 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSN: A Memory-based Sparse Activation Scaling Framework for Large-scale Industrial Recommendation
Feb 07, 2026Scaling deep learning recommendation models is an effective way to improve model expressiveness. Existing approaches often incur substantial computational overhead, making them difficult to deploy in large-scale industrial systems under strict latency constraints. Recent sparse activation scaling methods, such as Sparse Mixture-of-Experts, reduce computation by activating only a subset of parameters, but still suffer from high memory access costs and limited personalization capacity due to the large size and small number of experts. To address these challenges, we propose MSN, a memory-based sparse activation scaling framework for recommendation models. MSN dynamically retrieves personalized representations from a large parameterized memory and integrates them into downstream feature interaction modules via a memory gating mechanism, enabling fine-grained personalization with low computational overhead. To enable further expansion of the memory capacity while keeping both computational and memory access costs under control, MSN adopts a Product-Key Memory (PKM) mechanism, which factorizes the memory retrieval complexity from linear time to sub-linear complexity. In addition, normalization and over-parameterization techniques are introduced to maintain balanced memory utilization and prevent memory retrieval collapse. We further design customized Sparse-Gather operator and adopt the AirTopK operator to improve training and inference efficiency in industrial settings. Extensive experiments demonstrate that MSN consistently improves recommendation performance while maintaining high efficiency. Moreover, MSN has been successfully deployed in the Douyin Search Ranking System, achieving significant gains over deployed state-of-the-art models in both offline evaluation metrics and large-scale online A/B test.
HyFormer: Revisiting the Roles of Sequence Modeling and Feature Interaction in CTR Prediction
Jan 19, 2026Industrial large-scale recommendation models (LRMs) face the challenge of jointly modeling long-range user behavior sequences and heterogeneous non-sequential features under strict efficiency constraints. However, most existing architectures employ a decoupled pipeline: long sequences are first compressed with a query-token based sequence compressor like LONGER, followed by fusion with dense features through token-mixing modules like RankMixer, which thereby limits both the representation capacity and the interaction flexibility. This paper presents HyFormer, a unified hybrid transformer architecture that tightly integrates long-sequence modeling and feature interaction into a single backbone. From the perspective of sequence modeling, we revisit and redesign query tokens in LRMs, and frame the LRM modeling task as an alternating optimization process that integrates two core components: Query Decoding which expands non-sequential features into Global Tokens and performs long sequence decoding over layer-wise key-value representations of long behavioral sequences; and Query Boosting which enhances cross-query and cross-sequence heterogeneous interactions via efficient token mixing. The two complementary mechanisms are performed iteratively to refine semantic representations across layers. Extensive experiments on billion-scale industrial datasets demonstrate that HyFormer consistently outperforms strong LONGER and RankMixer baselines under comparable parameter and FLOPs budgets, while exhibiting superior scaling behavior with increasing parameters and FLOPs. Large-scale online A/B tests in high-traffic production systems further validate its effectiveness, showing significant gains over deployed state-of-the-art models. These results highlight the practicality and scalability of HyFormer as a unified modeling framework for industrial LRMs.
On the Maximal Local Disparity of Fairness-Aware Classifiers
Jun 05, 2024



Fairness has become a crucial aspect in the development of trustworthy machine learning algorithms. Current fairness metrics to measure the violation of demographic parity have the following drawbacks: (i) the average difference of model predictions on two groups cannot reflect their distribution disparity, and (ii) the overall calculation along all possible predictions conceals the extreme local disparity at or around certain predictions. In this work, we propose a novel fairness metric called Maximal Cumulative ratio Disparity along varying Predictions' neighborhood (MCDP), for measuring the maximal local disparity of the fairness-aware classifiers. To accurately and efficiently calculate the MCDP, we develop a provably exact and an approximate calculation algorithm that greatly reduces the computational complexity with low estimation error. We further propose a bi-level optimization algorithm using a differentiable approximation of the MCDP for improving the algorithmic fairness. Extensive experiments on both tabular and image datasets validate that our fair training algorithm can achieve superior fairness-accuracy trade-offs.
Understanding and Counteracting Feature-Level Bias in Click-Through Rate Prediction
Feb 06, 2024

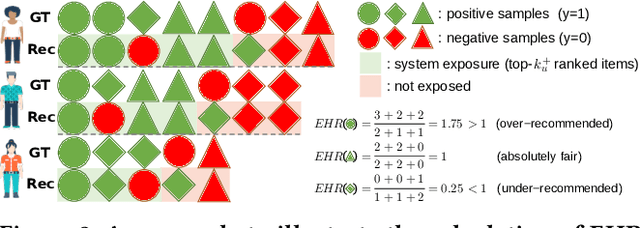
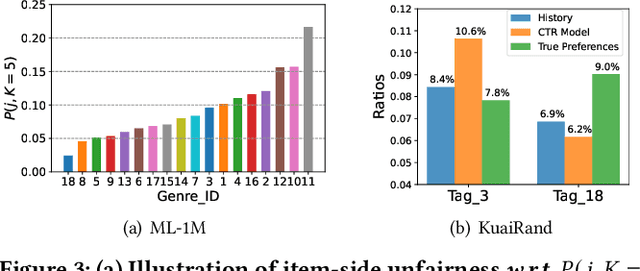
Common click-through rate (CTR) prediction recommender models tend to exhibit feature-level bias, which leads to unfair recommendations among item groups and inaccurate recommendations for users. While existing methods address this issue by adjusting the learning of CTR models, such as through additional optimization objectives, they fail to consider how the bias is caused within these models. To address this research gap, our study performs a top-down analysis on representative CTR models. Through blocking different components of a trained CTR model one by one, we identify the key contribution of the linear component to feature-level bias. We conduct a theoretical analysis of the learning process for the weights in the linear component, revealing how group-wise properties of training data influence them. Our experimental and statistical analyses demonstrate a strong correlation between imbalanced positive sample ratios across item groups and feature-level bias. Based on this understanding, we propose a minimally invasive yet effective strategy to counteract feature-level bias in CTR models by removing the biased linear weights from trained models. Additionally, we present a linear weight adjusting strategy that requires fewer random exposure records than relevant debiasing methods. The superiority of our proposed strategies are validated through extensive experiments on three real-world datasets.