 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Counteracting Feature-Level Bias in Click-Through Rate Prediction
Paper and Code


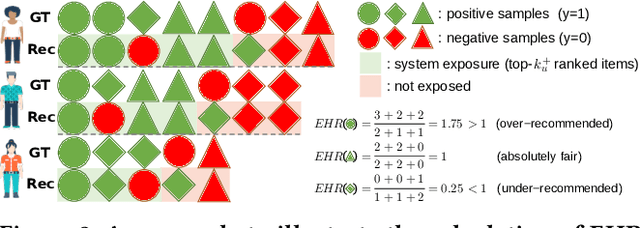
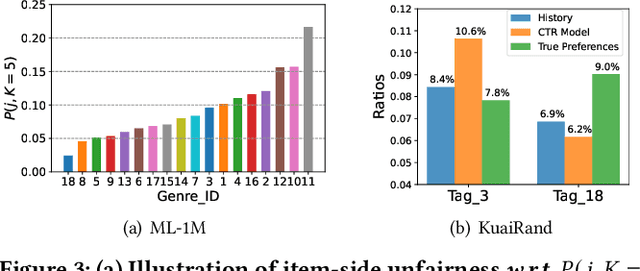
Common click-through rate (CTR) prediction recommender models tend to exhibit feature-level bias, which leads to unfair recommendations among item groups and inaccurate recommendations for users. While existing methods address this issue by adjusting the learning of CTR models, such as through additional optimization objectives, they fail to consider how the bias is caused within these models. To address this research gap, our study performs a top-down analysis on representative CTR models. Through blocking different components of a trained CTR model one by one, we identify the key contribution of the linear component to feature-level bias. We conduct a theoretical analysis of the learning process for the weights in the linear component, revealing how group-wise properties of training data influence them. Our experimental and statistical analyses demonstrate a strong correlation between imbalanced positive sample ratios across item groups and feature-level bias. Based on this understanding, we propose a minimally invasive yet effective strategy to counteract feature-level bias in CTR models by removing the biased linear weights from trained models. Additionally, we present a linear weight adjusting strategy that requires fewer random exposure records than relevant debiasing methods. The superiority of our proposed strategies are validated through extensive experiments on three real-world datasets.