 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Reinforcement Learning for Path Planning in Constrained Parking Scenarios
Jan 30, 2026Real-time path planning in constrained environments remains a fundamental challenge for autonomous systems. Traditional classical planners, while effective under perfect perception assumptions, are often sensitive to real-world perception constraints and rely on online search procedures that incur high computational costs. In complex surroundings, this renders real-time deployment prohibitive. To overcome these limitations, we introduce a Deep Reinforcement Learning (DRL) framework for real-time path planning in parking scenarios. In particular, we focus on challenging scenes with tight spaces that require a high number of reversal maneuvers and adjustments. Unlike classical planners, our solution does not require ideal and structured perception, and in principle, could avoid the need for additional modules such as localization and tracking, resulting in a simpler and more practical implementation. Also, at test time, the policy generates actions through a single forward pass at each step, which is lightweight enough for real-time deployment. The task is formulated as a sequential decision-making problem grounded in a bicycle model dynamics, enabling the agent to directly learn navigation policies that respect vehicle kinematics and environmental constraints in the closed-loop setting. A new benchmark is developed to support both training and evaluation, capturing diverse and challenging scenarios. Our approach achieves state-of-the-art success rates and efficiency, surpassing classical planner baselines by +96% in success rate and +52% in efficiency. Furthermore, we release our benchmark as an open-source resource for the community to foster future research in autonomous systems. The benchmark and accompanying tools are available at https://github.com/dqm5rtfg9b-collab/Constrained_Parking_Scenarios.
Advanced long-term earth system forecasting by learning the small-scale nature
May 26, 2025Reliable long-term forecast of Earth system dynamics is heavily hampered by instabilities in current AI models during extended autoregressive simulations. These failures often originate from inherent spectral bias, leading to inadequate representation of critical high-frequency, small-scale processes and subsequent uncontrolled error amplification. We present Triton, an AI framework designed to address this fundamental challenge. Inspired by increasing grids to explicitly resolve small scales in numerical models, Triton employs a hierarchical architecture processing information across multiple resolutions to mitigate spectral bias and explicitly model cross-scale dynamics. We demonstrate Triton's superior performance on challenging forecast tasks, achieving stable year-long global temperature forecasts, skillful Kuroshio eddy predictions till 120 days, and high-fidelity turbulence simulations preserving fine-scale structures all without external forcing, with significantly surpassing baseline AI models in long-term stability and accuracy. By effectively suppressing high-frequency error accumulation, Triton offers a promising pathway towards trustworthy AI-driven simulation for climate and earth system science.
BEVDiffuser: Plug-and-Play Diffusion Model for BEV Denoising with Ground-Truth Guidance
Feb 27, 2025Bird's-eye-view (BEV) representations play a crucial role in autonomous driving tasks. Despite recent advancements in BEV generation, inherent noise, stemming from sensor limitations and the learning process, remains largely unaddressed, resulting in suboptimal BEV representations that adversely impact the performance of downstream tasks. To address this, we propose BEVDiffuser, a novel diffusion model that effectively denoises BEV feature maps using the ground-truth object layout as guidance. BEVDiffuser can be operated in a plug-and-play manner during training time to enhance existing BEV models without requiring any architectural modifications. Extensive experiments on the challenging nuScenes dataset demonstrate BEVDiffuser's exceptional denoising and generation capabilities, which enable significant enhancement to existing BEV models, as evidenced by notable improvements of 12.3\% in mAP and 10.1\% in NDS achieved for 3D object detection without introducing additional computational complexity. Moreover, substantial improvements in long-tail object detection and under challenging weather and lighting conditions further validate BEVDiffuser's effectiveness in denoising and enhancing BEV representations.
MTA: Multimodal Task Alignment for BEV Perception and Captioning
Nov 16, 2024Bird's eye view (BEV)-based 3D perception plays a crucial role in autonomous driving applications. The rise of large language models has spurred interest in BEV-based captioning to understand object behavior in the surrounding environment. However, existing approaches treat perception and captioning as separate tasks, focusing on the performance of only one of the tasks and overlooking the potential benefits of multimodal alignment. To bridge this gap between modalities, we introduce MTA, a novel multimodal task alignment framework that boosts both BEV perception and captioning. MTA consists of two key components: (1) BEV-Language Alignment (BLA), a contextual learning mechanism that aligns the BEV scene representations with ground-truth language representations, and (2) Detection-Captioning Alignment (DCA), a cross-modal prompting mechanism that aligns detection and captioning outputs. MTA integrates into state-of-the-art baselines during training, adding no extra computational complexity at runtime. Extensive experiments on the nuScenes and TOD3Cap datasets show that MTA significantly outperforms state-of-the-art baselines, achieving a 4.9% improvement in perception and a 9.2% improvement in captioning. These results underscore the effectiveness of unified alignment in reconciling BEV-based perception and captioning.
VCBench: A Controllable Benchmark for Symbolic and Abstract Challenges in Video Cognition
Nov 14, 2024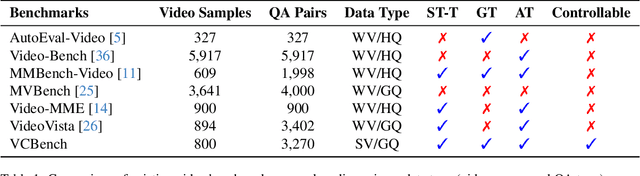
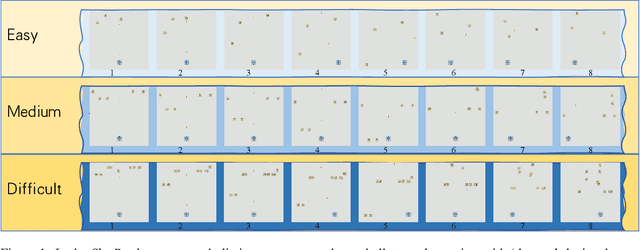
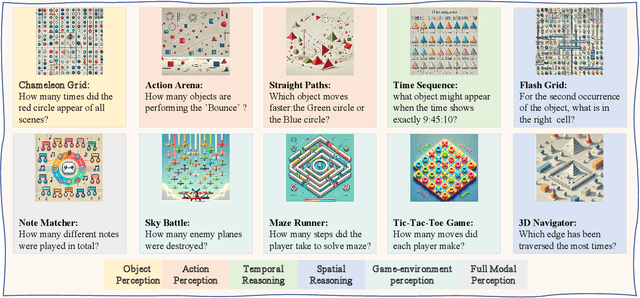
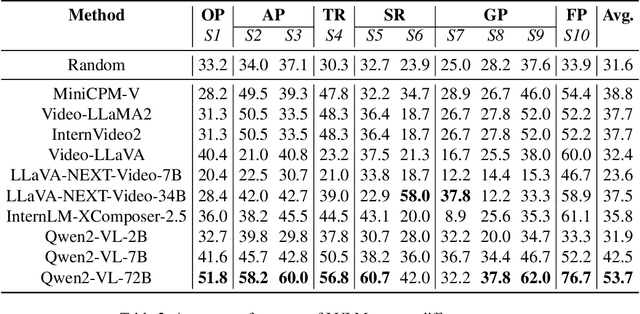
Recent advancements in Large Video-Language Models (LVLMs) have driven the development of benchmarks designed to assess cognitive abilities in video-based tasks. However, most existing benchmarks heavily rely on web-collected videos paired with human annotations or model-generated questions, which limit control over the video content and fall short in evaluating advanced cognitive abilities involving symbolic elements and abstract concepts. To address these limitations, we introduce VCBench, a controllable benchmark to assess LVLMs' cognitive abilities, involving symbolic and abstract concepts at varying difficulty levels. By generating video data with the Python-based engine, VCBench allows for precise control over the video content, creating dynamic, task-oriented videos that feature complex scenes and abstract concepts. Each task pairs with tailored question templates that target specific cognitive challenges, providing a rigorous evaluation test. Our evaluation reveals that even state-of-the-art (SOTA) models, such as Qwen2-VL-72B, struggle with simple video cognition tasks involving abstract concepts, with performance sharply dropping by 19% as video complexity rises. These findings reveal the current limitations of LVLMs in advanced cognitive tasks and highlight the critical role of VCBench in driving research toward more robust LVLMs for complex video cognition challenges.
Optimizing Instruction Synthesis: Effective Exploration of Evolutionary Space with Tree Search
Oct 14, 2024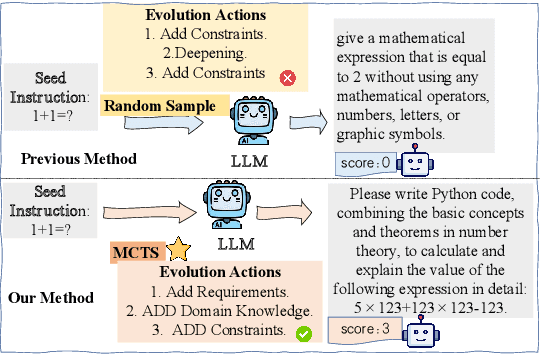
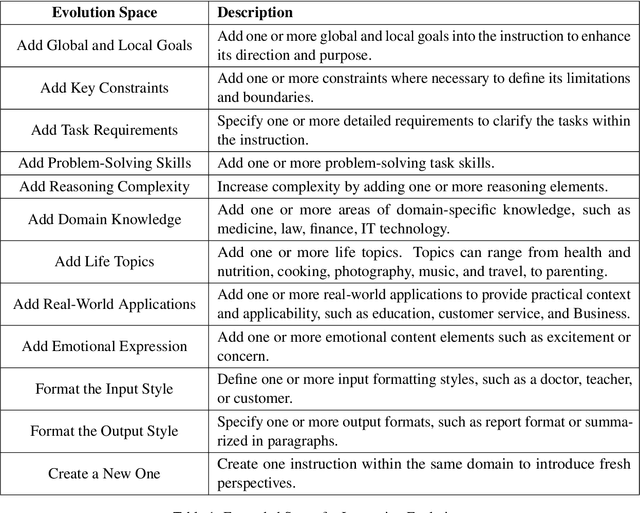

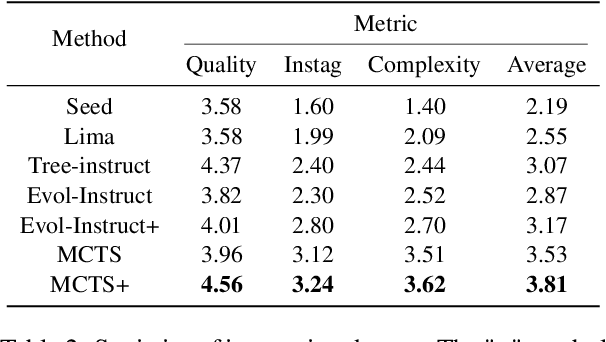
Instruction tuning is a crucial technique for aligning language models with humans' actual goals in the real world. Extensive research has highlighted the quality of instruction data is essential for the success of this alignment. However, creating high-quality data manually is labor-intensive and time-consuming, which leads researchers to explore using LLMs to synthesize data. Recent studies have focused on using a stronger LLM to iteratively enhance existing instruction data, showing promising results. Nevertheless, previous work often lacks control over the evolution direction, resulting in high uncertainty in the data synthesis process and low-quality instructions. In this paper, we introduce a general and scalable framework, IDEA-MCTS (Instruction Data Enhancement using Monte Carlo Tree Search), a scalable framework for efficiently synthesizing instructions. With tree search and evaluation models, it can efficiently guide each instruction to evolve into a high-quality form, aiding in instruction fine-tuning. Experimental results show that IDEA-MCTS significantly enhances the seed instruction data, raising the average evaluation scores of quality, diversity, and complexity from 2.19 to 3.81. Furthermore, in open-domain benchmarks, experimental results show that IDEA-MCTS improves the accuracy of real-world instruction-following skills in LLMs by an average of 5\% in low-resource settings.
LORD: Large Models based Opposite Reward Design for Autonomous Driving
Mar 27, 2024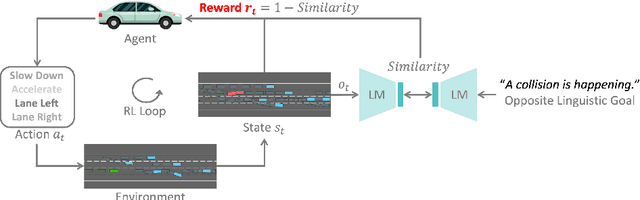



Reinforcement learning (RL) based autonomous driving has emerged as a promising alternative to data-driven imitation learning approaches. However, crafting effective reward functions for RL poses challenges due to the complexity of defining and quantifying good driving behaviors across diverse scenarios. Recently, large pretrained models have gained significant attention as zero-shot reward models for tasks specified with desired linguistic goals. However, the desired linguistic goals for autonomous driving such as "drive safely" are ambiguous and incomprehensible by pretrained models. On the other hand, undesired linguistic goals like "collision" are more concrete and tractable. In this work, we introduce LORD, a novel large models based opposite reward design through undesired linguistic goals to enable the efficient use of large pretrained models as zero-shot reward models. Through extensive experiments, our proposed framework shows its efficiency in leveraging the power of large pretrained models for achieving safe and enhanced autonomous driving. Moreover, the proposed approach shows improved generalization capabilities as it outperforms counterpart methods across diverse and challenging driving scenarios.
F2BEV: Bird's Eye View Generation from Surround-View Fisheye Camera Images for Automated Driving
Mar 07, 2023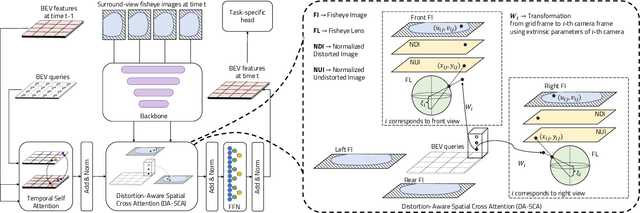



Bird's Eye View (BEV) representations are tremendously useful for perception-related automated driving tasks. However, generating BEVs from surround-view fisheye camera images is challenging due to the strong distortions introduced by such wide-angle lenses. We take the first step in addressing this challenge and introduce a baseline, F2BEV, to generate BEV height maps and semantic segmentation maps from fisheye images. F2BEV consists of a distortion-aware spatial cross attention module for querying and consolidating spatial information from fisheye image features in a transformer-style architecture followed by a task-specific head. We evaluate single-task and multi-task variants of F2BEV on our synthetic FB-SSEM dataset, all of which generate better BEV height and segmentation maps (in terms of the IoU) than a state-of-the-art BEV generation method operating on undistorted fisheye images. We also demonstrate height map generation from real-world fisheye images using F2BEV. An initial sample of our dataset is publicly available at https://tinyurl.com/58jvnscy
DG-Labeler and DGL-MOTS Dataset: Boost the Autonomous Driving Perception
Oct 15, 2021
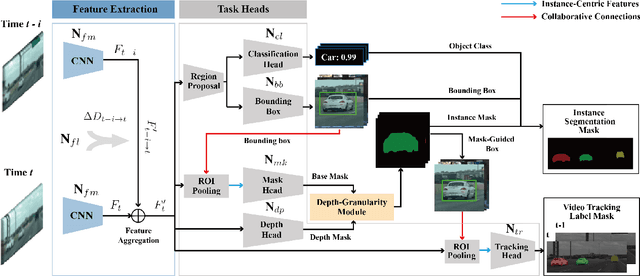
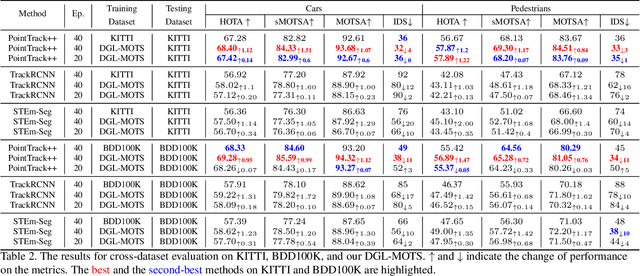
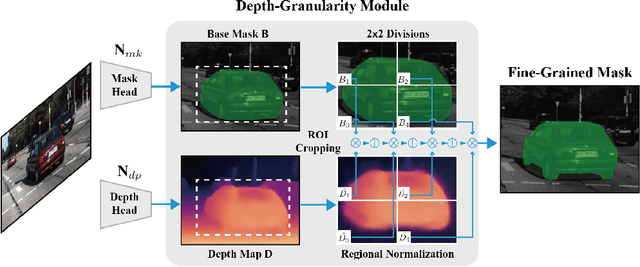
Multi-object tracking and segmentation (MOTS) is a critical task for autonomous driving applications. The existing MOTS studies face two critical challenges: 1) the published datasets inadequately capture the real-world complexity for network training to address various driving settings; 2) the working pipeline annotation tool is under-studied in the literature to improve the quality of MOTS learning examples. In this work, we introduce the DG-Labeler and DGL-MOTS dataset to facilitate the training data annotation for the MOTS task and accordingly improve network training accuracy and efficiency. DG-Labeler uses the novel Depth-Granularity Module to depict the instance spatial relations and produce fine-grained instance masks. Annotated by DG-Labeler, our DGL-MOTS dataset exceeds the prior effort (i.e., KITTI MOTS and BDD100K) in data diversity, annotation quality, and temporal representations. Results on extensive cross-dataset evaluations indicate significant performance improvements for several state-of-the-art methods trained on our DGL-MOTS dataset. We believe our DGL-MOTS Dataset and DG-Labeler hold the valuable potential to boost the visual perception of future transportation.
Human-guided Robot Behavior Learning: A GAN-assisted Preference-based Reinforcement Learning Approach
Oct 15, 2020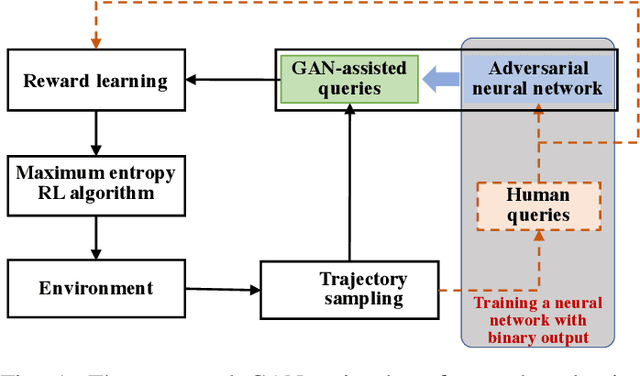
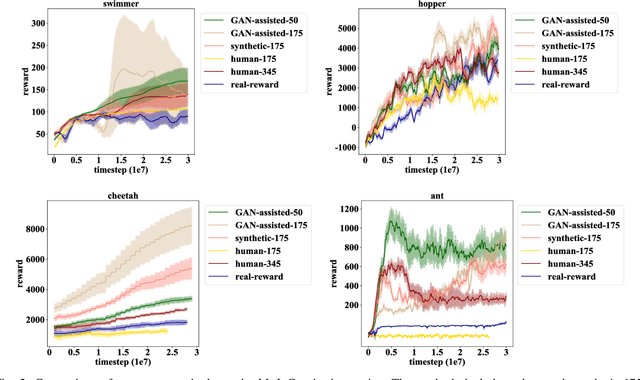
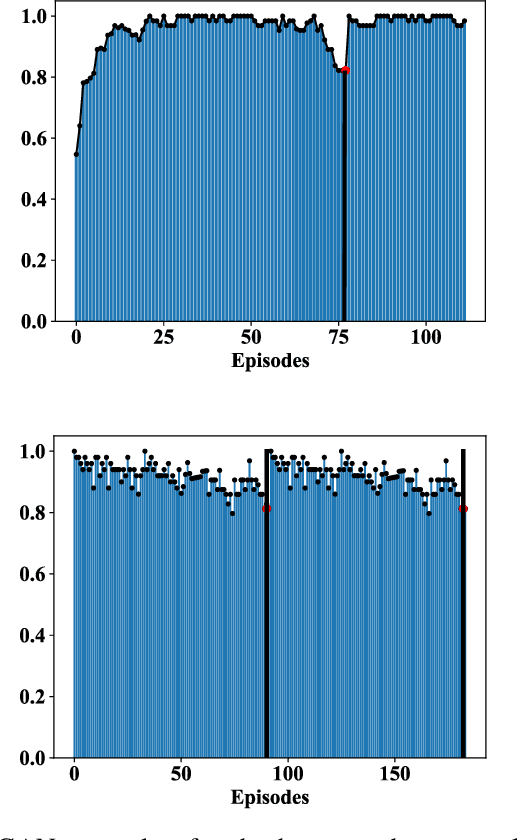
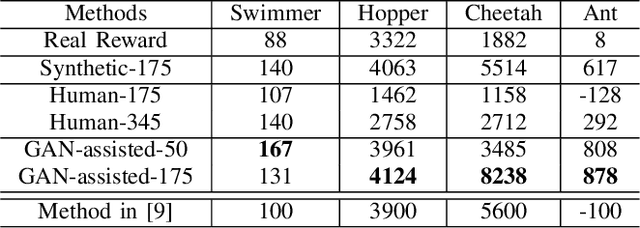
Human demonstrations can provide trustful samples to train reinforcement learning algorithms for robots to learn complex behaviors in real-world environments. However, obtaining sufficient demonstrations may be impractical because many behaviors are difficult for humans to demonstrate. A more practical approach is to replace human demonstrations by human queries, i.e., preference-based reinforcement learning. One key limitation of the existing algorithms is the need for a significant amount of human queries because a large number of labeled data is needed to train neural networks for the approximation of a continuous, high-dimensional reward function. To reduce and minimize the need for human queries, we propose a new GAN-assisted human preference-based reinforcement learning approach that uses a generative adversarial network (GAN) to actively learn human preferences and then replace the role of human in assigning preferences. The adversarial neural network is simple and only has a binary output, hence requiring much less human queries to train. Moreover, a maximum entropy based reinforcement learning algorithm is designed to shape the loss towards the desired regions or away from the undesired regions. To show the effectiveness of the proposed approach, we present some studies on complex robotic tasks without access to the environment reward in a typical MuJoCo robot locomotion environment. The obtained results show our method can achieve a reduction of about 99.8% human time without performance sacrifice.