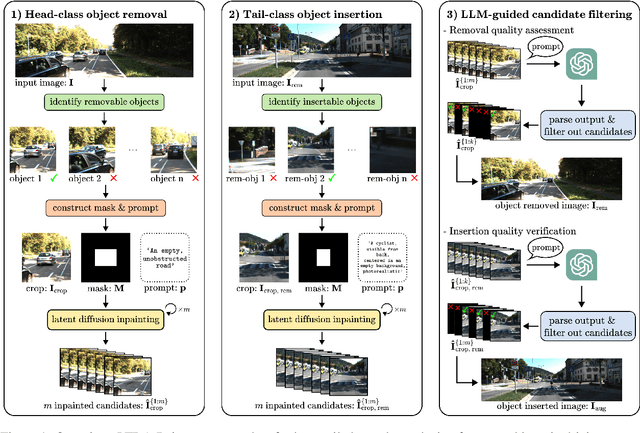
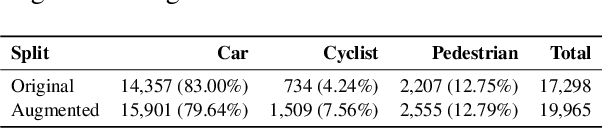

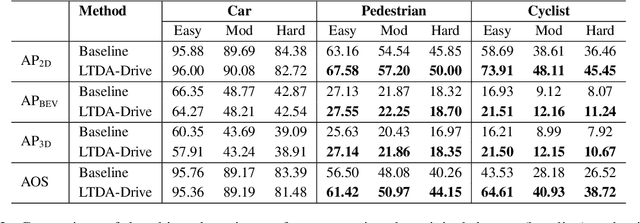
3D perception plays an essential role for improving the safety and performance of autonomous driving. Yet, existing models trained on real-world datasets, which naturally exhibit long-tail distributions, tend to underperform on rare and safety-critical, vulnerable classes, such as pedestrians and cyclists. Existing studies on reweighting and resampling techniques struggle with the scarcity and limited diversity within tail classes. To address these limitations, we introduce LTDA-Drive, a novel LLM-guided data augmentation framework designed to synthesize diverse, high-quality long-tail samples. LTDA-Drive replaces head-class objects in driving scenes with tail-class objects through a three-stage process: (1) text-guided diffusion models remove head-class objects, (2) generative models insert instances of the tail classes, and (3) an LLM agent filters out low-quality synthesized images. Experiments conducted on the KITTI dataset show that LTDA-Drive significantly improves tail-class detection, achieving 34.75\% improvement for rare classes over counterpart methods. These results further highlight the effectiveness of LTDA-Drive in tackling long-tail challenges by generating high-quality and diverse data.
ALN-P3: Unified Language Alignment for Perception, Prediction, and Planning in Autonomous Driving
May 21, 2025Recent advances have explored integrating large language models (LLMs) into end-to-end autonomous driving systems to enhance generalization and interpretability. However, most existing approaches are limited to either driving performance or vision-language reasoning, making it difficult to achieve both simultaneously. In this paper, we propose ALN-P3, a unified co-distillation framework that introduces cross-modal alignment between "fast" vision-based autonomous driving systems and "slow" language-driven reasoning modules. ALN-P3 incorporates three novel alignment mechanisms: Perception Alignment (P1A), Prediction Alignment (P2A), and Planning Alignment (P3A), which explicitly align visual tokens with corresponding linguistic outputs across the full perception, prediction, and planning stack. All alignment modules are applied only during training and incur no additional costs during inference. Extensive experiments on four challenging benchmarks-nuScenes, Nu-X, TOD3Cap, and nuScenes QA-demonstrate that ALN-P3 significantly improves both driving decisions and language reasoning, achieving state-of-the-art results.
BEVDiffuser: Plug-and-Play Diffusion Model for BEV Denoising with Ground-Truth Guidance
Feb 27, 2025Bird's-eye-view (BEV) representations play a crucial role in autonomous driving tasks. Despite recent advancements in BEV generation, inherent noise, stemming from sensor limitations and the learning process, remains largely unaddressed, resulting in suboptimal BEV representations that adversely impact the performance of downstream tasks. To address this, we propose BEVDiffuser, a novel diffusion model that effectively denoises BEV feature maps using the ground-truth object layout as guidance. BEVDiffuser can be operated in a plug-and-play manner during training time to enhance existing BEV models without requiring any architectural modifications. Extensive experiments on the challenging nuScenes dataset demonstrate BEVDiffuser's exceptional denoising and generation capabilities, which enable significant enhancement to existing BEV models, as evidenced by notable improvements of 12.3\% in mAP and 10.1\% in NDS achieved for 3D object detection without introducing additional computational complexity. Moreover, substantial improvements in long-tail object detection and under challenging weather and lighting conditions further validate BEVDiffuser's effectiveness in denoising and enhancing BEV representations.
MTA: Multimodal Task Alignment for BEV Perception and Captioning
Nov 16, 2024Bird's eye view (BEV)-based 3D perception plays a crucial role in autonomous driving applications. The rise of large language models has spurred interest in BEV-based captioning to understand object behavior in the surrounding environment. However, existing approaches treat perception and captioning as separate tasks, focusing on the performance of only one of the tasks and overlooking the potential benefits of multimodal alignment. To bridge this gap between modalities, we introduce MTA, a novel multimodal task alignment framework that boosts both BEV perception and captioning. MTA consists of two key components: (1) BEV-Language Alignment (BLA), a contextual learning mechanism that aligns the BEV scene representations with ground-truth language representations, and (2) Detection-Captioning Alignment (DCA), a cross-modal prompting mechanism that aligns detection and captioning outputs. MTA integrates into state-of-the-art baselines during training, adding no extra computational complexity at runtime. Extensive experiments on the nuScenes and TOD3Cap datasets show that MTA significantly outperforms state-of-the-art baselines, achieving a 4.9% improvement in perception and a 9.2% improvement in captioning. These results underscore the effectiveness of unified alignment in reconciling BEV-based perception and captioning.
LORD: Large Models based Opposite Reward Design for Autonomous Driving
Mar 27, 2024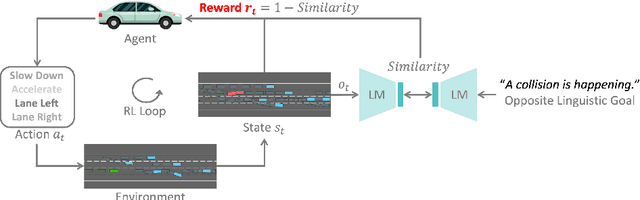



Reinforcement learning (RL) based autonomous driving has emerged as a promising alternative to data-driven imitation learning approaches. However, crafting effective reward functions for RL poses challenges due to the complexity of defining and quantifying good driving behaviors across diverse scenarios. Recently, large pretrained models have gained significant attention as zero-shot reward models for tasks specified with desired linguistic goals. However, the desired linguistic goals for autonomous driving such as "drive safely" are ambiguous and incomprehensible by pretrained models. On the other hand, undesired linguistic goals like "collision" are more concrete and tractable. In this work, we introduce LORD, a novel large models based opposite reward design through undesired linguistic goals to enable the efficient use of large pretrained models as zero-shot reward models. Through extensive experiments, our proposed framework shows its efficiency in leveraging the power of large pretrained models for achieving safe and enhanced autonomous driving. Moreover, the proposed approach shows improved generalization capabilities as it outperforms counterpart methods across diverse and challenging driving scenarios.
VLP: Vision Language Planning for Autonomous Driving
Jan 14, 2024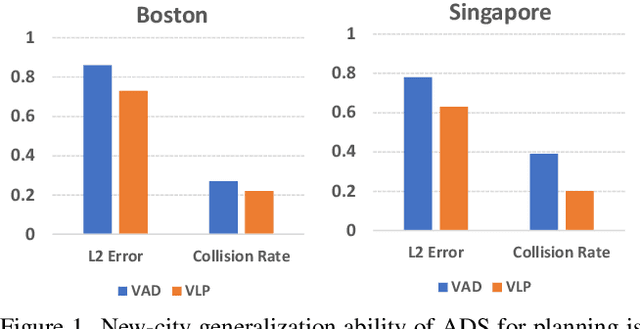
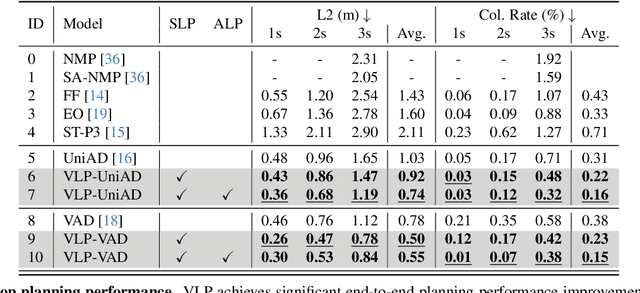


Autonomous driving is a complex and challenging task that aims at safe motion planning through scene understanding and reasoning. While vision-only autonomous driving methods have recently achieved notable performance, through enhanced scene understanding, several key issues, including lack of reasoning, low generalization performance and long-tail scenarios, still need to be addressed. In this paper, we present VLP, a novel Vision-Language-Planning framework that exploits language models to bridge the gap between linguistic understanding and autonomous driving. VLP enhances autonomous driving systems by strengthening both the source memory foundation and the self-driving car's contextual understanding. VLP achieves state-of-the-art end-to-end planning performance on the challenging NuScenes dataset by achieving 35.9\% and 60.5\% reduction in terms of average L2 error and collision rates, respectively, compared to the previous best method. Moreover, VLP shows improved performance in challenging long-tail scenarios and strong generalization capabilities when faced with new urban environments.