 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMERGE: Next-Generation Item Indexing Paradigm for Large-Scale Streaming Recommendation
Jan 28, 2026Item indexing, which maps a large corpus of items into compact discrete representations, is critical for both discriminative and generative recommender systems, yet existing Vector Quantization (VQ)-based approaches struggle with the highly skewed and non-stationary item distributions common in streaming industry recommenders, leading to poor assignment accuracy, imbalanced cluster occupancy, and insufficient cluster separation. To address these challenges, we propose MERGE, a next-generation item indexing paradigm that adaptively constructs clusters from scratch, dynamically monitors cluster occupancy, and forms hierarchical index structures via fine-to-coarse merging. Extensive experiments demonstrate that MERGE significantly improves assignment accuracy, cluster uniformity, and cluster separation compared with existing indexing methods, while online A/B tests show substantial gains in key business metrics, highlighting its potential as a foundational indexing approach for large-scale recommendation.
Uncertainty Matters in Dynamic Gaussian Splatting for Monocular 4D Reconstruction
Oct 14, 2025Reconstructing dynamic 3D scenes from monocular input is fundamentally under-constrained, with ambiguities arising from occlusion and extreme novel views. While dynamic Gaussian Splatting offers an efficient representation, vanilla models optimize all Gaussian primitives uniformly, ignoring whether they are well or poorly observed. This limitation leads to motion drifts under occlusion and degraded synthesis when extrapolating to unseen views. We argue that uncertainty matters: Gaussians with recurring observations across views and time act as reliable anchors to guide motion, whereas those with limited visibility are treated as less reliable. To this end, we introduce USplat4D, a novel Uncertainty-aware dynamic Gaussian Splatting framework that propagates reliable motion cues to enhance 4D reconstruction. Our key insight is to estimate time-varying per-Gaussian uncertainty and leverages it to construct a spatio-temporal graph for uncertainty-aware optimization. Experiments on diverse real and synthetic datasets show that explicitly modeling uncertainty consistently improves dynamic Gaussian Splatting models, yielding more stable geometry under occlusion and high-quality synthesis at extreme viewpoints.
AutoVDC: Automated Vision Data Cleaning Using Vision-Language Models
Jul 16, 2025Training of autonomous driving systems requires extensive datasets with precise annotations to attain robust performance. Human annotations suffer from imperfections, and multiple iterations are often needed to produce high-quality datasets. However, manually reviewing large datasets is laborious and expensive. In this paper, we introduce AutoVDC (Automated Vision Data Cleaning) framework and investigate the utilization of Vision-Language Models (VLMs) to automatically identify erroneous annotations in vision datasets, thereby enabling users to eliminate these errors and enhance data quality. We validate our approach using the KITTI and nuImages datasets, which contain object detection benchmarks for autonomous driving. To test the effectiveness of AutoVDC, we create dataset variants with intentionally injected erroneous annotations and observe the error detection rate of our approach. Additionally, we compare the detection rates using different VLMs and explore the impact of VLM fine-tuning on our pipeline. The results demonstrate our method's high performance in error detection and data cleaning experiments, indicating its potential to significantly improve the reliability and accuracy of large-scale production datasets in autonomous driving.
Unconditional Diffusion for Generative Sequential Recommendation
Jul 08, 2025Diffusion models, known for their generative ability to simulate data creation through noise-adding and denoising processes, have emerged as a promising approach for building generative recommenders. To incorporate user history for personalization, existing methods typically adopt a conditional diffusion framework, where the reverse denoising process of reconstructing items from noise is modified to be conditioned on the user history. However, this design may fail to fully utilize historical information, as it gets distracted by the need to model the "item $\leftrightarrow$ noise" translation. This motivates us to reformulate the diffusion process for sequential recommendation in an unconditional manner, treating user history (instead of noise) as the endpoint of the forward diffusion process (i.e., the starting point of the reverse process), rather than as a conditional input. This formulation allows for exclusive focus on modeling the "item $\leftrightarrow$ history" translation. To this end, we introduce Brownian Bridge Diffusion Recommendation (BBDRec). By leveraging a Brownian bridge process, BBDRec enforces a structured noise addition and denoising mechanism, ensuring that the trajectories are constrained towards a specific endpoint -- user history, rather than noise. Extensive experiments demonstrate BBDRec's effectiveness in enhancing sequential recommendation performance. The source code is available at https://github.com/baiyimeng/BBDRec.
AugMapNet: Improving Spatial Latent Structure via BEV Grid Augmentation for Enhanced Vectorized Online HD Map Construction
Mar 17, 2025Autonomous driving requires an understanding of the infrastructure elements, such as lanes and crosswalks. To navigate safely, this understanding must be derived from sensor data in real-time and needs to be represented in vectorized form. Learned Bird's-Eye View (BEV) encoders are commonly used to combine a set of camera images from multiple views into one joint latent BEV grid. Traditionally, from this latent space, an intermediate raster map is predicted, providing dense spatial supervision but requiring post-processing into the desired vectorized form. More recent models directly derive infrastructure elements as polylines using vectorized map decoders, providing instance-level information. Our approach, Augmentation Map Network (AugMapNet), proposes latent BEV grid augmentation, a novel technique that significantly enhances the latent BEV representation. AugMapNet combines vector decoding and dense spatial supervision more effectively than existing architectures while remaining as straightforward to integrate and as generic as auxiliary supervision. Experiments on nuScenes and Argoverse2 datasets demonstrate significant improvements in vectorized map prediction performance up to 13.3% over the StreamMapNet baseline on 60m range and greater improvements on larger ranges. We confirm transferability by applying our method to another baseline and find similar improvements. A detailed analysis of the latent BEV grid confirms a more structured latent space of AugMapNet and shows the value of our novel concept beyond pure performance improvement. The code will be released soon.
Be Aware of the Neighborhood Effect: Modeling Selection Bias under Interference
Apr 30, 2024Selection bias in recommender system arises from the recommendation process of system filtering and the interactive process of user selection. Many previous studies have focused on addressing selection bias to achieve unbiased learning of the prediction model, but ignore the fact that potential outcomes for a given user-item pair may vary with the treatments assigned to other user-item pairs, named neighborhood effect. To fill the gap, this paper formally formulates the neighborhood effect as an interference problem from the perspective of causal inference and introduces a treatment representation to capture the neighborhood effect. On this basis, we propose a novel ideal loss that can be used to deal with selection bias in the presence of neighborhood effect. We further develop two new estimators for estimating the proposed ideal loss. We theoretically establish the connection between the proposed and previous debiasing methods ignoring the neighborhood effect, showing that the proposed methods can achieve unbiased learning when both selection bias and neighborhood effect are present, while the existing methods are biased. Extensive semi-synthetic and real-world experiments are conducted to demonstrate the effectiveness of the proposed methods.
Understanding and Counteracting Feature-Level Bias in Click-Through Rate Prediction
Feb 06, 2024

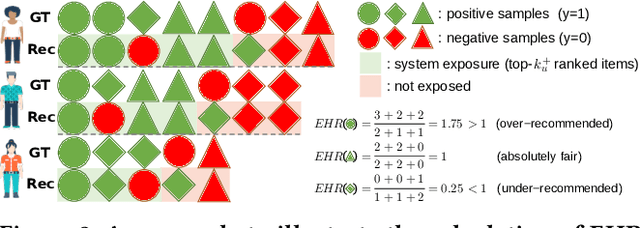
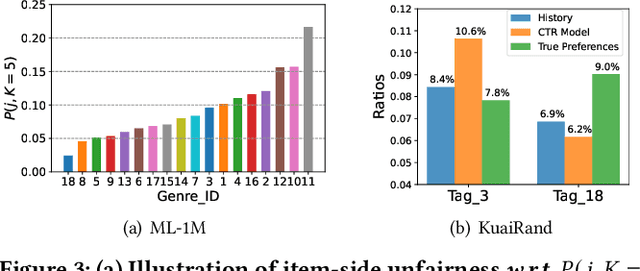
Common click-through rate (CTR) prediction recommender models tend to exhibit feature-level bias, which leads to unfair recommendations among item groups and inaccurate recommendations for users. While existing methods address this issue by adjusting the learning of CTR models, such as through additional optimization objectives, they fail to consider how the bias is caused within these models. To address this research gap, our study performs a top-down analysis on representative CTR models. Through blocking different components of a trained CTR model one by one, we identify the key contribution of the linear component to feature-level bias. We conduct a theoretical analysis of the learning process for the weights in the linear component, revealing how group-wise properties of training data influence them. Our experimental and statistical analyses demonstrate a strong correlation between imbalanced positive sample ratios across item groups and feature-level bias. Based on this understanding, we propose a minimally invasive yet effective strategy to counteract feature-level bias in CTR models by removing the biased linear weights from trained models. Additionally, we present a linear weight adjusting strategy that requires fewer random exposure records than relevant debiasing methods. The superiority of our proposed strategies are validated through extensive experiments on three real-world datasets.
F2BEV: Bird's Eye View Generation from Surround-View Fisheye Camera Images for Automated Driving
Mar 07, 2023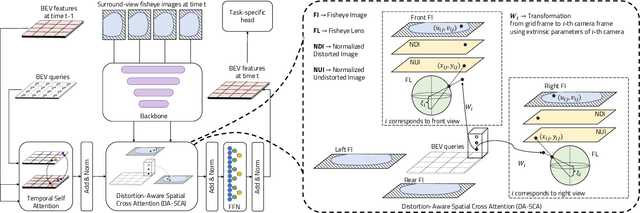



Bird's Eye View (BEV) representations are tremendously useful for perception-related automated driving tasks. However, generating BEVs from surround-view fisheye camera images is challenging due to the strong distortions introduced by such wide-angle lenses. We take the first step in addressing this challenge and introduce a baseline, F2BEV, to generate BEV height maps and semantic segmentation maps from fisheye images. F2BEV consists of a distortion-aware spatial cross attention module for querying and consolidating spatial information from fisheye image features in a transformer-style architecture followed by a task-specific head. We evaluate single-task and multi-task variants of F2BEV on our synthetic FB-SSEM dataset, all of which generate better BEV height and segmentation maps (in terms of the IoU) than a state-of-the-art BEV generation method operating on undistorted fisheye images. We also demonstrate height map generation from real-world fisheye images using F2BEV. An initial sample of our dataset is publicly available at https://tinyurl.com/58jvnscy
Causal Incremental Graph Convolution for Recommender System Retraining
Aug 16, 2021
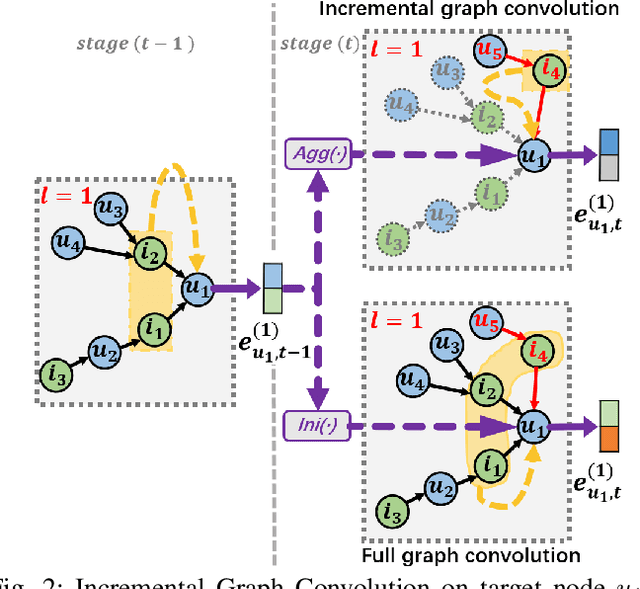

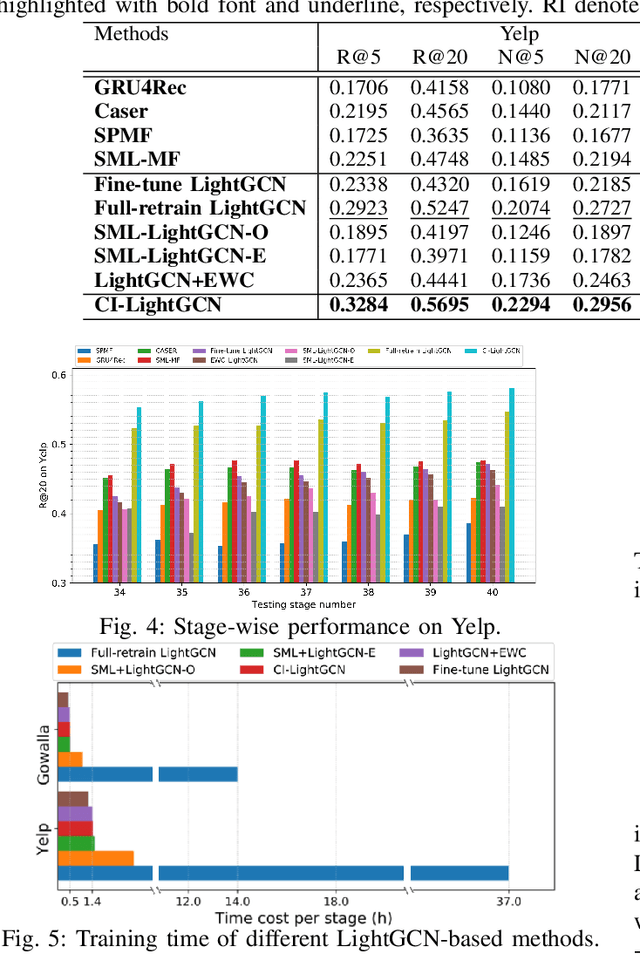
Real-world recommender system needs to be regularly retrained to keep with the new data. In this work, we consider how to efficiently retrain graph convolution network (GCN) based recommender models, which are state-of-the-art techniques for collaborative recommendation. To pursue high efficiency, we set the target as using only new data for model updating, meanwhile not sacrificing the recommendation accuracy compared with full model retraining. This is non-trivial to achieve, since the interaction data participates in both the graph structure for model construction and the loss function for model learning, whereas the old graph structure is not allowed to use in model updating. Towards the goal, we propose a \textit{Causal Incremental Graph Convolution} approach, which consists of two new operators named \textit{Incremental Graph Convolution} (IGC) and \textit{Colliding Effect Distillation} (CED) to estimate the output of full graph convolution. In particular, we devise simple and effective modules for IGC to ingeniously combine the old representations and the incremental graph and effectively fuse the long-term and short-term preference signals. CED aims to avoid the out-of-date issue of inactive nodes that are not in the incremental graph, which connects the new data with inactive nodes through causal inference. In particular, CED estimates the causal effect of new data on the representation of inactive nodes through the control of their collider. Extensive experiments on three real-world datasets demonstrate both accuracy gains and significant speed-ups over the existing retraining mechanism.
Monte Carlo Filtering Objectives: A New Family of Variational Objectives to Learn Generative Model and Neural Adaptive Proposal for Time Series
May 20, 2021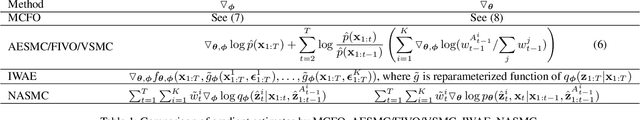
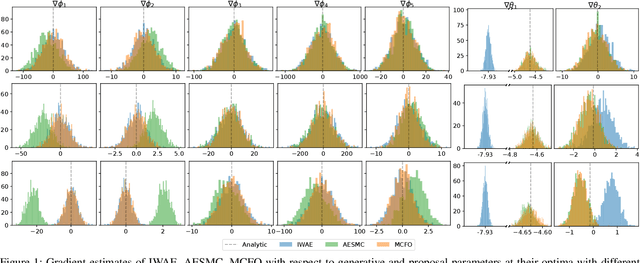
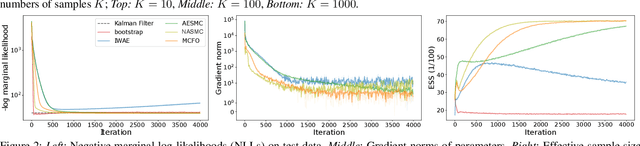
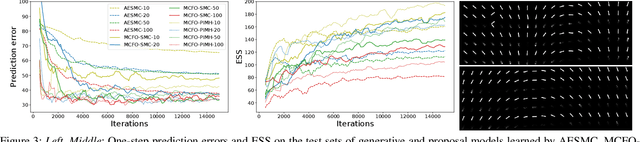
Learning generative models and inferring latent trajectories have shown to be challenging for time series due to the intractable marginal likelihoods of flexible generative models. It can be addressed by surrogate objectives for optimization. We propose Monte Carlo filtering objectives (MCFOs), a family of variational objectives for jointly learning parametric generative models and amortized adaptive importance proposals of time series. MCFOs extend the choices of likelihood estimators beyond Sequential Monte Carlo in state-of-the-art objectives, possess important properties revealing the factors for the tightness of objectives, and allow for less biased and variant gradient estimates. We demonstrate that the proposed MCFOs and gradient estimations lead to efficient and stable model learning, and learned generative models well explain data and importance proposals are more sample efficient on various kinds of time series data.