 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoVDC: Automated Vision Data Cleaning Using Vision-Language Models
Jul 16, 2025Training of autonomous driving systems requires extensive datasets with precise annotations to attain robust performance. Human annotations suffer from imperfections, and multiple iterations are often needed to produce high-quality datasets. However, manually reviewing large datasets is laborious and expensive. In this paper, we introduce AutoVDC (Automated Vision Data Cleaning) framework and investigate the utilization of Vision-Language Models (VLMs) to automatically identify erroneous annotations in vision datasets, thereby enabling users to eliminate these errors and enhance data quality. We validate our approach using the KITTI and nuImages datasets, which contain object detection benchmarks for autonomous driving. To test the effectiveness of AutoVDC, we create dataset variants with intentionally injected erroneous annotations and observe the error detection rate of our approach. Additionally, we compare the detection rates using different VLMs and explore the impact of VLM fine-tuning on our pipeline. The results demonstrate our method's high performance in error detection and data cleaning experiments, indicating its potential to significantly improve the reliability and accuracy of large-scale production datasets in autonomous driving.
AugMapNet: Improving Spatial Latent Structure via BEV Grid Augmentation for Enhanced Vectorized Online HD Map Construction
Mar 17, 2025Autonomous driving requires an understanding of the infrastructure elements, such as lanes and crosswalks. To navigate safely, this understanding must be derived from sensor data in real-time and needs to be represented in vectorized form. Learned Bird's-Eye View (BEV) encoders are commonly used to combine a set of camera images from multiple views into one joint latent BEV grid. Traditionally, from this latent space, an intermediate raster map is predicted, providing dense spatial supervision but requiring post-processing into the desired vectorized form. More recent models directly derive infrastructure elements as polylines using vectorized map decoders, providing instance-level information. Our approach, Augmentation Map Network (AugMapNet), proposes latent BEV grid augmentation, a novel technique that significantly enhances the latent BEV representation. AugMapNet combines vector decoding and dense spatial supervision more effectively than existing architectures while remaining as straightforward to integrate and as generic as auxiliary supervision. Experiments on nuScenes and Argoverse2 datasets demonstrate significant improvements in vectorized map prediction performance up to 13.3% over the StreamMapNet baseline on 60m range and greater improvements on larger ranges. We confirm transferability by applying our method to another baseline and find similar improvements. A detailed analysis of the latent BEV grid confirms a more structured latent space of AugMapNet and shows the value of our novel concept beyond pure performance improvement. The code will be released soon.
TempBEV: Improving Learned BEV Encoders with Combined Image and BEV Space Temporal Aggregation
Apr 17, 2024Autonomous driving requires an accurate representation of the environment. A strategy toward high accuracy is to fuse data from several sensors. Learned Bird's-Eye View (BEV) encoders can achieve this by mapping data from individual sensors into one joint latent space. For cost-efficient camera-only systems, this provides an effective mechanism to fuse data from multiple cameras with different views. Accuracy can further be improved by aggregating sensor information over time. This is especially important in monocular camera systems to account for the lack of explicit depth and velocity measurements. Thereby, the effectiveness of developed BEV encoders crucially depends on the operators used to aggregate temporal information and on the used latent representation spaces. We analyze BEV encoders proposed in the literature and compare their effectiveness, quantifying the effects of aggregation operators and latent representations. While most existing approaches aggregate temporal information either in image or in BEV latent space, our analyses and performance comparisons suggest that these latent representations exhibit complementary strengths. Therefore, we develop a novel temporal BEV encoder, TempBEV, which integrates aggregated temporal information from both latent spaces. We consider subsequent image frames as stereo through time and leverage methods from optical flow estimation for temporal stereo encoding. Empirical evaluation on the NuScenes dataset shows a significant improvement by TempBEV over the baseline for 3D object detection and BEV segmentation. The ablation uncovers a strong synergy of joint temporal aggregation in the image and BEV latent space. These results indicate the overall effectiveness of our approach and make a strong case for aggregating temporal information in both image and BEV latent spaces.
Semantic Map Learning of Traffic Light to Lane Assignment based on Motion Data
Sep 28, 2023Understanding which traffic light controls which lane is crucial to navigate intersections safely. Autonomous vehicles commonly rely on High Definition (HD) maps that contain information about the assignment of traffic lights to lanes. The manual provisioning of this information is tedious, expensive, and not scalable. To remedy these issues, our novel approach derives the assignments from traffic light states and the corresponding motion patterns of vehicle traffic. This works in an automated way and independently of the geometric arrangement. We show the effectiveness of basic statistical approaches for this task by implementing and evaluating a pattern-based contribution method. In addition, our novel rejection method includes accompanying safety considerations by leveraging statistical hypothesis testing. Finally, we propose a dataset transformation to re-purpose available motion prediction datasets for semantic map learning. Our publicly available API for the Lyft Level 5 dataset enables researchers to develop and evaluate their own approaches.
LMR: Lane Distance-Based Metric for Trajectory Prediction
Apr 13, 2023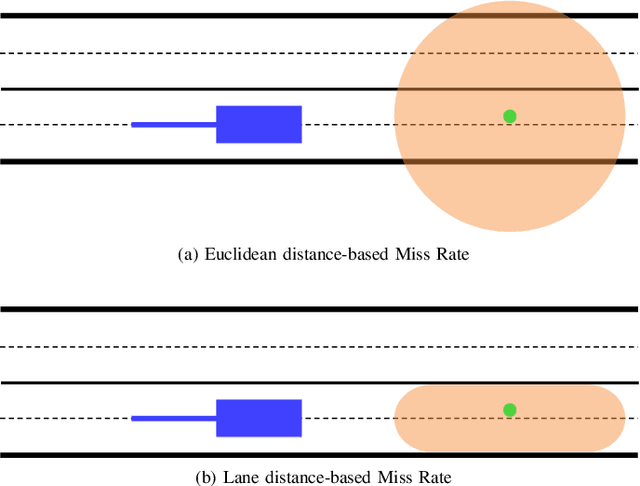

The development of approaches for trajectory prediction requires metrics to validate and compare their performance. Currently established metrics are based on Euclidean distance, which means that errors are weighted equally in all directions. Euclidean metrics are insufficient for structured environments like roads, since they do not properly capture the agent's intent relative to the underlying lane. In order to provide a reasonable assessment of trajectory prediction approaches with regard to the downstream planning task, we propose a new metric that is lane distance-based: Lane Miss Rate (LMR). For the calculation of LMR, the ground-truth and predicted endpoints are assigned to lane segments, more precisely their centerlines. Measured by the distance along the lane segments, predictions that are within a certain threshold distance to the ground-truth count as hits, otherwise they count as misses. LMR is then defined as the ratio of sequences that yield a miss. Our results on three state-of-the-art trajectory prediction models show that LMR preserves the order of Euclidean distance-based metrics. In contrast to the Euclidean Miss Rate, qualitative results show that LMR yields misses for sequences where predictions are located on wrong lanes. Hits on the other hand result for sequences where predictions are located on the correct lane. This means that LMR implicitly weights Euclidean error relative to the lane and goes into the direction of capturing intents of traffic agents. The source code of LMR for Argoverse 2 is publicly available.
Exploring Navigation Maps for Learning-Based Motion Prediction
Feb 13, 2023The prediction of surrounding agents' motion is a key for safe autonomous driving. In this paper, we explore navigation maps as an alternative to the predominant High Definition (HD) maps for learning-based motion prediction. Navigation maps provide topological and geometrical information on road-level, HD maps additionally have centimeter-accurate lane-level information. As a result, HD maps are costly and time-consuming to obtain, while navigation maps with near-global coverage are freely available. We describe an approach to integrate navigation maps into learning-based motion prediction models. To exploit locally available HD maps during training, we additionally propose a model-agnostic method for knowledge distillation. In experiments on the publicly available Argoverse dataset with navigation maps obtained from OpenStreetMap, our approach shows a significant improvement over not using a map at all. Combined with our method for knowledge distillation, we achieve results that are close to the original HD map-reliant models. Our publicly available navigation map API for Argoverse enables researchers to develop and evaluate their own approaches using navigation maps.
SCENE: Reasoning about Traffic Scenes using Heterogeneous Graph Neural Networks
Jan 09, 2023Understanding traffic scenes requires considering heterogeneous information about dynamic agents and the static infrastructure. In this work we propose SCENE, a methodology to encode diverse traffic scenes in heterogeneous graphs and to reason about these graphs using a heterogeneous Graph Neural Network encoder and task-specific decoders. The heterogeneous graphs, whose structures are defined by an ontology, consist of different nodes with type-specific node features and different relations with type-specific edge features. In order to exploit all the information given by these graphs, we propose to use cascaded layers of graph convolution. The result is an encoding of the scene. Task-specific decoders can be applied to predict desired attributes of the scene. Extensive evaluation on two diverse binary node classification tasks show the main strength of this methodology: despite being generic, it even manages to outperform task-specific baselines. The further application of our methodology to the task of node classification in various knowledge graphs shows its transferability to other domains.
* Thomas Monninger and Julian Schmidt are co-first authors. The order was determined alphabetically